 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CLEF-2026 CheckThat! Lab: Advancing Multilingual Fact-Checking
Feb 10, 2026The CheckThat! lab aims to advance the development of innovative technologies combating disinformation and manipulation efforts in online communication across a multitude of languages and platforms. While in early editions the focus has been on core tasks of the verification pipeline (check-worthiness, evidence retrieval, and verification), in the past three editions, the lab added additional tasks linked to the verification process. In this year's edition, the verification pipeline is at the center again with the following tasks: Task 1 on source retrieval for scientific web claims (a follow-up of the 2025 edition), Task 2 on fact-checking numerical and temporal claims, which adds a reasoning component to the 2025 edition, and Task 3, which expands the verification pipeline with generation of full-fact-checking articles. These tasks represent challenging classification and retrieval problems as well as generation challenges at the document and span level, including multilingual settings.
GSAP-ERE: Fine-Grained Scholarly Entity and Relation Extraction Focused on Machine Learning
Nov 12, 2025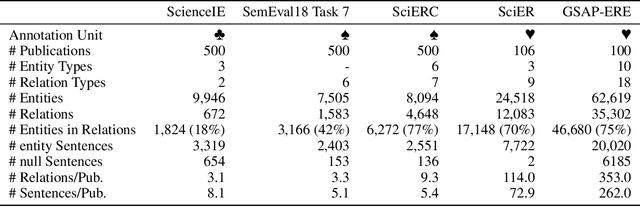
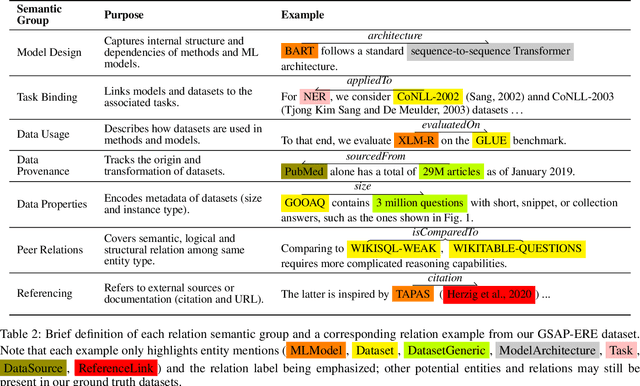
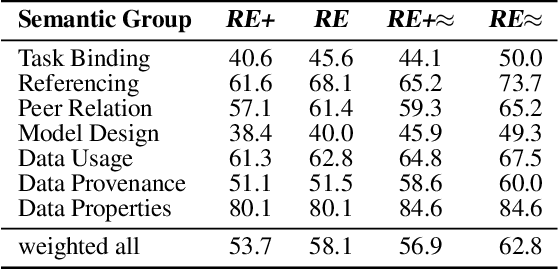
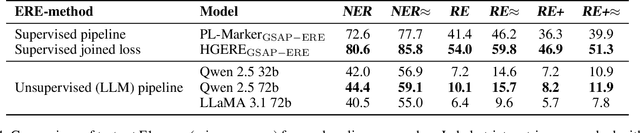
Research in Machine Learning (ML) and AI evolves rapidly. Information Extraction (IE) from scientific publications enables to identify information about research concepts and resources on a large scale and therefore is a pathway to improve understanding and reproducibility of ML-related research. To extract and connect fine-grained information in ML-related research, e.g. method training and data usage, we introduce GSAP-ERE. It is a manually curated fine-grained dataset with 10 entity types and 18 semantically categorized relation types, containing mentions of 63K entities and 35K relations from the full text of 100 ML publications. We show that our dataset enables fine-tuned models to automatically extract information relevant for downstream tasks ranging from knowledge graph (KG) construction, to monitoring the computational reproducibility of AI research at scale. Additionally, we use our dataset as a test suite to explore prompting strategies for IE using Large Language Models (LLM). We observe that the performance of state-of-the-art LLM prompting methods is largely outperformed by our best fine-tuned baseline model (NER: 80.6%, RE: 54.0% for the fine-tuned model vs. NER: 44.4%, RE: 10.1% for the LLM). This disparity of performance between supervised models and unsupervised usage of LLMs suggests datasets like GSAP-ERE are needed to advance research in the domain of scholarly information extraction.
NFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
Research Knowledge Graphs: the Shifting Paradigm of Scholarly Information Representation
Jun 08, 2025Sharing and reusing research artifacts, such as datasets, publications, or methods is a fundamental part of scientific activity, where heterogeneity of resources and metadata and the common practice of capturing information in unstructured publications pose crucial challenges. Reproducibility of research and finding state-of-the-art methods or data have become increasingly challenging. In this context, the concept of Research Knowledge Graphs (RKGs) has emerged, aiming at providing an easy to use and machine-actionable representation of research artifacts and their relations. That is facilitated through the use of established principles for data representation, the consistent adoption of globally unique persistent identifiers and the reuse and linking of vocabularies and data. This paper provides the first conceptualisation of the RKG vision, a categorisation of in-use RKGs together with a description of RKG building blocks and principles. We also survey real-world RKG implementations differing with respect to scale, schema, data, used vocabulary, and reliability of the contained data. We also characterise different RKG construction methodologies and provide a forward-looking perspective on the diverse applications, opportunities, and challenges associated with the RKG vision.
Limited Generalizability in Argument Mining: State-Of-The-Art Models Learn Datasets, Not Arguments
May 28, 2025Identifying arguments is a necessary prerequisite for various tasks in automated discourse analysis, particularly within contexts such as political debates, online discussions, and scientific reasoning. In addition to theoretical advances in understanding the constitution of arguments, a significant body of research has emerged around practical argument mining, supported by a growing number of publicly available datasets. On these benchmarks, BERT-like transformers have consistently performed best, reinforcing the belief that such models are broadly applicable across diverse contexts of debate. This study offers the first large-scale re-evaluation of such state-of-the-art models, with a specific focus on their ability to generalize in identifying arguments. We evaluate four transformers, three standard and one enhanced with contrastive pre-training for better generalization, on 17 English sentence-level datasets as most relevant to the task. Our findings show that, to varying degrees, these models tend to rely on lexical shortcuts tied to content words, suggesting that apparent progress may often be driven by dataset-specific cues rather than true task alignment. While the models achieve strong results on familiar benchmarks, their performance drops markedly when applied to unseen datasets. Nonetheless, incorporating both task-specific pre-training and joint benchmark training proves effective in enhancing both robustness and generalization.
The CLEF-2025 CheckThat! Lab: Subjectivity, Fact-Checking, Claim Normalization, and Retrieval
Mar 19, 2025The CheckThat! lab aims to advance the development of innovative technologies designed to identify and counteract online disinformation and manipulation efforts across various languages and platforms. The first five editions focused on key tasks in the information verification pipeline, including check-worthiness, evidence retrieval and pairing, and verification. Since the 2023 edition, the lab has expanded its scope to address auxiliary tasks that support research and decision-making in verification. In the 2025 edition, the lab revisits core verification tasks while also considering auxiliary challenges. Task 1 focuses on the identification of subjectivity (a follow-up from CheckThat! 2024), Task 2 addresses claim normalization, Task 3 targets fact-checking numerical claims, and Task 4 explores scientific web discourse processing. These tasks present challenging classification and retrieval problems at both the document and span levels, including multilingual settings.
Hidden Entity Detection from GitHub Leveraging Large Language Models
Jan 08, 2025Named entity recognition is an important task when constructing knowledge bases from unstructured data sources. Whereas entity detection methods mostly rely on extensive training data, Large Language Models (LLMs) have paved the way towards approaches that rely on zero-shot learning (ZSL) or few-shot learning (FSL) by taking advantage of the capabilities LLMs acquired during pretraining. Specifically, in very specialized scenarios where large-scale training data is not available, ZSL / FSL opens new opportunities. This paper follows this recent trend and investigates the potential of leveraging Large Language Models (LLMs) in such scenarios to automatically detect datasets and software within textual content from GitHub repositories. While existing methods focused solely on named entities, this study aims to broaden the scope by incorporating resources such as repositories and online hubs where entities are also represented by URLs. The study explores different FSL prompt learning approaches to enhance the LLMs' ability to identify dataset and software mentions within repository texts. Through analyses of LLM effectiveness and learning strategies, this paper offers insights into the potential of advanced language models for automated entity detection.
Multi-Level Sequence Denoising with Cross-Signal Contrastive Learning for Sequential Recommendation
Apr 22, 2024Sequential recommender systems (SRSs) aim to suggest next item for a user based on her historical interaction sequences. Recently, many research efforts have been devoted to attenuate the influence of noisy items in sequences by either assigning them with lower attention weights or discarding them directly. The major limitation of these methods is that the former would still prone to overfit noisy items while the latter may overlook informative items. To the end, in this paper, we propose a novel model named Multi-level Sequence Denoising with Cross-signal Contrastive Learning (MSDCCL) for sequential recommendation. To be specific, we first introduce a target-aware user interest extractor to simultaneously capture users' long and short term interest with the guidance of target items. Then, we develop a multi-level sequence denoising module to alleviate the impact of noisy items by employing both soft and hard signal denoising strategies. Additionally, we extend existing curriculum learning by simulating the learning pattern of human beings. It is worth noting that our proposed model can be seamlessly integrated with a majority of existing recommendation models and significantly boost their effectiveness. Experimental studies on five public datasets are conducted and the results demonstrate that the proposed MSDCCL is superior to the state-of-the-art baselines. The source code is publicly available at https://github.com/lalunex/MSDCCL/tree/main.
Toward FAIR Semantic Publishing of Research Dataset Metadata in the Open Research Knowledge Graph
Apr 12, 2024Search engines these days can serve datasets as search results. Datasets get picked up by search technologies based on structured descriptions on their official web pages, informed by metadata ontologies such as the Dataset content type of schema.org. Despite this promotion of the content type dataset as a first-class citizen of search results, a vast proportion of datasets, particularly research datasets, still need to be made discoverable and, therefore, largely remain unused. This is due to the sheer volume of datasets released every day and the inability of metadata to reflect a dataset's content and context accurately. This work seeks to improve this situation for a specific class of datasets, namely research datasets, which are the result of research endeavors and are accompanied by a scholarly publication. We propose the ORKG-Dataset content type, a specialized branch of the Open Research Knowledge Graoh (ORKG) platform, which provides descriptive information and a semantic model for research datasets, integrating them with their accompanying scholarly publications. This work aims to establish a standardized framework for recording and reporting research datasets within the ORKG-Dataset content type. This, in turn, increases research dataset transparency on the web for their improved discoverability and applied use. In this paper, we present a proposal -- the minimum FAIR, comparable, semantic description of research datasets in terms of salient properties of their supporting publication. We design a specific application of the ORKG-Dataset semantic model based on 40 diverse research datasets on scientific information extraction.
* 8 pages, 1 figure, published in the Joint Proceedings of the Onto4FAIR 2023 Workshops
Enhancing Software Related Information Extraction with Generative Language Models through Single-Choice Question Answering
Apr 08, 2024This paper describes our participation in the Shared Task on Software Mentions Disambiguation (SOMD), with a focus on improving relation extraction in scholarly texts through Generative Language Models (GLMs) using single-choice question-answering. The methodology prioritises the use of in-context learning capabilities of GLMs to extract software-related entities and their descriptive attributes, such as distributive information. Our approach uses Retrieval-Augmented Generation (RAG) techniques and GLMs for Named Entity Recognition (NER) and Attributive NER to identify relationships between extracted software entities, providing a structured solution for analysing software citations in academic literature. The paper provides a detailed description of our approach, demonstrating how using GLMs in a single-choice QA paradigm can greatly enhance IE methodologies. Our participation in the SOMD shared task highlights the importance of precise software citation practices and showcases our system's ability to overcome the challenges of disambiguating and extracting relationships between software mentions. This sets the groundwork for future research and development in this field.