 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGBQA: A Game Benchmark for Evaluating LLMs as Quality Assurance Engineers
Apr 03, 2026The autonomous discovery of bugs remains a significant challenge in modern software development. Compared to code generation, the complexity of dynamic runtime environments makes bug discovery considerably harder for large language models (LLMs). In this paper, we take game development as a representative domain and introduce the Game Benchmark for Quality Assurance (GBQA), a benchmark containing 30 games and 124 human-verified bugs across three difficulty levels, to evaluate whether LLMs can autonomously detect software bugs. The benchmark is constructed using a multi-agent system that develops games and injects bugs in a scalable manner, with human experts in the loop to ensure correctness. Moreover, we provide a baseline interactive agent equipped with a multi-round ReAct loop and a memory mechanism, enabling long-horizon exploration of game environments for bug detection across different LLMs. Extensive experiments on frontier LLMs demonstrate that autonomous bug discovery remains highly challenging: the best-performing model, Claude-4.6-Opus in thinking mode, identifies only 48.39% of the verified bugs. We believe GBQA provides an adequate testbed and evaluation criterion, and that further progress on it will help close the gap in autonomous software engineering.
NFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
Extracting Definienda in Mathematical Scholarly Articles with Transformers
Nov 21, 2023We consider automatically identifying the defined term within a mathematical definition from the text of an academic article. Inspired by the development of transformer-based natural language processing applications, we pose the problem as (a) a token-level classification task using fine-tuned pre-trained transformers; and (b) a question-answering task using a generalist large language model (GPT). We also propose a rule-based approach to build a labeled dataset from the LATEX source of papers. Experimental results show that it is possible to reach high levels of precision and recall using either recent (and expensive) GPT 4 or simpler pre-trained models fine-tuned on our task.
Named Entity Recognition for Monitoring Plant Health Threats in Tweets: a ChouBERT Approach
Oct 19, 2023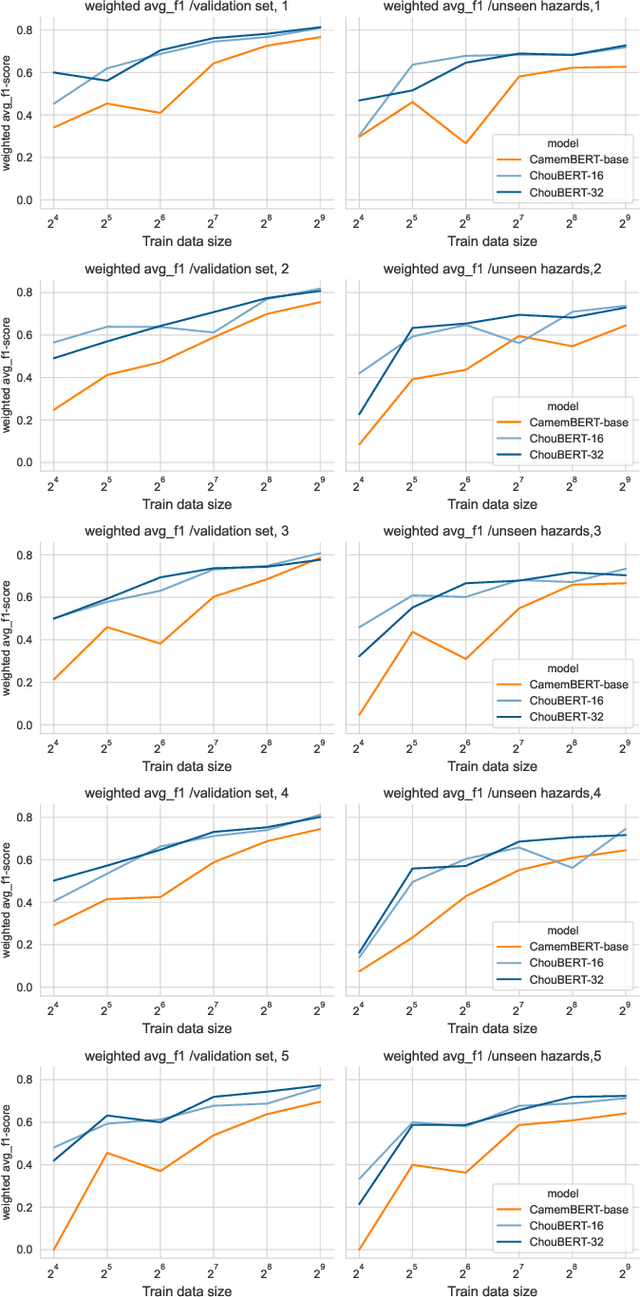



An important application scenario of precision agriculture is detecting and measuring crop health threats using sensors and data analysis techniques. However, the textual data are still under-explored among the existing solutions due to the lack of labelled data and fine-grained semantic resources. Recent research suggests that the increasing connectivity of farmers and the emergence of online farming communities make social media like Twitter a participatory platform for detecting unfamiliar plant health events if we can extract essential information from unstructured textual data. ChouBERT is a French pre-trained language model that can identify Tweets concerning observations of plant health issues with generalizability on unseen natural hazards. This paper tackles the lack of labelled data by further studying ChouBERT's know-how on token-level annotation tasks over small labeled sets.
Fine-tuning BERT-based models for Plant Health Bulletin Classification
Jan 29, 2021

In the era of digitization, different actors in agriculture produce numerous data. Such data contains already latent historical knowledge in the domain. This knowledge enables us to precisely study natural hazards within global or local aspects, and then improve the risk prevention tasks and augment the yield, which helps to tackle the challenge of growing population and changing alimentary habits. In particular, French Plants Health Bulletins (BSV, for its name in French Bulletin de Sant{\'e} du V{\'e}g{\'e}tal) give information about the development stages of phytosanitary risks in agricultural production. However, they are written in natural language, thus, machines and human cannot exploit them as efficiently as it could be. Natural language processing (NLP) technologies aim to automatically process and analyze large amounts of natural language data. Since the 2010s, with the increases in computational power and parallelization, representation learning and deep learning methods became widespread in NLP. Recent advancements Bidirectional Encoder Representations from Transformers (BERT) inspire us to rethink of knowledge representation and natural language understanding in plant health management domain. The goal in this work is to propose a BERT-based approach to automatically classify the BSV to make their data easily indexable. We sampled 200 BSV to finetune the pretrained BERT language models and classify them as pest or/and disease and we show preliminary results.