 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Questions: Evaluating What Large Language Models (Actually) Know
May 26, 2026Parametric knowledge in large language models (LLMs) is a cornerstone of their success, yet remains poorly understood. Existing knowledge benchmarks typically rely on predefined questions (e.g., "What is the birth date of M.L. King?"), evaluating only knowledge that benchmark designers explicitly choose to query, a problematic availability bias. In this paper, we introduce open knowledge evaluation, a new paradigm for LLM knowledge benchmarking. Instead of asking narrow questions, it evaluates models on the knowledge they choose to surface in response to open-ended elicitation prompts (e.g., "Tell me everything you know about M.L. King"). This shifts the focus from predefined answer retrieval toward characterizing the knowledge models naturally express. We instantiate this paradigm with BeQu (Beyond Questions), a benchmark of 10,000 entities paired with reference corpora for statement verification. Using BeQu, we evaluate a broad range of language models and analyze the effects of reasoning effort, model scale, prompt format, and knowledge domain. Data and leaderboard are available on this work's GitHub repository and at the benchmark's website.
Is It Novel and Why? Fine-Grained Patent Novelty Prediction Based on Passage Retrieval
May 04, 2026Novelty assessment is a critical yet complex task in the examination process for patent acceptance, requiring examiners to determine whether an invention is disclosed in a prior art document. The process involves intricate matching between specific features of a patent claim and passages in the prior art. While prior work has approached novelty prediction primarily as a binary classification task at the claim level, we argue that this formulation is susceptible to spurious correlations and lacks the granularity required for practical application. In this work, we introduce FiNE-Patents (Fine-grained Novelty Examination of Patents), a novel dataset comprising 3,658 first patent claims annotated with fine-grained, feature-level prior art references extracted from European Search Opinion (ESOP) documents. We propose shifting the evaluation paradigm from simple binary classification to a joint retrieval and abstract reasoning task at the feature level, requiring models to identify specific passages from a prior art document that disclose individual claim features, and to identify which features of a claim make it novel. We implement and evaluate LLM-based workflows that decompose claims into features, analyze each feature against prior art, and finally derive a claim-level novelty prediction. Our experiments demonstrate that these workflows outperform embedding-based baselines on passage retrieval and novel feature identification. Furthermore, we show that unlike trained classifiers, LLMs are robust against spurious correlations present in the claim-level novelty classification task. We release the dataset and code to foster further research into transparent and granular patent analysis.
LLMpedia: A Transparent Framework to Materialize an LLM's Encyclopedic Knowledge at Scale
Mar 25, 2026Benchmarks such as MMLU suggest flagship language models approach factuality saturation, with scores above 90\%. We show this picture is incomplete. \emph{LLMpedia} generates encyclopedic articles entirely from parametric memory, producing ${\sim}$1M articles across three model families without retrieval. For gpt-5-mini, the verifiable true rate on Wikipedia-covered subjects is only 74.7\% -- more than 15 percentage points below the benchmark-based picture, consistent with the availability bias of fixed-question evaluation. Beyond Wikipedia, frontier subjects verifiable only through curated web evidence fall further to 63.2\% true rate. Wikipedia covers just 61\% of surfaced subjects, and three model families overlap by only 7.3\% in subject choice. In a capture-trap benchmark inspired by prior analysis of Grokipedia, LLMpedia achieves substantially higher factuality at roughly half the textual similarity to Wikipedia. Unlike Grokipedia, every prompt, artifact, and evaluation verdict is publicly released, making LLMpedia the first fully open parametric encyclopedia -- bridging factuality evaluation and knowledge materialization. All data, code, and a browsable interface are at https://llmpedia.net.
A Solver-in-the-Loop Framework for Improving LLMs on Answer Set Programming for Logic Puzzle Solving
Dec 18, 2025



The rise of large language models (LLMs) has sparked interest in coding assistants. While general-purpose programming languages are well supported, generating code for domain-specific languages remains a challenging problem for LLMs. In this paper, we focus on the LLM-based generation of code for Answer Set Programming (ASP), a particularly effective approach for finding solutions to combinatorial search problems. The effectiveness of LLMs in ASP code generation is currently hindered by the limited number of examples seen during their initial pre-training phase. In this paper, we introduce a novel ASP-solver-in-the-loop approach for solver-guided instruction-tuning of LLMs to addressing the highly complex semantic parsing task inherent in ASP code generation. Our method only requires problem specifications in natural language and their solutions. Specifically, we sample ASP statements for program continuations from LLMs for unriddling logic puzzles. Leveraging the special property of declarative ASP programming that partial encodings increasingly narrow down the solution space, we categorize them into chosen and rejected instances based on solver feedback. We then apply supervised fine-tuning to train LLMs on the curated data and further improve robustness using a solver-guided search that includes best-of-N sampling. Our experiments demonstrate consistent improvements in two distinct prompting settings on two datasets.
Mining the Mind: What 100M Beliefs Reveal About Frontier LLM Knowledge
Oct 08, 2025



LLMs are remarkable artifacts that have revolutionized a range of NLP and AI tasks. A significant contributor is their factual knowledge, which, to date, remains poorly understood, and is usually analyzed from biased samples. In this paper, we take a deep tour into the factual knowledge (or beliefs) of a frontier LLM, based on GPTKB v1.5 (Hu et al., 2025a), a recursively elicited set of 100 million beliefs of one of the strongest currently available frontier LLMs, GPT-4.1. We find that the models' factual knowledge differs quite significantly from established knowledge bases, and that its accuracy is significantly lower than indicated by previous benchmarks. We also find that inconsistency, ambiguity and hallucinations are major issues, shedding light on future research opportunities concerning factual LLM knowledge.
PEDANTIC: A Dataset for the Automatic Examination of Definiteness in Patent Claims
May 28, 2025


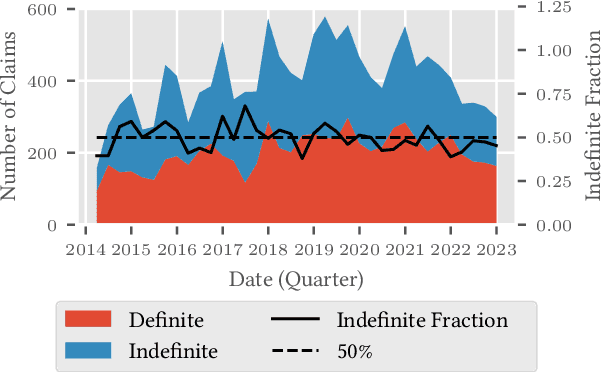
Patent claims define the scope of protection for an invention. If there are ambiguities in a claim, it is rejected by the patent office. In the US, this is referred to as indefiniteness (35 U.S.C {\S} 112(b)) and is among the most frequent reasons for patent application rejection. The development of automatic methods for patent definiteness examination has the potential to make patent drafting and examination more efficient, but no annotated dataset has been published to date. We introduce PEDANTIC (Patent Definiteness Examination Corpus), a novel dataset of 14k US patent claims from patent applications relating to Natural Language Processing (NLP), annotated with reasons for indefiniteness. We construct PEDANTIC using a fully automatic pipeline that retrieves office action documents from the USPTO and uses Large Language Models (LLMs) to extract the reasons for indefiniteness. A human validation study confirms the pipeline's accuracy in generating high-quality annotations. To gain insight beyond binary classification metrics, we implement an LLM-as-Judge evaluation that compares the free-form reasoning of every model-cited reason with every examiner-cited reason. We show that LLM agents based on Qwen 2.5 32B and 72B struggle to outperform logistic regression baselines on definiteness prediction, even though they often correctly identify the underlying reasons. PEDANTIC provides a valuable resource for patent AI researchers, enabling the development of advanced examination models. We will publicly release the dataset and code.
GPTKB: Building Very Large Knowledge Bases from Language Models
Nov 07, 2024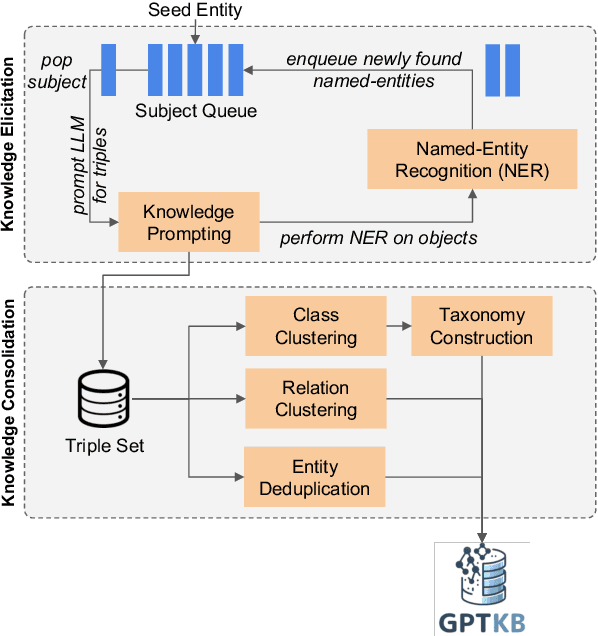
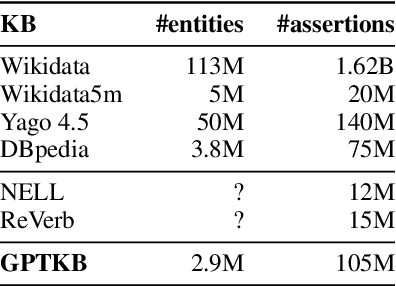
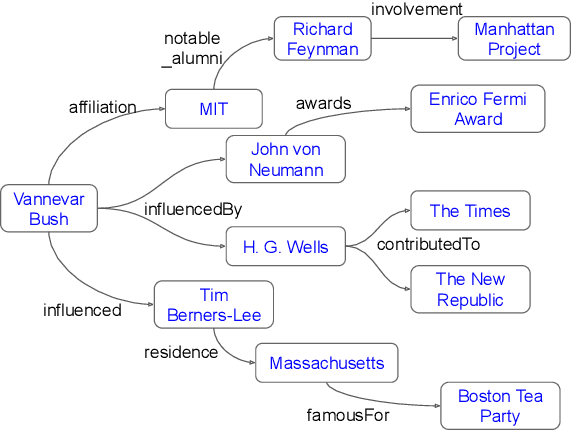

General-domain knowledge bases (KB), in particular the "big three" -- Wikidata, Yago and DBpedia -- are the backbone of many intelligent applications. While these three have seen steady development, comprehensive KB construction at large has seen few fresh attempts. In this work, we propose to build a large general-domain KB entirely from a large language model (LLM). We demonstrate the feasibility of large-scale KB construction from LLMs, while highlighting specific challenges arising around entity recognition, entity and property canonicalization, and taxonomy construction. As a prototype, we use GPT-4o-mini to construct GPTKB, which contains 105 million triples for more than 2.9 million entities, at a cost 100x less than previous KBC projects. Our work is a landmark for two fields: For NLP, for the first time, it provides \textit{constructive} insights into the knowledge (or beliefs) of LLMs. For the Semantic Web, it shows novel ways forward for the long-standing challenge of general-domain KB construction. GPTKB is accessible at https://gptkb.org.
QUITE: Quantifying Uncertainty in Natural Language Text in Bayesian Reasoning Scenarios
Oct 14, 2024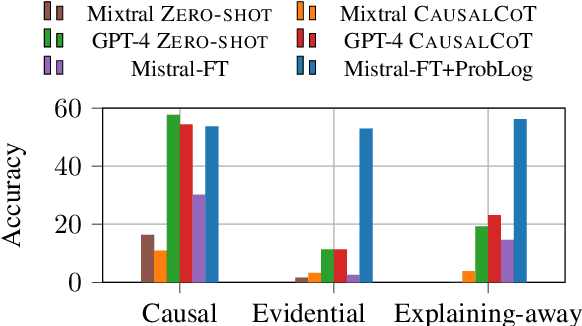
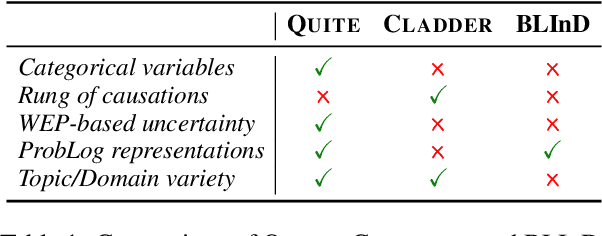
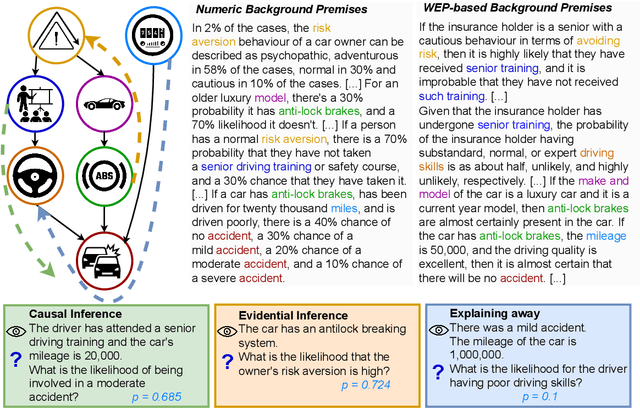
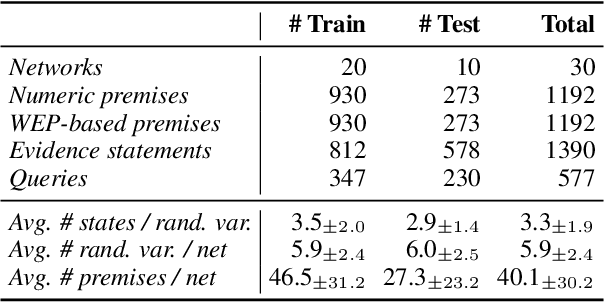
Reasoning is key to many decision making processes. It requires consolidating a set of rule-like premises that are often associated with degrees of uncertainty and observations to draw conclusions. In this work, we address both the case where premises are specified as numeric probabilistic rules and situations in which humans state their estimates using words expressing degrees of certainty. Existing probabilistic reasoning datasets simplify the task, e.g., by requiring the model to only rank textual alternatives, by including only binary random variables, or by making use of a limited set of templates that result in less varied text. In this work, we present QUITE, a question answering dataset of real-world Bayesian reasoning scenarios with categorical random variables and complex relationships. QUITE provides high-quality natural language verbalizations of premises together with evidence statements and expects the answer to a question in the form of an estimated probability. We conduct an extensive set of experiments, finding that logic-based models outperform out-of-the-box large language models on all reasoning types (causal, evidential, and explaining-away). Our results provide evidence that neuro-symbolic models are a promising direction for improving complex reasoning. We release QUITE and code for training and experiments on Github.
Pap2Pat: Towards Automated Paper-to-Patent Drafting using Chunk-based Outline-guided Generation
Oct 09, 2024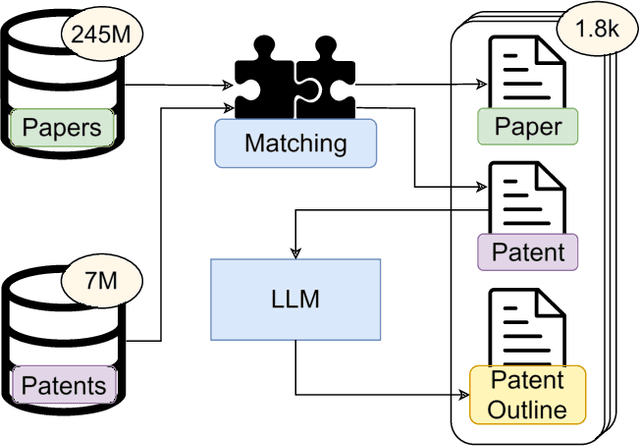
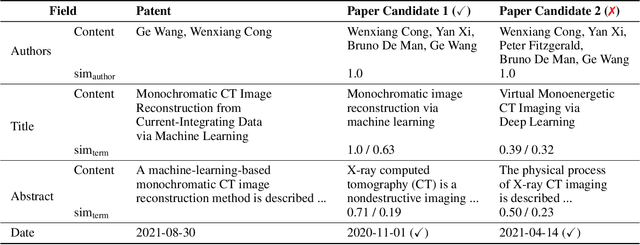


The patent domain is gaining attention in natural language processing research, offering practical applications in streamlining the patenting process and providing challenging benchmarks for large language models (LLMs). However, the generation of the description sections of patents, which constitute more than 90% of the patent document, has not been studied to date. We address this gap by introducing the task of outline-guided paper-to-patent generation, where an academic paper provides the technical specification of the invention and an outline conveys the desired patent structure. We present PAP2PAT, a new challenging benchmark of 1.8k patent-paper pairs with document outlines, collected using heuristics that reflect typical research lab practices. Our experiments with current open-weight LLMs and outline-guided chunk-based generation show that they can effectively use information from the paper but struggle with repetitions, likely due to the inherent repetitiveness of patent language. We release our data and code.
Recall Them All: Retrieval-Augmented Language Models for Long Object List Extraction from Long Documents
May 04, 2024



Methods for relation extraction from text mostly focus on high precision, at the cost of limited recall. High recall is crucial, though, to populate long lists of object entities that stand in a specific relation with a given subject. Cues for relevant objects can be spread across many passages in long texts. This poses the challenge of extracting long lists from long texts. We present the L3X method which tackles the problem in two stages: (1) recall-oriented generation using a large language model (LLM) with judicious techniques for retrieval augmentation, and (2) precision-oriented scrutinization to validate or prune candidates. Our L3X method outperforms LLM-only generations by a substantial margin.