 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNamed Entity Recognition for Monitoring Plant Health Threats in Tweets: a ChouBERT Approach
Oct 19, 2023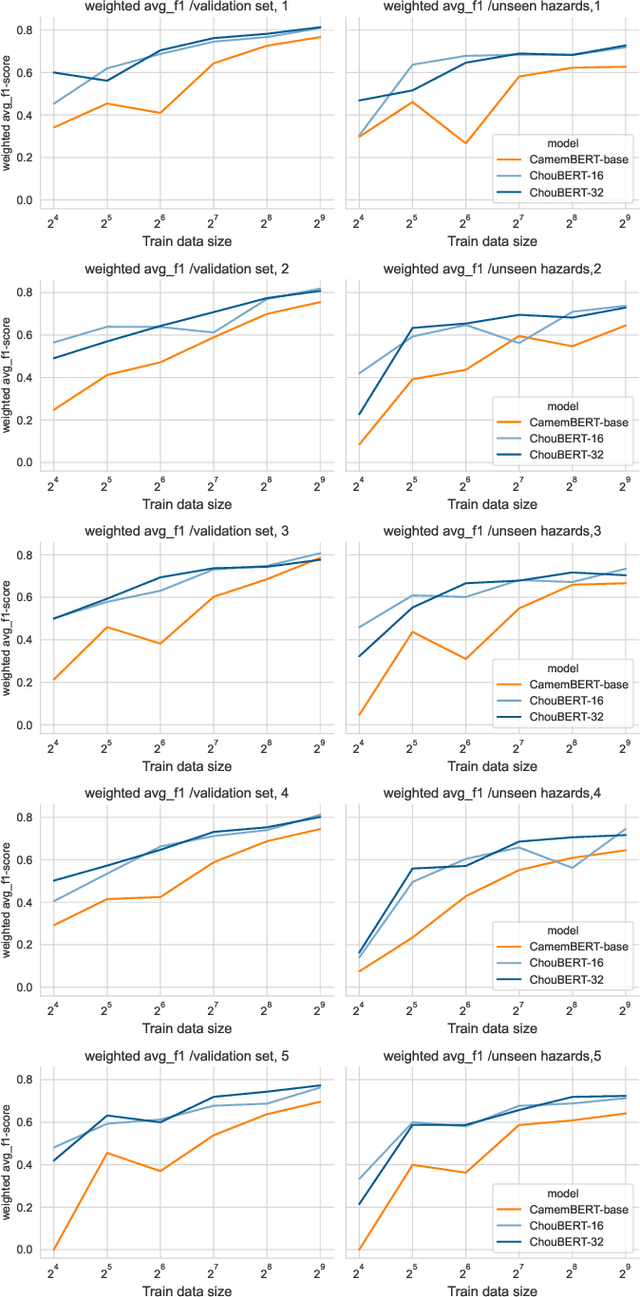



An important application scenario of precision agriculture is detecting and measuring crop health threats using sensors and data analysis techniques. However, the textual data are still under-explored among the existing solutions due to the lack of labelled data and fine-grained semantic resources. Recent research suggests that the increasing connectivity of farmers and the emergence of online farming communities make social media like Twitter a participatory platform for detecting unfamiliar plant health events if we can extract essential information from unstructured textual data. ChouBERT is a French pre-trained language model that can identify Tweets concerning observations of plant health issues with generalizability on unseen natural hazards. This paper tackles the lack of labelled data by further studying ChouBERT's know-how on token-level annotation tasks over small labeled sets.
Combining pre-trained Vision Transformers and CIDER for Out Of Domain Detection
Sep 06, 2023



Out-of-domain (OOD) detection is a crucial component in industrial applications as it helps identify when a model encounters inputs that are outside the training distribution. Most industrial pipelines rely on pre-trained models for downstream tasks such as CNN or Vision Transformers. This paper investigates the performance of those models on the task of out-of-domain detection. Our experiments demonstrate that pre-trained transformers models achieve higher detection performance out of the box. Furthermore, we show that pre-trained ViT and CNNs can be combined with refinement methods such as CIDER to improve their OOD detection performance even more. Our results suggest that transformers are a promising approach for OOD detection and set a stronger baseline for this task in many contexts
Fine-tuning BERT-based models for Plant Health Bulletin Classification
Jan 29, 2021

In the era of digitization, different actors in agriculture produce numerous data. Such data contains already latent historical knowledge in the domain. This knowledge enables us to precisely study natural hazards within global or local aspects, and then improve the risk prevention tasks and augment the yield, which helps to tackle the challenge of growing population and changing alimentary habits. In particular, French Plants Health Bulletins (BSV, for its name in French Bulletin de Sant{\'e} du V{\'e}g{\'e}tal) give information about the development stages of phytosanitary risks in agricultural production. However, they are written in natural language, thus, machines and human cannot exploit them as efficiently as it could be. Natural language processing (NLP) technologies aim to automatically process and analyze large amounts of natural language data. Since the 2010s, with the increases in computational power and parallelization, representation learning and deep learning methods became widespread in NLP. Recent advancements Bidirectional Encoder Representations from Transformers (BERT) inspire us to rethink of knowledge representation and natural language understanding in plant health management domain. The goal in this work is to propose a BERT-based approach to automatically classify the BSV to make their data easily indexable. We sampled 200 BSV to finetune the pretrained BERT language models and classify them as pest or/and disease and we show preliminary results.
Similarité en intension vs en extension : à la croisée de l'informatique et du théâtre
Dec 24, 2009

Traditional staging is based on a formal approach of similarity leaning on dramaturgical ontologies and instanciation variations. Inspired by interactive data mining, that suggests different approaches, we give an overview of computer science and theater researches using computers as partners of the actor to escape the a priori specification of roles.