 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRediscovering the Lunar Equation of the Centre with AI Feynman via Embedded Physical Biases
Nov 13, 2025This work explores using the physics-inspired AI Feynman symbolic regression algorithm to automatically rediscover a fundamental equation in astronomy -- the Equation of the Centre. Through the introduction of observational and inductive biases corresponding to the physical nature of the system through data preprocessing and search space restriction, AI Feynman was successful in recovering the first-order analytical form of this equation from lunar ephemerides data. However, this manual approach highlights a key limitation in its reliance on expert-driven coordinate system selection. We therefore propose an automated preprocessing extension to find the canonical coordinate system. Results demonstrate that targeted domain knowledge embedding enables symbolic regression to rediscover physical laws, but also highlight further challenges in constraining symbolic regression to derive physics equations when leveraging domain knowledge through tailored biases.
Physics-informed Discovery of State Variables in Second-Order and Hamiltonian Systems
Aug 21, 2024The modeling of dynamical systems is a pervasive concern for not only describing but also predicting and controlling natural phenomena and engineered systems. Current data-driven approaches often assume prior knowledge of the relevant state variables or result in overparameterized state spaces. Boyuan Chen and his co-authors proposed a neural network model that estimates the degrees of freedom and attempts to discover the state variables of a dynamical system. Despite its innovative approach, this baseline model lacks a connection to the physical principles governing the systems it analyzes, leading to unreliable state variables. This research proposes a method that leverages the physical characteristics of second-order Hamiltonian systems to constrain the baseline model. The proposed model outperforms the baseline model in identifying a minimal set of non-redundant and interpretable state variables.
Expected Shapley-Like Scores of Boolean Functions: Complexity and Applications to Probabilistic Databases
Jan 12, 2024
Shapley values, originating in game theory and increasingly prominent in explainable AI, have been proposed to assess the contribution of facts in query answering over databases, along with other similar power indices such as Banzhaf values. In this work we adapt these Shapley-like scores to probabilistic settings, the objective being to compute their expected value. We show that the computations of expected Shapley values and of the expected values of Boolean functions are interreducible in polynomial time, thus obtaining the same tractability landscape. We investigate the specific tractable case where Boolean functions are represented as deterministic decomposable circuits, designing a polynomial-time algorithm for this setting. We present applications to probabilistic databases through database provenance, and an effective implementation of this algorithm within the ProvSQL system, which experimentally validates its feasibility over a standard benchmark.
Celestial Machine Learning: Discovering the Planarity, Heliocentricity, and Orbital Equation of Mars with AI Feynman
Dec 19, 2023Can a machine or algorithm discover or learn the elliptical orbit of Mars from astronomical sightings alone? Johannes Kepler required two paradigm shifts to discover his First Law regarding the elliptical orbit of Mars. Firstly, a shift from the geocentric to the heliocentric frame of reference. Secondly, the reduction of the orbit of Mars from a three- to a two-dimensional space. We extend AI Feynman, a physics-inspired tool for symbolic regression, to discover the heliocentricity and planarity of Mars' orbit and emulate his discovery of Kepler's first law.
A Comparative Evaluation of Additive Separability Tests for Physics-Informed Machine Learning
Dec 19, 2023Many functions characterising physical systems are additively separable. This is the case, for instance, of mechanical Hamiltonian functions in physics, population growth equations in biology, and consumer preference and utility functions in economics. We consider the scenario in which a surrogate of a function is to be tested for additive separability. The detection that the surrogate is additively separable can be leveraged to improve further learning. Hence, it is beneficial to have the ability to test for such separability in surrogates. The mathematical approach is to test if the mixed partial derivative of the surrogate is zero; or empirically, lower than a threshold. We present and comparatively and empirically evaluate the eight methods to compute the mixed partial derivative of a surrogate function.
What's Next? Predicting Hamiltonian Dynamics from Discrete Observations of a Vector Field
Dec 15, 2023We present several methods for predicting the dynamics of Hamiltonian systems from discrete observations of their vector field. Each method is either informed or uninformed of the Hamiltonian property. We empirically and comparatively evaluate the methods and observe that information that the system is Hamiltonian can be effectively informed, and that different methods strike different trade-offs between efficiency and effectiveness for different dynamical systems.
Celestial Machine Learning: From Data to Mars and Beyond with AI Feynman
Dec 15, 2023Can a machine or algorithm discover or learn Kepler's first law from astronomical sightings alone? We emulate Johannes Kepler's discovery of the equation of the orbit of Mars with the Rudolphine tables using AI Feynman, a physics-inspired tool for symbolic regression.
Separable Hamiltonian Neural Networks
Sep 06, 2023The modelling of dynamical systems from discrete observations is a challenge faced by modern scientific and engineering data systems. Hamiltonian systems are one such fundamental and ubiquitous class of dynamical systems. Hamiltonian neural networks are state-of-the-art models that unsupervised-ly regress the Hamiltonian of a dynamical system from discrete observations of its vector field under the learning bias of Hamilton's equations. Yet Hamiltonian dynamics are often complicated, especially in higher dimensions where the state space of the Hamiltonian system is large relative to the number of samples. A recently discovered remedy to alleviate the complexity between state variables in the state space is to leverage the additive separability of the Hamiltonian system and embed that additive separability into the Hamiltonian neural network. Following the nomenclature of physics-informed machine learning, we propose three separable Hamiltonian neural networks. These models embed additive separability within Hamiltonian neural networks. The first model uses additive separability to quadratically scale the amount of data for training Hamiltonian neural networks. The second model embeds additive separability within the loss function of the Hamiltonian neural network. The third model embeds additive separability through the architecture of the Hamiltonian neural network using conjoined multilayer perceptions. We empirically compare the three models against state-of-the-art Hamiltonian neural networks, and demonstrate that the separable Hamiltonian neural networks, which alleviate complexity between the state variables, are more effective at regressing the Hamiltonian and its vector field.
BelMan: Bayesian Bandits on the Belief--Reward Manifold
May 04, 2018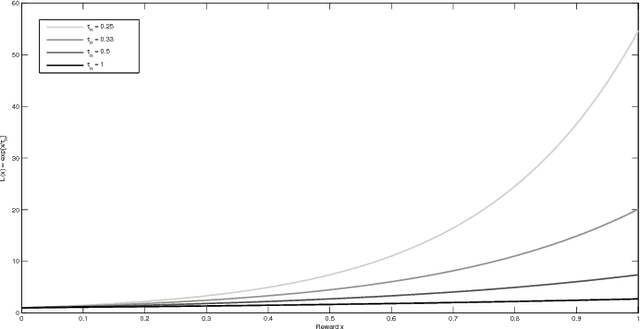
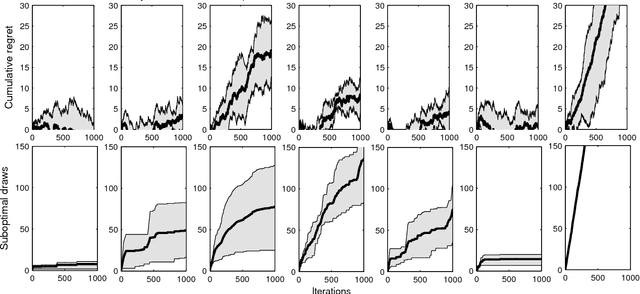
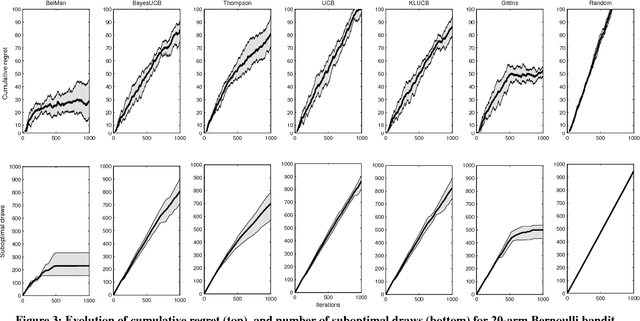
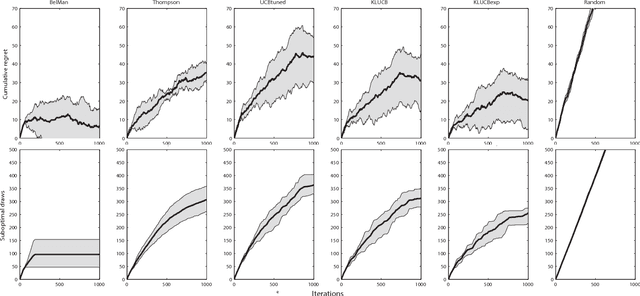
We propose a generic, Bayesian, information geometric approach to the exploration--exploitation trade-off in multi-armed bandit problems. Our approach, BelMan, uniformly supports pure exploration, exploration--exploitation, and two-phase bandit problems. The knowledge on bandit arms and their reward distributions is summarised by the barycentre of the joint distributions of beliefs and rewards of the arms, the \emph{pseudobelief-reward}, within the beliefs-rewards manifold. BelMan alternates \emph{information projection} and \emph{reverse information projection}, i.e., projection of the pseudobelief-reward onto beliefs-rewards to choose the arm to play, and projection of the resulting beliefs-rewards onto the pseudobelief-reward. It introduces a mechanism that infuses an exploitative bias by means of a \emph{focal distribution}, i.e., a reward distribution that gradually concentrates on higher rewards. Comparative performance evaluation with state-of-the-art algorithms shows that BelMan is not only competitive but can also outperform other approaches in specific setups, for instance involving many arms and continuous rewards.