 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBelMan: Bayesian Bandits on the Belief--Reward Manifold
Paper and Code
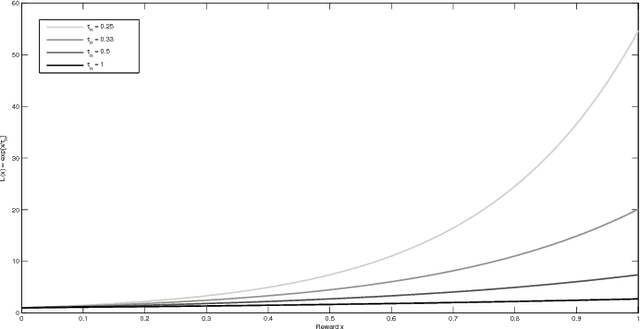
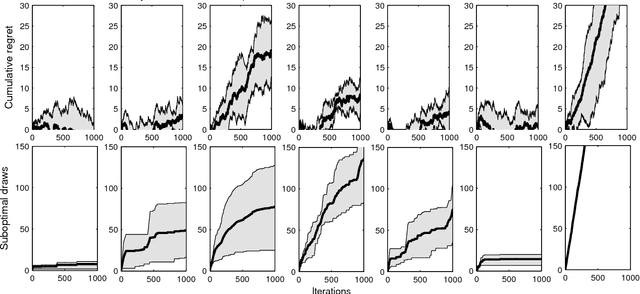
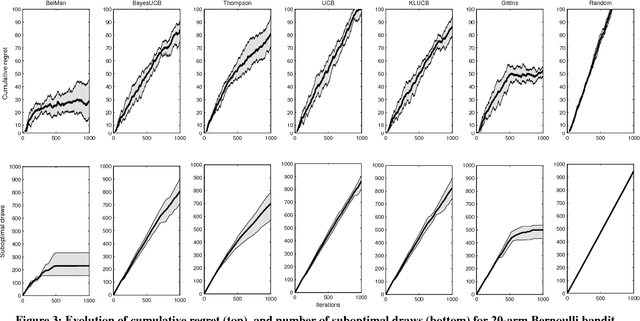
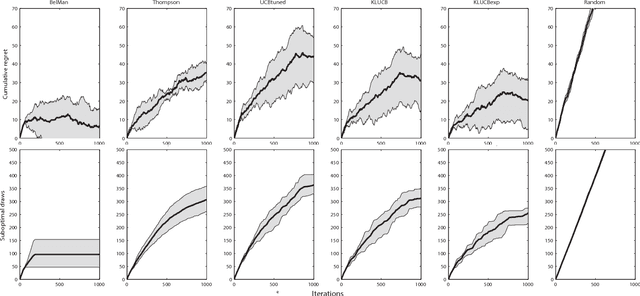
We propose a generic, Bayesian, information geometric approach to the exploration--exploitation trade-off in multi-armed bandit problems. Our approach, BelMan, uniformly supports pure exploration, exploration--exploitation, and two-phase bandit problems. The knowledge on bandit arms and their reward distributions is summarised by the barycentre of the joint distributions of beliefs and rewards of the arms, the \emph{pseudobelief-reward}, within the beliefs-rewards manifold. BelMan alternates \emph{information projection} and \emph{reverse information projection}, i.e., projection of the pseudobelief-reward onto beliefs-rewards to choose the arm to play, and projection of the resulting beliefs-rewards onto the pseudobelief-reward. It introduces a mechanism that infuses an exploitative bias by means of a \emph{focal distribution}, i.e., a reward distribution that gradually concentrates on higher rewards. Comparative performance evaluation with state-of-the-art algorithms shows that BelMan is not only competitive but can also outperform other approaches in specific setups, for instance involving many arms and continuous rewards.