 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining the Mind: What 100M Beliefs Reveal About Frontier LLM Knowledge
Oct 08, 2025



LLMs are remarkable artifacts that have revolutionized a range of NLP and AI tasks. A significant contributor is their factual knowledge, which, to date, remains poorly understood, and is usually analyzed from biased samples. In this paper, we take a deep tour into the factual knowledge (or beliefs) of a frontier LLM, based on GPTKB v1.5 (Hu et al., 2025a), a recursively elicited set of 100 million beliefs of one of the strongest currently available frontier LLMs, GPT-4.1. We find that the models' factual knowledge differs quite significantly from established knowledge bases, and that its accuracy is significantly lower than indicated by previous benchmarks. We also find that inconsistency, ambiguity and hallucinations are major issues, shedding light on future research opportunities concerning factual LLM knowledge.
Multi-Cultural Commonsense Knowledge Distillation
Feb 16, 2024Despite recent progress, large language models (LLMs) still face the challenge of appropriately reacting to the intricacies of social and cultural conventions. This paper presents MANGO, a methodology for distilling high-accuracy, high-recall assertions of cultural knowledge. We judiciously and iteratively prompt LLMs for this purpose from two entry points, concepts and cultures. Outputs are consolidated via clustering and generative summarization. Running the MANGO method with GPT-3.5 as underlying LLM yields 167K high-accuracy assertions for 30K concepts and 11K cultures, surpassing prior resources by a large margin. For extrinsic evaluation, we explore augmenting dialogue systems with cultural knowledge assertions. We find that adding knowledge from MANGO improves the overall quality, specificity, and cultural sensitivity of dialogue responses, as judged by human annotators. Data and code are available for download.
Extracting Cultural Commonsense Knowledge at Scale
Oct 14, 2022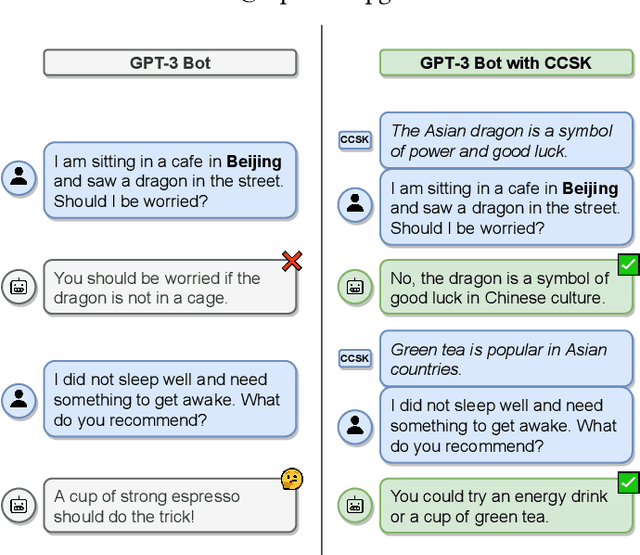



Structured knowledge is important for many AI applications. Commonsense knowledge, which is crucial for robust human-centric AI, is covered by a small number of structured knowledge projects. However, they lack knowledge about human traits and behaviors conditioned on socio-cultural contexts, which is crucial for situative AI. This paper presents CANDLE, an end-to-end methodology for extracting high-quality cultural commonsense knowledge (CCSK) at scale. CANDLE extracts CCSK assertions from a huge web corpus and organizes them into coherent clusters, for 3 domains of subjects (geography, religion, occupation) and several cultural facets (food, drinks, clothing, traditions, rituals, behaviors). CANDLE includes judicious techniques for classification-based filtering and scoring of interestingness. Experimental evaluations show the superiority of the CANDLE CCSK collection over prior works, and an extrinsic use case demonstrates the benefits of CCSK for the GPT-3 language model. Code and data can be accessed at https://cultural-csk.herokuapp.com/.
An Experimental Investigation of Part-Of-Speech Taggers for Vietnamese
Jun 14, 2022
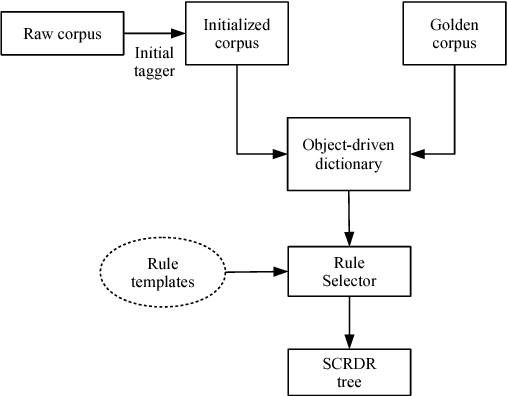

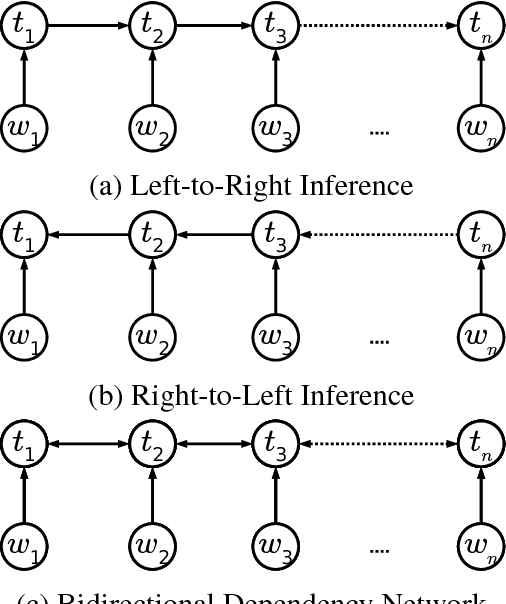
Part-of-speech (POS) tagging plays an important role in Natural Language Processing (NLP). Its applications can be found in many NLP tasks such as named entity recognition, syntactic parsing, dependency parsing and text chunking. In the investigation conducted in this paper, we utilize the technologies of two widely-used toolkits, ClearNLP and Stanford POS Tagger, as well as develop two new POS taggers for Vietnamese, then compare them to three well-known Vietnamese taggers, namely JVnTagger, vnTagger and RDRPOSTagger. We make a systematic comparison to find out the tagger having the best performance. We also design a new feature set to measure the performance of the statistical taggers. Our new taggers built from Stanford Tagger and ClearNLP with the new feature set can outperform all other current Vietnamese taggers in term of tagging accuracy. Moreover, we also analyze the affection of some features to the performance of statistical taggers. Lastly, the experimental results also reveal that the transformation-based tagger, RDRPOSTagger, can run significantly faster than any other statistical tagger.
Materialized Knowledge Bases from Commonsense Transformers
Dec 29, 2021


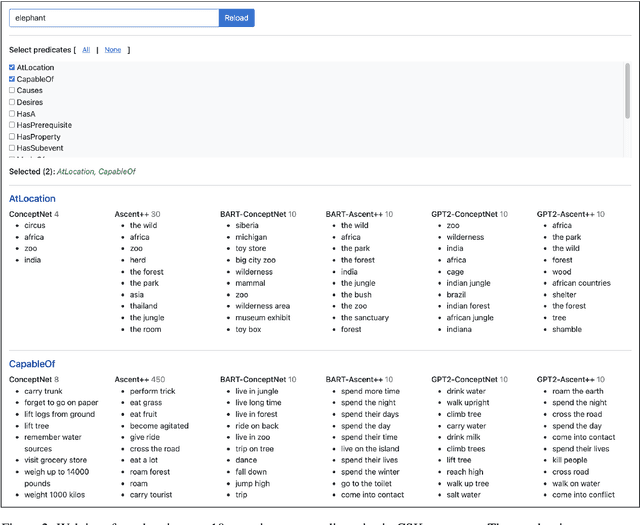
Starting from the COMET methodology by Bosselut et al. (2019), generating commonsense knowledge directly from pre-trained language models has recently received significant attention. Surprisingly, up to now no materialized resource of commonsense knowledge generated this way is publicly available. This paper fills this gap, and uses the materialized resources to perform a detailed analysis of the potential of this approach in terms of precision and recall. Furthermore, we identify common problem cases, and outline use cases enabled by materialized resources. We posit that the availability of these resources is important for the advancement of the field, as it enables an off-the-shelf-use of the resulting knowledge, as well as further analyses on its strengths and weaknesses.
Refined Commonsense Knowledge from Large-Scale Web Contents
Nov 30, 2021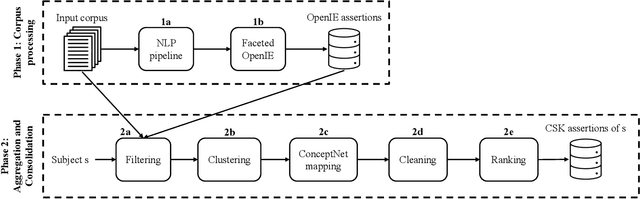

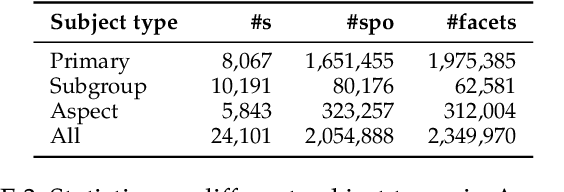

Commonsense knowledge (CSK) about concepts and their properties is useful for AI applications. Prior works like ConceptNet, COMET and others compiled large CSK collections, but are restricted in their expressiveness to subject-predicate-object (SPO) triples with simple concepts for S and strings for P and O. This paper presents a method, called ASCENT++, to automatically build a large-scale knowledge base (KB) of CSK assertions, with refined expressiveness and both better precision and recall than prior works. ASCENT++ goes beyond SPO triples by capturing composite concepts with subgroups and aspects, and by refining assertions with semantic facets. The latter is important to express the temporal and spatial validity of assertions and further qualifiers. ASCENT++ combines open information extraction with judicious cleaning and ranking by typicality and saliency scores. For high coverage, our method taps into the large-scale crawl C4 with broad web contents. The evaluation with human judgements shows the superior quality of the ASCENT++ KB, and an extrinsic evaluation for QA-support tasks underlines the benefits of ASCENT++. A web interface, data and code can be accessed at https://www.mpi-inf.mpg.de/ascentpp.
Inside ASCENT: Exploring a Deep Commonsense Knowledge Base and its Usage in Question Answering
May 28, 2021

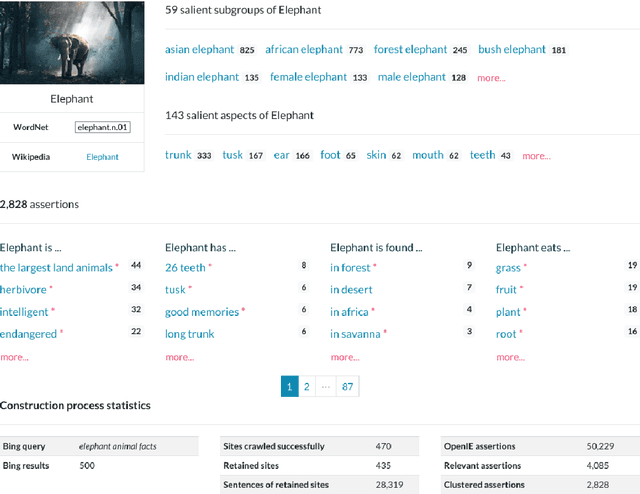
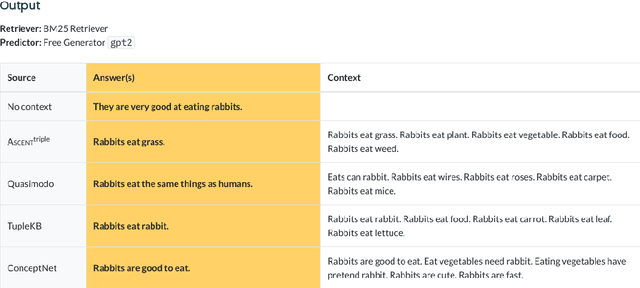
ASCENT is a fully automated methodology for extracting and consolidating commonsense assertions from web contents (Nguyen et al., WWW 2021). It advances traditional triple-based commonsense knowledge representation by capturing semantic facets like locations and purposes, and composite concepts, i.e., subgroups and related aspects of subjects. In this demo, we present a web portal that allows users to understand its construction process, explore its content, and observe its impact in the use case of question answering. The demo website and an introductory video are both available online.
* Demo website: https://ascent.mpi-inf.mpg.de; introductory video: https://youtu.be/qMkJXqu_Yd4
Advanced Semantics for Commonsense Knowledge Extraction
Nov 02, 2020


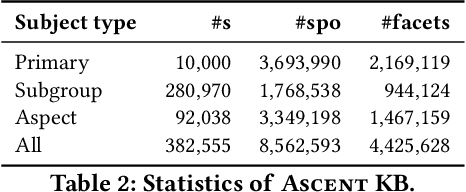
Commonsense knowledge (CSK) about concepts and their properties is useful for AI applications such as robust chatbots. Prior works like ConceptNet, TupleKB and others compiled large CSK collections, but are restricted in their expressiveness to subject-predicate-object (SPO) triples with simple concepts for S and monolithic strings for P and O. Also, these projects have either prioritized precision or recall, but hardly reconcile these complementary goals. This paper presents a methodology, called Ascent, to automatically build a large-scale knowledge base (KB) of CSK assertions, with advanced expressiveness and both better precision and recall than prior works. Ascent goes beyond triples by capturing composite concepts with subgroups and aspects, and by refining assertions with semantic facets. The latter are important to express temporal and spatial validity of assertions and further qualifiers. Ascent combines open information extraction with judicious cleaning using language models. Intrinsic evaluation shows the superior size and quality of the Ascent KB, and an extrinsic evaluation for QA-support tasks underlines the benefits of Ascent.