 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Self-Paced Curriculum Learning for Enhanced Modality Balance in Multimodal Conversational Emotion Recognition
May 20, 2026Multimodal Emotion Recognition in Conversations (MERC) is a crucial task for understanding human interactions, where multimodal approaches integrating language, facial expressions, and vocal tone have achieved significant progress. However, modality misalignment and imbalanced learning remain major challenges, limiting the effective utilization of multimodal information. To address this issue, we propose a plug-and-play framework based on Self-Paced Curriculum Learning (SPCL) for MERC. We introduce a dual-level Difficulty Measurer that captures both utterance-level and conversation-level challenges. The utterance-level score models fine-grained modality-specific difficulty, while the conversation-level score captures broader dialogue structures, including emotional dependencies and modality coherence. Based on these scores, the Learning Scheduler dynamically guides training from easier to more difficult instances. By integrating SPCL into existing MERC architectures, our method alleviates modality imbalance and improves model robustness. Extensive experiments on the IEMOCAP and MELD datasets demonstrate consistent improvements across different architectures and modality settings. On IEMOCAP, SPCL improves weighted F1-score by approximately +1.2% to +6.6% over baseline models, while on MELD, gains reach up to +10.4%. These results highlight the effectiveness and generalizability of SPCL as a lightweight plug-and-play module for multimodal emotion recognition.
From Top-1 to Top-K: A Reproducibility Study and Benchmarking of Counterfactual Explanations for Recommender Systems
Apr 21, 2026Counterfactual explanations (CEs) provide an intuitive way to understand recommender systems by identifying minimal modifications to user-item interactions that alter recommendation outcomes. Existing CE methods for recommender systems, however, have been evaluated under heterogeneous protocols, using different datasets, recommenders, metrics, and even explanation formats, which hampers reproducibility and fair comparison. Our paper systematically reproduces, re-implement, and re-evaluate eleven state-of-the-art CE methods for recommender systems, covering both native explainers (e.g., LIME-RS, SHAP, PRINCE, ACCENT, LXR, GREASE) and specific graph-based explainers originally proposed for GNNs. Here, a unified benchmarking framework is proposed to assess explainers along three dimensions: explanation format (implicit vs. explicit), evaluation level (item-level vs. list-level), and perturbation scope (user interaction vectors vs. user-item interaction graphs). Our evaluation protocol includes effectiveness, sparsity, and computational complexity metrics, and extends existing item-level assessments to top-K list-level explanations. Through extensive experiments on three real-world datasets and six representative recommender models, we analyze how well previously reported strengths of CE methods generalize across diverse setups. We observe that the trade-off between effectiveness and sparsity depends strongly on the specific method and evaluation setting, particularly under the explicit format; in addition, explainer performance remains largely consistent across item level and list level evaluations, and several graph-based explainers exhibit notable scalability limitations on large recommender graphs. Our results refine and challenge earlier conclusions about the robustness and practicality of CE generation methods in recommender systems: https://github.com/L2R-UET/CFExpRec.
BALM: A Model-Agnostic Framework for Balanced Multimodal Learning under Imbalanced Missing Rates
Mar 20, 2026Learning from multiple modalities often suffers from imbalance, where information-rich modalities dominate optimization while weaker or partially missing modalities contribute less. This imbalance becomes severe in realistic settings with imbalanced missing rates (IMR), where each modality is absent with different probabilities, distorting representation learning and gradient dynamics. We revisit this issue from a training-process perspective and propose BALM, a model-agnostic plug-in framework to achieve balanced multimodal learning under IMR. The framework comprises two complementary modules: the Feature Calibration Module (FCM), which recalibrates unimodal features using global context to establish a shared representation basis across heterogeneous missing patterns; the Gradient Rebalancing Module (GRM), which balances learning dynamics across modalities by modulating gradient magnitudes and directions from both distributional and spatial perspectives. BALM can be seamlessly integrated into diverse backbones, including multimodal emotion recognition (MER) models, without altering their architectures. Experimental results across multiple MER benchmarks confirm that BALM consistently enhances robustness and improves performance under diverse missing and imbalance settings. Code available at: https://github.com/np4s/BALM_CVPR2026.git
MissBench: Benchmarking Multimodal Affective Analysis under Imbalanced Missing Modalities
Mar 10, 2026Multimodal affective computing underpins key tasks such as sentiment analysis and emotion recognition. Standard evaluations, however, often assume that textual, acoustic, and visual modalities are equally available. In real applications, some modalities are systematically more fragile or expensive, creating imbalanced missing rates and training biases that task-level metrics alone do not reveal. We introduce MissBench, a benchmark and framework for multimodal affective tasks that standardizes both shared and imbalanced missing-rate protocols on four widely used sentiment and emotion datasets. MissBench also defines two diagnostic metrics. The Modality Equity Index (MEI) measures how fairly different modalities contribute across missing-modality configurations. The Modality Learning Index (MLI) quantifies optimization imbalance by comparing modality-specific gradient norms during training, aggregated across modality-related modules. Experiments on representative method families show that models that appear robust under shared missing rates can still exhibit marked modality inequity and optimization imbalance under imbalanced conditions. These findings position MissBench, together with MEI and MLI, as practical tools for stress-testing and analyzing multimodal affective models in realistic incomplete-modality settings.For reproducibility, we release our code at: https://anonymous.4open.science/r/MissBench-4098/
Counterfactual Understanding via Retrieval-aware Multimodal Modeling for Time-to-Event Survival Prediction
Feb 23, 2026This paper tackles the problem of time-to-event counterfactual survival prediction, aiming to optimize individualized survival outcomes in the presence of heterogeneity and censored data. We propose CURE, a framework that advances counterfactual survival modeling via comprehensive multimodal embedding and latent subgroup retrieval. CURE integrates clinical, paraclinical, demographic, and multi-omics information, which are aligned and fused through cross-attention mechanisms. Complex multi-omics signals can be adaptively refined using a mixture-of-experts architecture, emphasizing the most informative omics components. Building upon this representation, CURE implicitly retrieves patient-specific latent subgroups that capture both baseline survival dynamics and treatment-dependent variations. Experimental results on METABRIC and TCGA-LUAD datasets demonstrate that proposed CURE model consistently outperforms strong baselines in survival analysis, evaluated using the Time-dependent Concordance Index ($C^{td}$) and Integrated Brier Score (IBS). These findings highlight the potential of CURE to enhance multimodal understanding and serve as a foundation for future treatment recommendation models. All code and related resources are publicly available to facilitate the reproducibility https://github.com/L2R-UET/CURE.
Agentic Design Patterns: A System-Theoretic Framework
Jan 27, 2026With the development of foundation model (FM), agentic AI systems are getting more attention, yet their inherent issues like hallucination and poor reasoning, coupled with the frequent ad-hoc nature of system design, lead to unreliable and brittle applications. Existing efforts to characterise agentic design patterns often lack a rigorous systems-theoretic foundation, resulting in high-level or convenience-based taxonomies that are difficult to implement. This paper addresses this gap by introducing a principled methodology for engineering robust AI agents. We propose two primary contributions: first, a novel system-theoretic framework that deconstructs an agentic AI system into five core, interacting functional subsystems: Reasoning & World Model, Perception & Grounding, Action Execution, Learning & Adaptation, and Inter-Agent Communication. Second, derived from this architecture and directly mapped to a comprehensive taxonomy of agentic challenges, we present a collection of 12 agentic design patterns. These patterns - categorised as Foundational, Cognitive & Decisional, Execution & Interaction, and Adaptive & Learning - offer reusable, structural solutions to recurring problems in agent design. The utility of the framework is demonstrated by a case study on the ReAct framework, showing how the proposed patterns can rectify systemic architectural deficiencies. This work provides a foundational language and a structured methodology to standardise agentic design communication among researchers and engineers, leading to more modular, understandable, and reliable autonomous systems.
CLEAR: Causal Learning Framework For Robust Histopathology Tumor Detection Under Out-Of-Distribution Shifts
Oct 16, 2025Domain shift in histopathology, often caused by differences in acquisition processes or data sources, poses a major challenge to the generalization ability of deep learning models. Existing methods primarily rely on modeling statistical correlations by aligning feature distributions or introducing statistical variation, yet they often overlook causal relationships. In this work, we propose a novel causal-inference-based framework that leverages semantic features while mitigating the impact of confounders. Our method implements the front-door principle by designing transformation strategies that explicitly incorporate mediators and observed tissue slides. We validate our method on the CAMELYON17 dataset and a private histopathology dataset, demonstrating consistent performance gains across unseen domains. As a result, our approach achieved up to a 7% improvement in both the CAMELYON17 dataset and the private histopathology dataset, outperforming existing baselines. These results highlight the potential of causal inference as a powerful tool for addressing domain shift in histopathology image analysis.
Multi-modal Adaptive Mixture of Experts for Cold-start Recommendation
Aug 11, 2025



Recommendation systems have faced significant challenges in cold-start scenarios, where new items with a limited history of interaction need to be effectively recommended to users. Though multimodal data (e.g., images, text, audio, etc.) offer rich information to address this issue, existing approaches often employ simplistic integration methods such as concatenation, average pooling, or fixed weighting schemes, which fail to capture the complex relationships between modalities. Our study proposes a novel Mixture of Experts (MoE) framework for multimodal cold-start recommendation, named MAMEX, which dynamically leverages latent representation from different modalities. MAMEX utilizes modality-specific expert networks and introduces a learnable gating mechanism that adaptively weights the contribution of each modality based on its content characteristics. This approach enables MAMEX to emphasize the most informative modalities for each item while maintaining robustness when certain modalities are less relevant or missing. Extensive experiments on benchmark datasets show that MAMEX outperforms state-of-the-art methods in cold-start scenarios, with superior accuracy and adaptability. For reproducibility, the code has been made available on Github https://github.com/L2R-UET/MAMEX.
Personalized Diffusion Model Reshapes Cold-Start Bundle Recommendation
May 20, 2025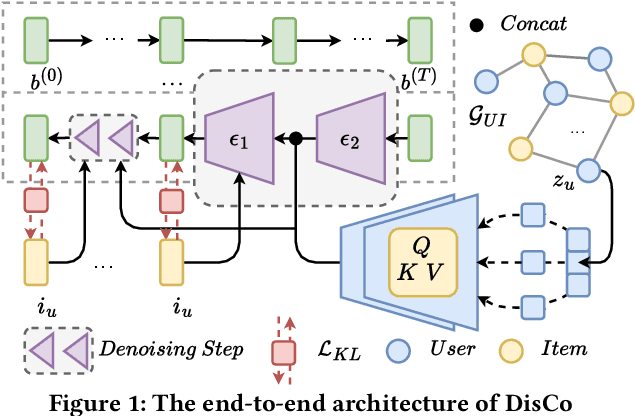
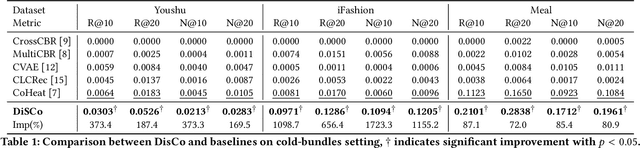
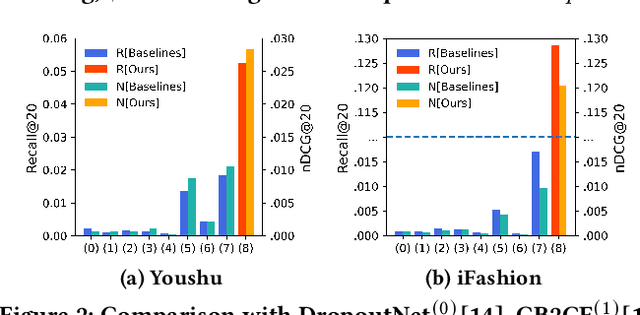
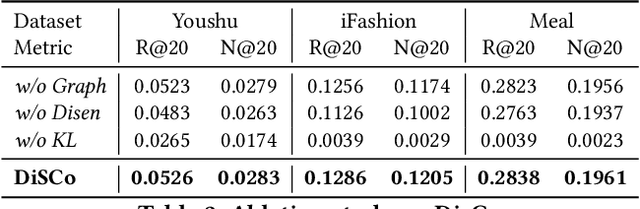
Bundle recommendation aims to recommend a set of items to each user. However, the sparser interactions between users and bundles raise a big challenge, especially in cold-start scenarios. Traditional collaborative filtering methods do not work well for this kind of problem because these models rely on interactions to update the latent embedding, which is hard to work in a cold-start setting. We propose a new approach (DisCo), which relies on a personalized Diffusion backbone, enhanced by disentangled aspects for the user's interest, to generate a bundle in distribution space for each user to tackle the cold-start challenge. During the training phase, DisCo adjusts an additional objective loss term to avoid bias, a prevalent issue while using the generative model for top-$K$ recommendation purposes. Our empirical experiments show that DisCo outperforms five comparative baselines by a large margin on three real-world datasets. Thereby, this study devises a promising framework and essential viewpoints in cold-start recommendation. Our materials for reproducibility are available at: https://github.com/bt-nghia/DisCo.
BRIDGE: Bundle Recommendation via Instruction-Driven Generation
Dec 24, 2024Bundle recommendation aims to suggest a set of interconnected items to users. However, diverse interaction types and sparse interaction matrices often pose challenges for previous approaches in accurately predicting user-bundle adoptions. Inspired by the distant supervision strategy and generative paradigm, we propose BRIDGE, a novel framework for bundle recommendation. It consists of two main components namely the correlation-based item clustering and the pseudo bundle generation modules. Inspired by the distant supervision approach, the former is to generate more auxiliary information, e.g., instructive item clusters, for training without using external data. This information is subsequently aggregated with collaborative signals from user historical interactions to create pseudo `ideal' bundles. This capability allows BRIDGE to explore all aspects of bundles, rather than being limited to existing real-world bundles. It effectively bridging the gap between user imagination and predefined bundles, hence improving the bundle recommendation performance. Experimental results validate the superiority of our models over state-of-the-art ranking-based methods across five benchmark datasets.