 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Experimental Investigation of Part-Of-Speech Taggers for Vietnamese
Jun 14, 2022
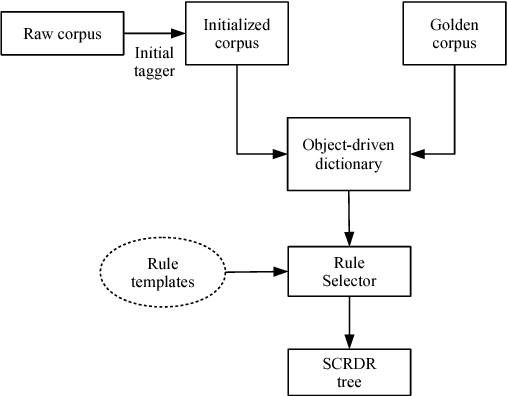

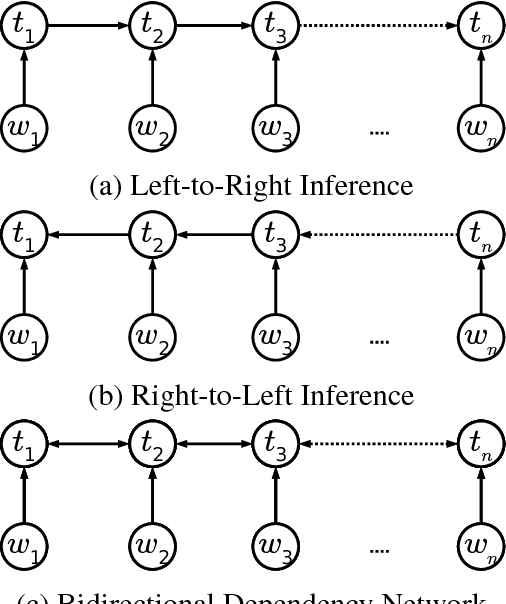
Part-of-speech (POS) tagging plays an important role in Natural Language Processing (NLP). Its applications can be found in many NLP tasks such as named entity recognition, syntactic parsing, dependency parsing and text chunking. In the investigation conducted in this paper, we utilize the technologies of two widely-used toolkits, ClearNLP and Stanford POS Tagger, as well as develop two new POS taggers for Vietnamese, then compare them to three well-known Vietnamese taggers, namely JVnTagger, vnTagger and RDRPOSTagger. We make a systematic comparison to find out the tagger having the best performance. We also design a new feature set to measure the performance of the statistical taggers. Our new taggers built from Stanford Tagger and ClearNLP with the new feature set can outperform all other current Vietnamese taggers in term of tagging accuracy. Moreover, we also analyze the affection of some features to the performance of statistical taggers. Lastly, the experimental results also reveal that the transformation-based tagger, RDRPOSTagger, can run significantly faster than any other statistical tagger.
Reinforced Data Sampling for Model Diversification
Jun 12, 2020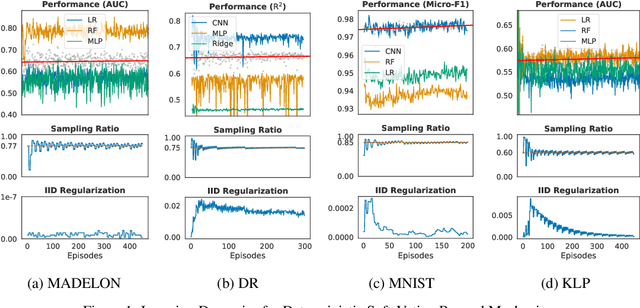
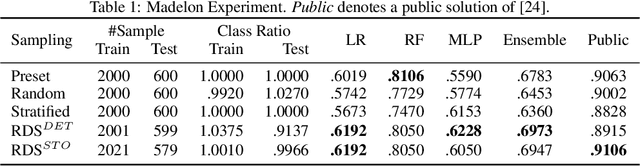
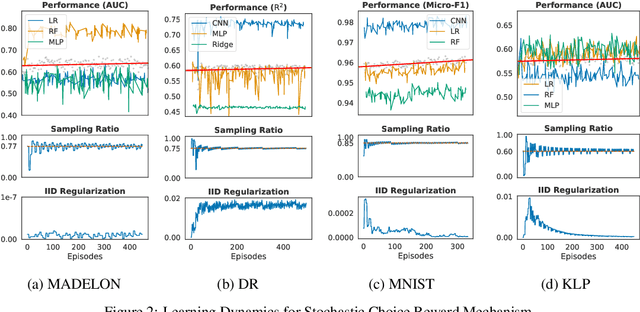
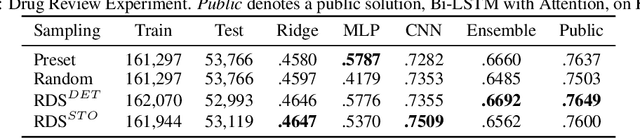
With the rising number of machine learning competitions, the world has witnessed an exciting race for the best algorithms. However, the involved data selection process may fundamentally suffer from evidence ambiguity and concept drift issues, thereby possibly leading to deleterious effects on the performance of various models. This paper proposes a new Reinforced Data Sampling (RDS) method to learn how to sample data adequately on the search for useful models and insights. We formulate the optimisation problem of model diversification $\delta{-div}$ in data sampling to maximise learning potentials and optimum allocation by injecting model diversity. This work advocates the employment of diverse base learners as value functions such as neural networks, decision trees, or logistic regressions to reinforce the selection process of data subsets with multi-modal belief. We introduce different ensemble reward mechanisms, including soft voting and stochastic choice to approximate optimal sampling policy. The evaluation conducted on four datasets evidently highlights the benefits of using RDS method over traditional sampling approaches. Our experimental results suggest that the trainable sampling for model diversification is useful for competition organisers, researchers, or even starters to pursue full potentials of various machine learning tasks such as classification and regression. The source code is available at https://github.com/probeu/RDS.