 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAD: A Deep Dive into Model Selection for Time series Anomaly Detection
Oct 30, 2025Anomaly detection is a fundamental task for time series analytics with important implications for the downstream performance of many applications. Despite increasing academic interest and the large number of methods proposed in the literature, recent benchmarks and evaluation studies demonstrated that no overall best anomaly detection methods exist when applied to very heterogeneous time series datasets. Therefore, the only scalable and viable solution to solve anomaly detection over very different time series collected from diverse domains is to propose a model selection method that will select, based on time series characteristics, the best anomaly detection methods to run. Existing AutoML solutions are, unfortunately, not directly applicable to time series anomaly detection, and no evaluation of time series-based approaches for model selection exists. Towards that direction, this paper studies the performance of time series classification methods used as model selection for anomaly detection. In total, we evaluate 234 model configurations derived from 16 base classifiers across more than 1980 time series, and we propose the first extensive experimental evaluation of time series classification as model selection for anomaly detection. Our results demonstrate that model selection methods outperform every single anomaly detection method while being in the same order of magnitude regarding execution time. This evaluation is the first step to demonstrate the accuracy and efficiency of time series classification algorithms for anomaly detection, and represents a strong baseline that can then be used to guide the model selection step in general AutoML pipelines. Preprint version of an article accepted at the VLDB Journal.
* 25 pages, 13 figures, VLDB Journal
Expected Shapley-Like Scores of Boolean Functions: Complexity and Applications to Probabilistic Databases
Jan 12, 2024
Shapley values, originating in game theory and increasingly prominent in explainable AI, have been proposed to assess the contribution of facts in query answering over databases, along with other similar power indices such as Banzhaf values. In this work we adapt these Shapley-like scores to probabilistic settings, the objective being to compute their expected value. We show that the computations of expected Shapley values and of the expected values of Boolean functions are interreducible in polynomial time, thus obtaining the same tractability landscape. We investigate the specific tractable case where Boolean functions are represented as deterministic decomposable circuits, designing a polynomial-time algorithm for this setting. We present applications to probabilistic databases through database provenance, and an effective implementation of this algorithm within the ProvSQL system, which experimentally validates its feasibility over a standard benchmark.
Extracting Definienda in Mathematical Scholarly Articles with Transformers
Nov 21, 2023We consider automatically identifying the defined term within a mathematical definition from the text of an academic article. Inspired by the development of transformer-based natural language processing applications, we pose the problem as (a) a token-level classification task using fine-tuned pre-trained transformers; and (b) a question-answering task using a generalist large language model (GPT). We also propose a rule-based approach to build a labeled dataset from the LATEX source of papers. Experimental results show that it is possible to reach high levels of precision and recall using either recent (and expensive) GPT 4 or simpler pre-trained models fine-tuned on our task.
Multimodal Machine Learning for Extraction of Theorems and Proofs in the Scientific Literature
Jul 18, 2023



Scholarly articles in mathematical fields feature mathematical statements such as theorems, propositions, etc., as well as their proofs. Extracting them from the PDF representation of the articles requires understanding of scientific text along with visual and font-based indicators. We pose this problem as a multimodal classification problem using text, font features, and bitmap image rendering of the PDF as different modalities. In this paper we propose a multimodal machine learning approach for extraction of theorem-like environments and proofs, based on late fusion of features extracted by individual unimodal classifiers, taking into account the sequential succession of blocks in the document. For the text modality, we pretrain a new language model on a 11 GB scientific corpus; experiments shows similar performance for our task than a model (RoBERTa) pretrained on 160 GB, with faster convergence while requiring much less fine-tuning data. Font-based information relies on training a 128-cell LSTM on the sequence of font names and sizes within each block. Bitmap renderings are dealt with using an EfficientNetv2 deep network tuned to classify each image block. Finally, a simple CRF-based approach uses the features of the multimodal model along with information on block sequences. Experimental results show the benefits of using a multimodal approach vs any single modality, as well as major performance improvements using the CRF modeling of block sequences.
BelMan: Bayesian Bandits on the Belief--Reward Manifold
May 04, 2018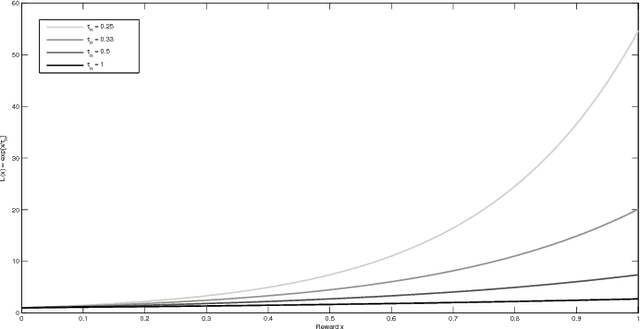
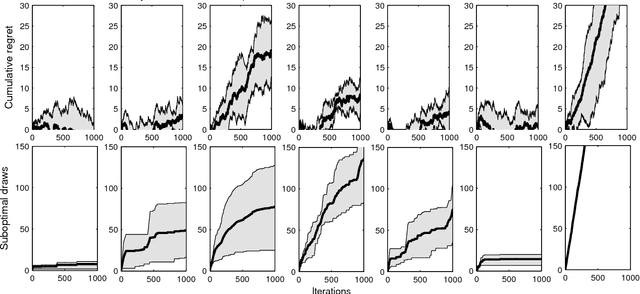
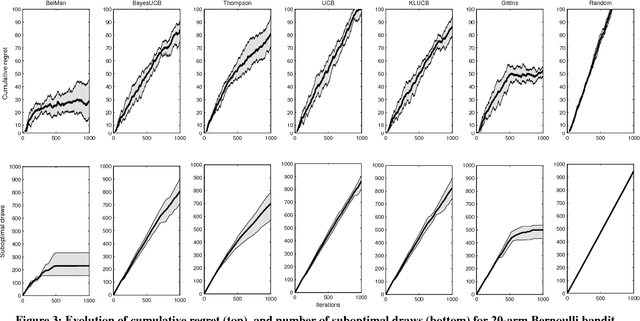
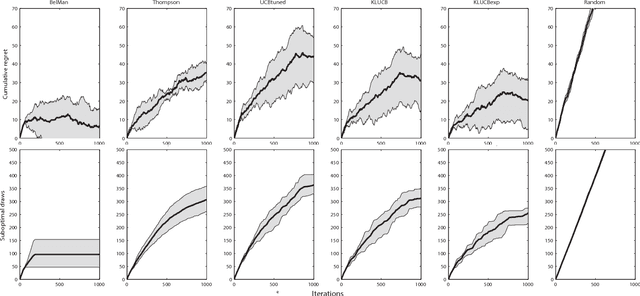
We propose a generic, Bayesian, information geometric approach to the exploration--exploitation trade-off in multi-armed bandit problems. Our approach, BelMan, uniformly supports pure exploration, exploration--exploitation, and two-phase bandit problems. The knowledge on bandit arms and their reward distributions is summarised by the barycentre of the joint distributions of beliefs and rewards of the arms, the \emph{pseudobelief-reward}, within the beliefs-rewards manifold. BelMan alternates \emph{information projection} and \emph{reverse information projection}, i.e., projection of the pseudobelief-reward onto beliefs-rewards to choose the arm to play, and projection of the resulting beliefs-rewards onto the pseudobelief-reward. It introduces a mechanism that infuses an exploitative bias by means of a \emph{focal distribution}, i.e., a reward distribution that gradually concentrates on higher rewards. Comparative performance evaluation with state-of-the-art algorithms shows that BelMan is not only competitive but can also outperform other approaches in specific setups, for instance involving many arms and continuous rewards.
Ontology Alignment at the Instance and Schema Level
Aug 18, 2011
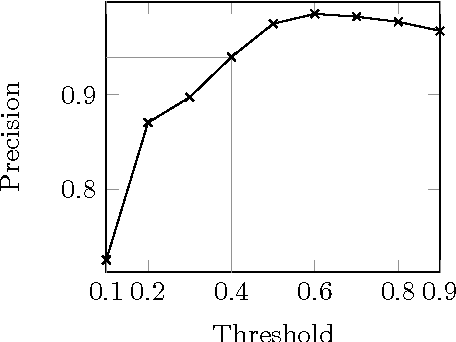
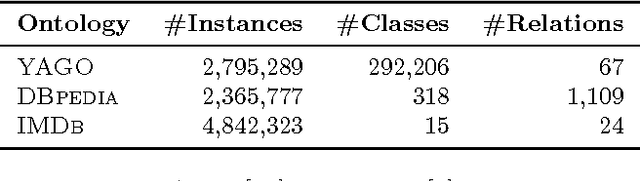

We present PARIS, an approach for the automatic alignment of ontologies. PARIS aligns not only instances, but also relations and classes. Alignments at the instance-level cross-fertilize with alignments at the schema-level. Thereby, our system provides a truly holistic solution to the problem of ontology alignment. The heart of the approach is probabilistic. This allows PARIS to run without any parameter tuning. We demonstrate the efficiency of the algorithm and its precision through extensive experiments. In particular, we obtain a precision of around 90% in experiments with two of the world's largest ontologies.
* Technical Report at INRIA RT-0408
The Hidden Web, XML and Semantic Web: A Scientific Data Management Perspective
May 10, 2011The World Wide Web no longer consists just of HTML pages. Our work sheds light on a number of trends on the Internet that go beyond simple Web pages. The hidden Web provides a wealth of data in semi-structured form, accessible through Web forms and Web services. These services, as well as numerous other applications on the Web, commonly use XML, the eXtensible Markup Language. XML has become the lingua franca of the Internet that allows customized markups to be defined for specific domains. On top of XML, the Semantic Web grows as a common structured data source. In this work, we first explain each of these developments in detail. Using real-world examples from scientific domains of great interest today, we then demonstrate how these new developments can assist the managing, harvesting, and organization of data on the Web. On the way, we also illustrate the current research avenues in these domains. We believe that this effort would help bridge multiple database tracks, thereby attracting researchers with a view to extend database technology.