 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Design Patterns: A System-Theoretic Framework
Jan 27, 2026With the development of foundation model (FM), agentic AI systems are getting more attention, yet their inherent issues like hallucination and poor reasoning, coupled with the frequent ad-hoc nature of system design, lead to unreliable and brittle applications. Existing efforts to characterise agentic design patterns often lack a rigorous systems-theoretic foundation, resulting in high-level or convenience-based taxonomies that are difficult to implement. This paper addresses this gap by introducing a principled methodology for engineering robust AI agents. We propose two primary contributions: first, a novel system-theoretic framework that deconstructs an agentic AI system into five core, interacting functional subsystems: Reasoning & World Model, Perception & Grounding, Action Execution, Learning & Adaptation, and Inter-Agent Communication. Second, derived from this architecture and directly mapped to a comprehensive taxonomy of agentic challenges, we present a collection of 12 agentic design patterns. These patterns - categorised as Foundational, Cognitive & Decisional, Execution & Interaction, and Adaptive & Learning - offer reusable, structural solutions to recurring problems in agent design. The utility of the framework is demonstrated by a case study on the ReAct framework, showing how the proposed patterns can rectify systemic architectural deficiencies. This work provides a foundational language and a structured methodology to standardise agentic design communication among researchers and engineers, leading to more modular, understandable, and reliable autonomous systems.
Questionnaire meets LLM: A Benchmark and Empirical Study of Structural Skills for Understanding Questions and Responses
Oct 30, 2025Millions of people take surveys every day, from market polls and academic studies to medical questionnaires and customer feedback forms. These datasets capture valuable insights, but their scale and structure present a unique challenge for large language models (LLMs), which otherwise excel at few-shot reasoning over open-ended text. Yet, their ability to process questionnaire data or lists of questions crossed with hundreds of respondent rows remains underexplored. Current retrieval and survey analysis tools (e.g., Qualtrics, SPSS, REDCap) are typically designed for humans in the workflow, limiting such data integration with LLM and AI-empowered automation. This gap leaves scientists, surveyors, and everyday users without evidence-based guidance on how to best represent questionnaires for LLM consumption. We address this by introducing QASU (Questionnaire Analysis and Structural Understanding), a benchmark that probes six structural skills, including answer lookup, respondent count, and multi-hop inference, across six serialization formats and multiple prompt strategies. Experiments on contemporary LLMs show that choosing an effective format and prompt combination can improve accuracy by up to 8.8% points compared to suboptimal formats. For specific tasks, carefully adding a lightweight structural hint through self-augmented prompting can yield further improvements of 3-4% points on average. By systematically isolating format and prompting effects, our open source benchmark offers a simple yet versatile foundation for advancing both research and real-world practice in LLM-based questionnaire analysis.
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Jan 10, 2025With recent advances in Large Language Models (LLMs), Agentic AI has become phenomenal in real-world applications, moving toward multiple LLM-based agents to perceive, learn, reason, and act collaboratively. These LLM-based Multi-Agent Systems (MASs) enable groups of intelligent agents to coordinate and solve complex tasks collectively at scale, transitioning from isolated models to collaboration-centric approaches. This work provides an extensive survey of the collaborative aspect of MASs and introduces an extensible framework to guide future research. Our framework characterizes collaboration mechanisms based on key dimensions: actors (agents involved), types (e.g., cooperation, competition, or coopetition), structures (e.g., peer-to-peer, centralized, or distributed), strategies (e.g., role-based or model-based), and coordination protocols. Through a review of existing methodologies, our findings serve as a foundation for demystifying and advancing LLM-based MASs toward more intelligent and collaborative solutions for complex, real-world use cases. In addition, various applications of MASs across diverse domains, including 5G/6G networks, Industry 5.0, question answering, and social and cultural settings, are also investigated, demonstrating their wider adoption and broader impacts. Finally, we identify key lessons learned, open challenges, and potential research directions of MASs towards artificial collective intelligence.
Drone-based AI and 3D Reconstruction for Digital Twin Augmentation
May 20, 2021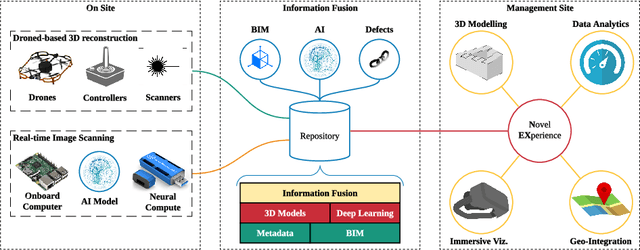



Digital Twin is an emerging technology at the forefront of Industry 4.0, with the ultimate goal of combining the physical space and the virtual space. To date, the Digital Twin concept has been applied in many engineering fields, providing useful insights in the areas of engineering design, manufacturing, automation, and construction industry. While the nexus of various technologies opens up new opportunities with Digital Twin, the technology requires a framework to integrate the different technologies, such as the Building Information Model used in the Building and Construction industry. In this work, an Information Fusion framework is proposed to seamlessly fuse heterogeneous components in a Digital Twin framework from the variety of technologies involved. This study aims to augment Digital Twin in buildings with the use of AI and 3D reconstruction empowered by unmanned aviation vehicles. We proposed a drone-based Digital Twin augmentation framework with reusable and customisable components. A proof of concept is also developed, and extensive evaluation is conducted for 3D reconstruction and applications of AI for defect detection.
Designing AI-based Conversational Agent for Diabetes Care in a Multilingual Context
May 20, 2021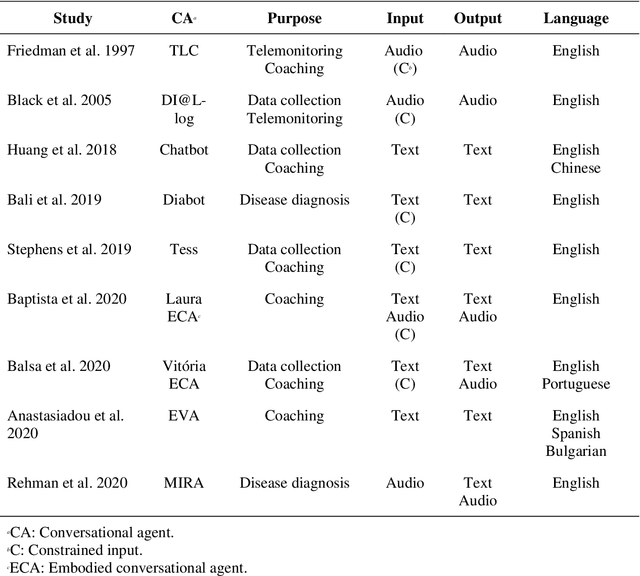
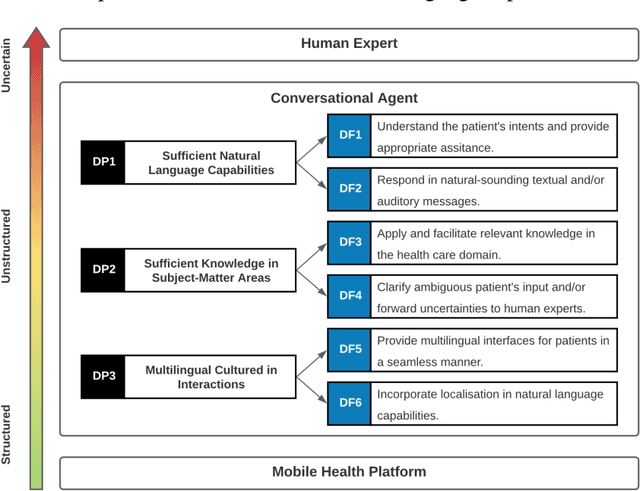
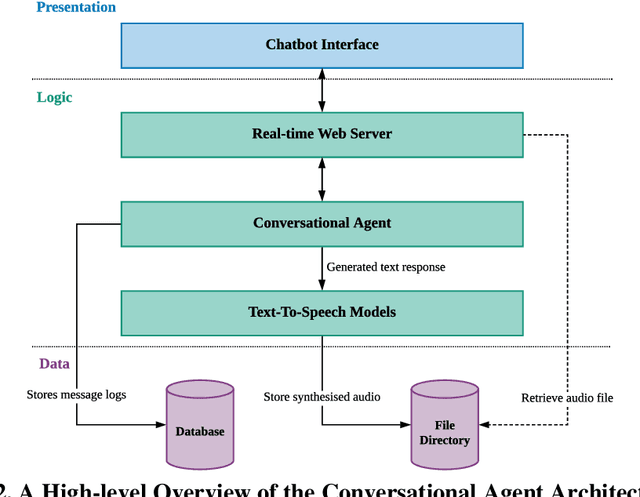
Conversational agents (CAs) represent an emerging research field in health information systems, where there are great potentials in empowering patients with timely information and natural language interfaces. Nevertheless, there have been limited attempts in establishing prescriptive knowledge on designing CAs in the healthcare domain in general, and diabetes care specifically. In this paper, we conducted a Design Science Research project and proposed three design principles for designing health-related CAs that embark on artificial intelligence (AI) to address the limitations of existing solutions. Further, we instantiated the proposed design and developed AMANDA - an AI-based multilingual CA in diabetes care with state-of-the-art technologies for natural-sounding localised accent. We employed mean opinion scores and system usability scale to evaluate AMANDA's speech quality and usability, respectively. This paper provides practitioners with a blueprint for designing CAs in diabetes care with concrete design guidelines that can be extended into other healthcare domains.
Social Behaviour Understanding using Deep Neural Networks: Development of Social Intelligence Systems
May 20, 2021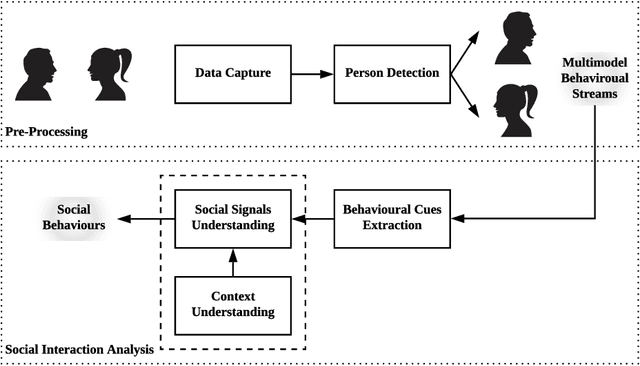
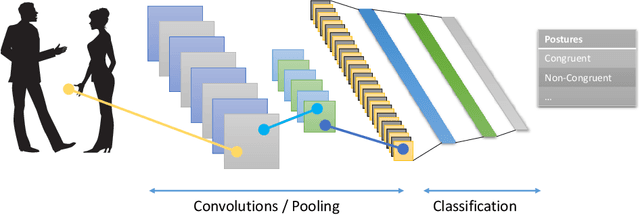
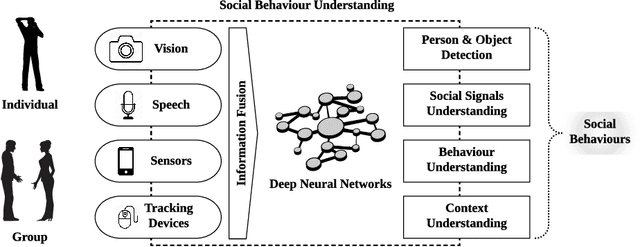
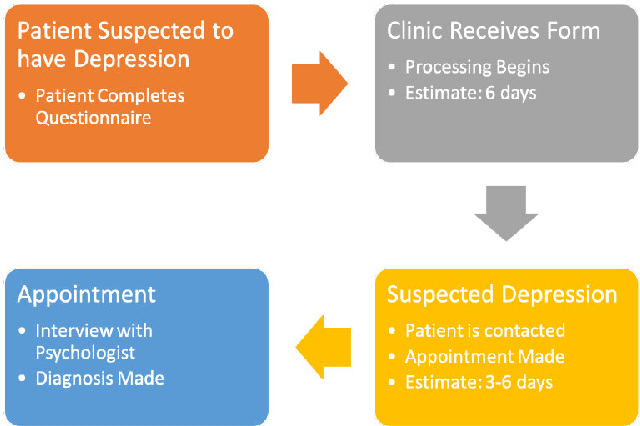
With the rapid development in artificial intelligence, social computing has evolved beyond social informatics toward the birth of social intelligence systems. This paper, therefore, takes initiatives to propose a social behaviour understanding framework with the use of deep neural networks for social and behavioural analysis. The integration of information fusion, person and object detection, social signal understanding, behaviour understanding, and context understanding plays a harmonious role to elicit social behaviours. Three systems, including depression detection, activity recognition and cognitive impairment screening, are developed to evidently demonstrate the importance of social intelligence. The study considerably contributes to the cumulative development of social computing and health informatics. It also provides a number of implications for academic bodies, healthcare practitioners, and developers of socially intelligent agents.
Federated Artificial Intelligence for Unified Credit Assessment
May 20, 2021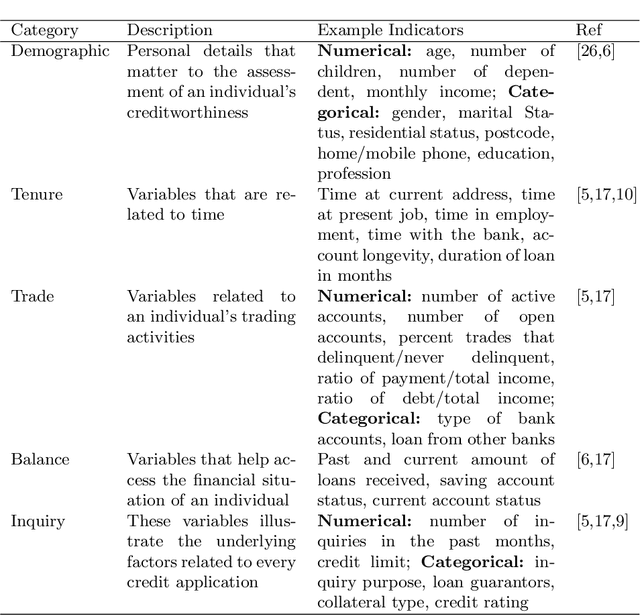
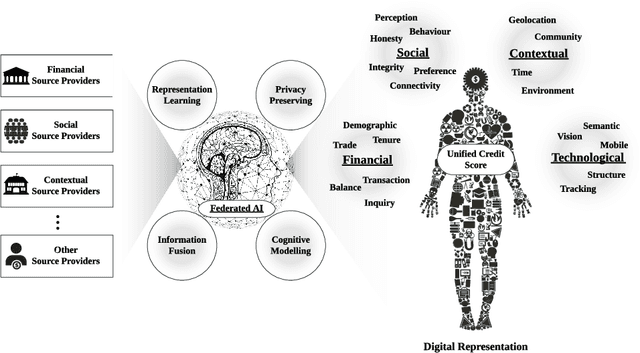
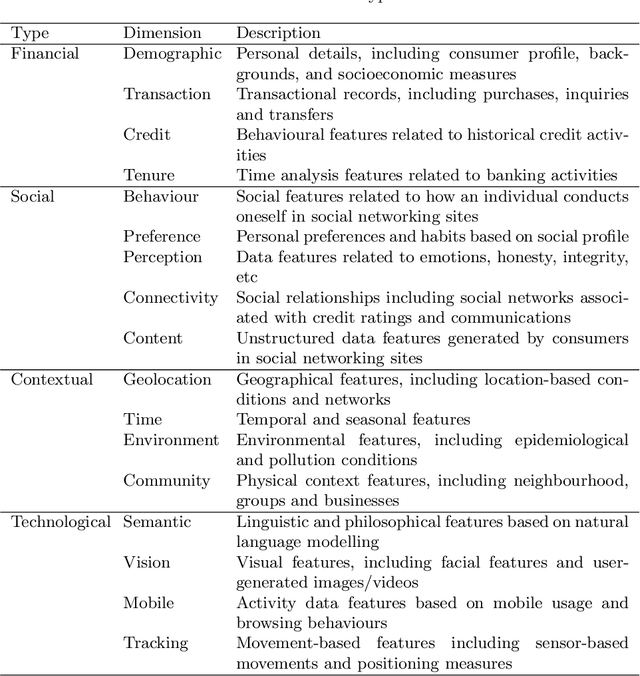
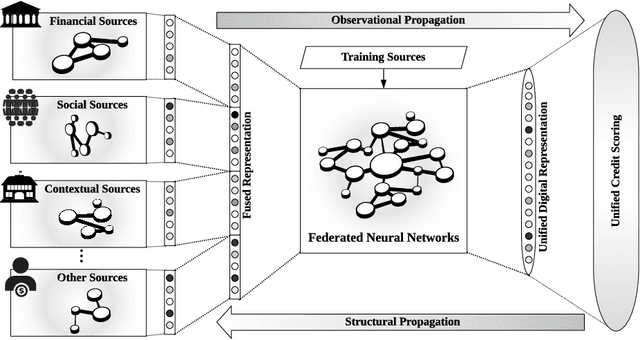
With the rapid adoption of Internet technologies, digital footprints have become ubiquitous and versatile to revolutionise the financial industry in digital transformation. This paper takes initiatives to investigate a new paradigm of the unified credit assessment with the use of federated artificial intelligence. We conceptualised digital human representation which consists of social, contextual, financial and technological dimensions to assess the commercial creditworthiness and social reputation of both banked and unbanked individuals. A federated artificial intelligence platform is proposed with a comprehensive set of system design for efficient and effective credit scoring. The study considerably contributes to the cumulative development of financial intelligence and social computing. It also provides a number of implications for academic bodies, practitioners, and developers of financial technologies.
ReINTEL: A Multimodal Data Challenge for Responsible Information Identification on Social Network Sites
Dec 16, 2020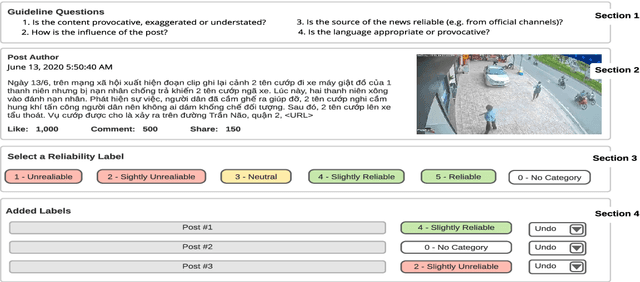
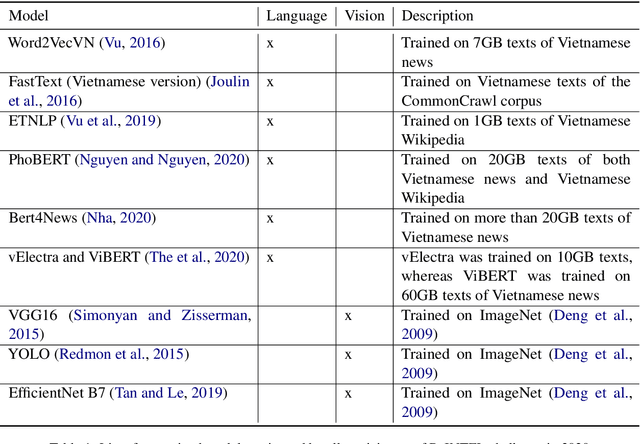
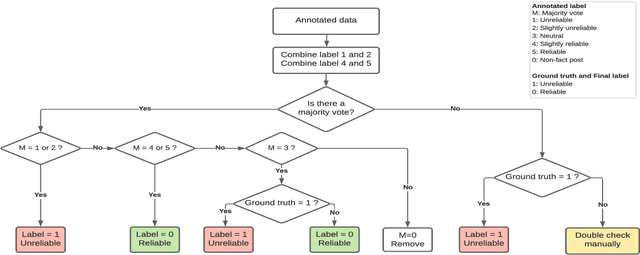

This paper reports on the ReINTEL Shared Task for Responsible Information Identification on social network sites, which is hosted at the seventh annual workshop on Vietnamese Language and Speech Processing (VLSP 2020). Given a piece of news with respective textual, visual content and metadata, participants are required to classify whether the news is `reliable' or `unreliable'. In order to generate a fair benchmark, we introduce a novel human-annotated dataset of over 10,000 news collected from a social network in Vietnam. All models will be evaluated in terms of AUC-ROC score, a typical evaluation metric for classification. The competition was run on the Codalab platform. Within two months, the challenge has attracted over 60 participants and recorded nearly 1,000 submission entries.
Reinforced Data Sampling for Model Diversification
Jun 12, 2020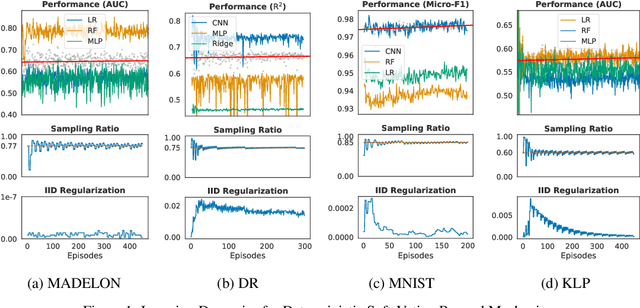
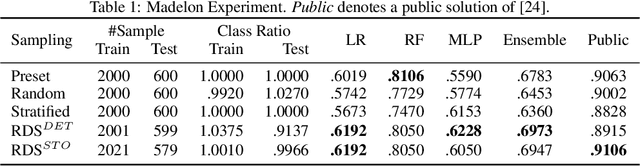
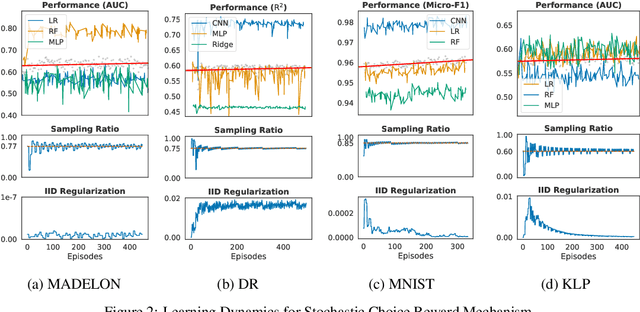
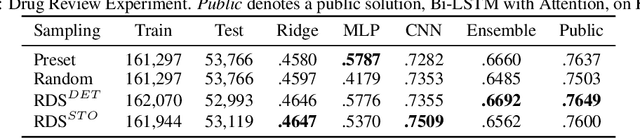
With the rising number of machine learning competitions, the world has witnessed an exciting race for the best algorithms. However, the involved data selection process may fundamentally suffer from evidence ambiguity and concept drift issues, thereby possibly leading to deleterious effects on the performance of various models. This paper proposes a new Reinforced Data Sampling (RDS) method to learn how to sample data adequately on the search for useful models and insights. We formulate the optimisation problem of model diversification $\delta{-div}$ in data sampling to maximise learning potentials and optimum allocation by injecting model diversity. This work advocates the employment of diverse base learners as value functions such as neural networks, decision trees, or logistic regressions to reinforce the selection process of data subsets with multi-modal belief. We introduce different ensemble reward mechanisms, including soft voting and stochastic choice to approximate optimal sampling policy. The evaluation conducted on four datasets evidently highlights the benefits of using RDS method over traditional sampling approaches. Our experimental results suggest that the trainable sampling for model diversification is useful for competition organisers, researchers, or even starters to pursue full potentials of various machine learning tasks such as classification and regression. The source code is available at https://github.com/probeu/RDS.