 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn experimental comparative study of backpropagation and alternatives for training binary neural networks for image classification
Aug 08, 2024



Current artificial neural networks are trained with parameters encoded as floating point numbers that occupy lots of memory space at inference time. Due to the increase in the size of deep learning models, it is becoming very difficult to consider training and using artificial neural networks on edge devices. Binary neural networks promise to reduce the size of deep neural network models, as well as to increase inference speed while decreasing energy consumption. Thus, they may allow the deployment of more powerful models on edge devices. However, binary neural networks are still proven to be difficult to train using the backpropagation-based gradient descent scheme. This paper extends the work of \cite{crulis2023alternatives}, which proposed adapting to binary neural networks two promising alternatives to backpropagation originally designed for continuous neural networks, and experimented with them on simple image classification datasets. This paper proposes new experiments on the ImageNette dataset, compares three different model architectures for image classification, and adds two additional alternatives to backpropagation.
Combining pre-trained Vision Transformers and CIDER for Out Of Domain Detection
Sep 06, 2023



Out-of-domain (OOD) detection is a crucial component in industrial applications as it helps identify when a model encounters inputs that are outside the training distribution. Most industrial pipelines rely on pre-trained models for downstream tasks such as CNN or Vision Transformers. This paper investigates the performance of those models on the task of out-of-domain detection. Our experiments demonstrate that pre-trained transformers models achieve higher detection performance out of the box. Furthermore, we show that pre-trained ViT and CNNs can be combined with refinement methods such as CIDER to improve their OOD detection performance even more. Our results suggest that transformers are a promising approach for OOD detection and set a stronger baseline for this task in many contexts
Methodology for Mining, Discovering and Analyzing Semantic Human Mobility Behaviors
Dec 20, 2020
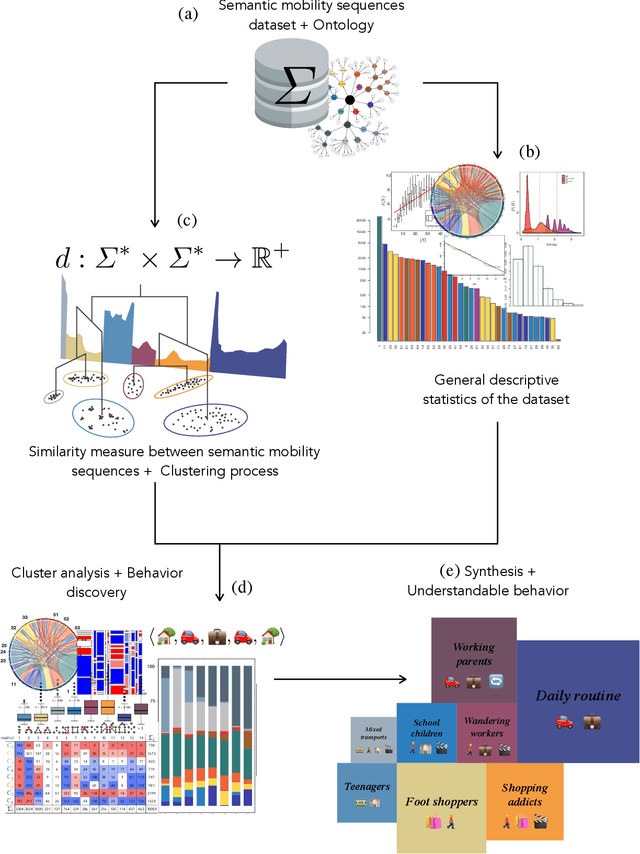
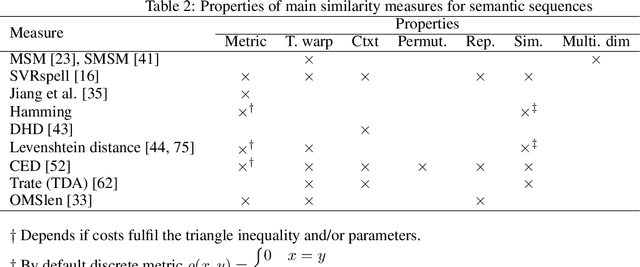
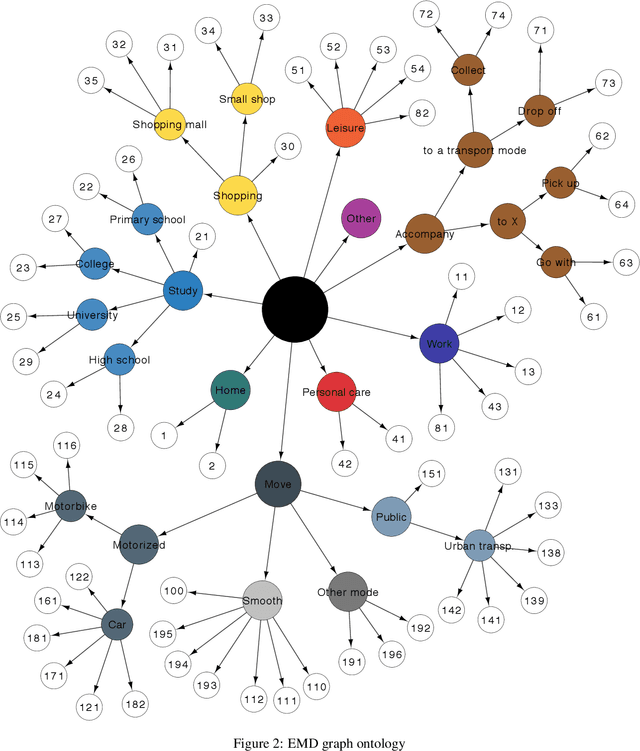
Various institutes produce large semantic datasets containing information regarding daily activities and human mobility. The analysis and understanding of such data are crucial for urban planning, socio-psychology, political sciences, and epidemiology. However, none of the typical data mining processes have been customized for the thorough analysis of semantic mobility sequences to translate data into understandable behaviors. Based on an extended literature review, we propose a novel methodological pipeline called simba (Semantic Indicators for Mobility and Behavior Analysis), for mining and analyzing semantic mobility sequences to identify coherent information and human behaviors. A framework for semantic sequence mobility analysis and clustering explicability based on integrating different complementary statistical indicators and visual tools is implemented. To validate this methodology, we used a large set of real daily mobility sequences obtained from a household travel survey. Complementary knowledge is automatically discovered in the proposed method.