 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Cultural Commonsense Knowledge at Scale
Oct 14, 2022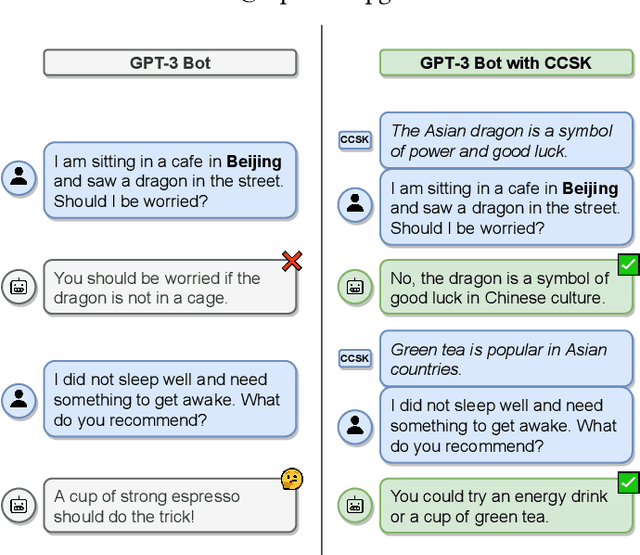



Structured knowledge is important for many AI applications. Commonsense knowledge, which is crucial for robust human-centric AI, is covered by a small number of structured knowledge projects. However, they lack knowledge about human traits and behaviors conditioned on socio-cultural contexts, which is crucial for situative AI. This paper presents CANDLE, an end-to-end methodology for extracting high-quality cultural commonsense knowledge (CCSK) at scale. CANDLE extracts CCSK assertions from a huge web corpus and organizes them into coherent clusters, for 3 domains of subjects (geography, religion, occupation) and several cultural facets (food, drinks, clothing, traditions, rituals, behaviors). CANDLE includes judicious techniques for classification-based filtering and scoring of interestingness. Experimental evaluations show the superiority of the CANDLE CCSK collection over prior works, and an extrinsic use case demonstrates the benefits of CCSK for the GPT-3 language model. Code and data can be accessed at https://cultural-csk.herokuapp.com/.
The Hidden Web, XML and Semantic Web: A Scientific Data Management Perspective
May 10, 2011The World Wide Web no longer consists just of HTML pages. Our work sheds light on a number of trends on the Internet that go beyond simple Web pages. The hidden Web provides a wealth of data in semi-structured form, accessible through Web forms and Web services. These services, as well as numerous other applications on the Web, commonly use XML, the eXtensible Markup Language. XML has become the lingua franca of the Internet that allows customized markups to be defined for specific domains. On top of XML, the Semantic Web grows as a common structured data source. In this work, we first explain each of these developments in detail. Using real-world examples from scientific domains of great interest today, we then demonstrate how these new developments can assist the managing, harvesting, and organization of data on the Web. On the way, we also illustrate the current research avenues in these domains. We believe that this effort would help bridge multiple database tracks, thereby attracting researchers with a view to extend database technology.