 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Learning Meets Directed Acyclic Graph for Multimodal Emotion Recognition
Mar 08, 2024



Emotion recognition in conversation (ERC) is a crucial task in natural language processing and affective computing. This paper proposes MultiDAG+CL, a novel approach for Multimodal Emotion Recognition in Conversation (ERC) that employs Directed Acyclic Graph (DAG) to integrate textual, acoustic, and visual features within a unified framework. The model is enhanced by Curriculum Learning (CL) to address challenges related to emotional shifts and data imbalance. Curriculum learning facilitates the learning process by gradually presenting training samples in a meaningful order, thereby improving the model's performance in handling emotional variations and data imbalance. Experimental results on the IEMOCAP and MELD datasets demonstrate that the MultiDAG+CL models outperform baseline models. We release the code for MultiDAG+CL and experiments: https://github.com/vanntc711/MultiDAG-CL
KTVIC: A Vietnamese Image Captioning Dataset on the Life Domain
Jan 16, 2024Image captioning is a crucial task with applications in a wide range of domains, including healthcare and education. Despite extensive research on English image captioning datasets, the availability of such datasets for Vietnamese remains limited, with only two existing datasets. In this study, we introduce KTVIC, a comprehensive Vietnamese Image Captioning dataset focused on the life domain, covering a wide range of daily activities. This dataset comprises 4,327 images and 21,635 Vietnamese captions, serving as a valuable resource for advancing image captioning in the Vietnamese language. We conduct experiments using various deep neural networks as the baselines on our dataset, evaluating them using the standard image captioning metrics, including BLEU, METEOR, CIDEr, and ROUGE. Our findings underscore the effectiveness of the proposed dataset and its potential contributions to the field of image captioning in the Vietnamese context.
Solving Label Variation in Scientific Information Extraction via Multi-Task Learning
Dec 25, 2023
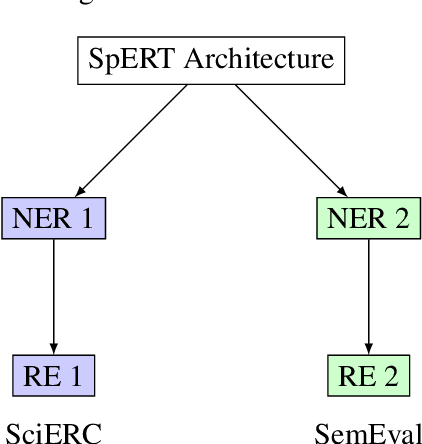


Scientific Information Extraction (ScientificIE) is a critical task that involves the identification of scientific entities and their relationships. The complexity of this task is compounded by the necessity for domain-specific knowledge and the limited availability of annotated data. Two of the most popular datasets for ScientificIE are SemEval-2018 Task-7 and SciERC. They have overlapping samples and differ in their annotation schemes, which leads to conflicts. In this study, we first introduced a novel approach based on multi-task learning to address label variations. We then proposed a soft labeling technique that converts inconsistent labels into probabilistic distributions. The experimental results demonstrated that the proposed method can enhance the model robustness to label noise and improve the end-to-end performance in both ScientificIE tasks. The analysis revealed that label variations can be particularly effective in handling ambiguous instances. Furthermore, the richness of the information captured by label variations can potentially reduce data size requirements. The findings highlight the importance of releasing variation labels and promote future research on other tasks in other domains. Overall, this study demonstrates the effectiveness of multi-task learning and the potential of label variations to enhance the performance of ScientificIE.
Self-MI: Efficient Multimodal Fusion via Self-Supervised Multi-Task Learning with Auxiliary Mutual Information Maximization
Nov 07, 2023



Multimodal representation learning poses significant challenges in capturing informative and distinct features from multiple modalities. Existing methods often struggle to exploit the unique characteristics of each modality due to unified multimodal annotations. In this study, we propose Self-MI in the self-supervised learning fashion, which also leverage Contrastive Predictive Coding (CPC) as an auxiliary technique to maximize the Mutual Information (MI) between unimodal input pairs and the multimodal fusion result with unimodal inputs. Moreover, we design a label generation module, $ULG_{MI}$ for short, that enables us to create meaningful and informative labels for each modality in a self-supervised manner. By maximizing the Mutual Information, we encourage better alignment between the multimodal fusion and the individual modalities, facilitating improved multimodal fusion. Extensive experiments on three benchmark datasets including CMU-MOSI, CMU-MOSEI, and SIMS, demonstrate the effectiveness of Self-MI in enhancing the multimodal fusion task.