 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Entity Detection from GitHub Leveraging Large Language Models
Jan 08, 2025Named entity recognition is an important task when constructing knowledge bases from unstructured data sources. Whereas entity detection methods mostly rely on extensive training data, Large Language Models (LLMs) have paved the way towards approaches that rely on zero-shot learning (ZSL) or few-shot learning (FSL) by taking advantage of the capabilities LLMs acquired during pretraining. Specifically, in very specialized scenarios where large-scale training data is not available, ZSL / FSL opens new opportunities. This paper follows this recent trend and investigates the potential of leveraging Large Language Models (LLMs) in such scenarios to automatically detect datasets and software within textual content from GitHub repositories. While existing methods focused solely on named entities, this study aims to broaden the scope by incorporating resources such as repositories and online hubs where entities are also represented by URLs. The study explores different FSL prompt learning approaches to enhance the LLMs' ability to identify dataset and software mentions within repository texts. Through analyses of LLM effectiveness and learning strategies, this paper offers insights into the potential of advanced language models for automated entity detection.
SchenQL: A query language for bibliographic data with aggregations and domain-specific functions
May 13, 2022

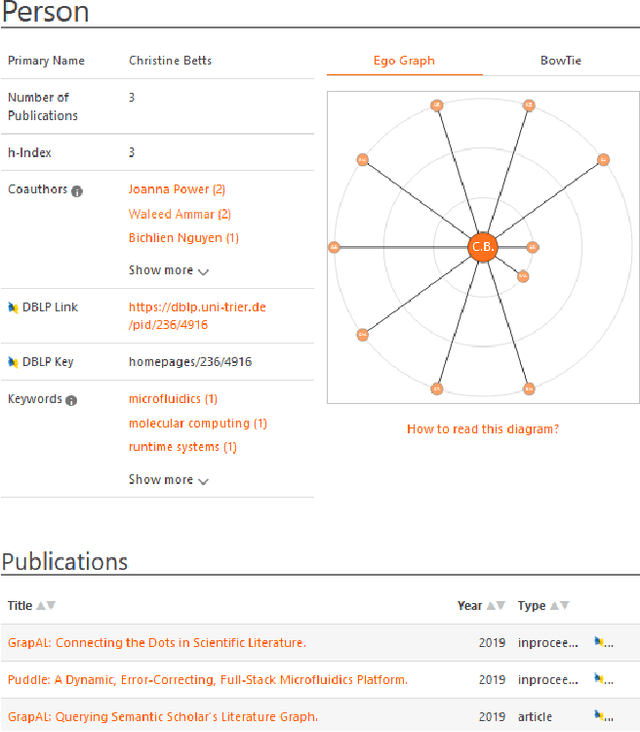

Current search interfaces of digital libraries are not suitable to satisfy complex or convoluted information needs directly, when it comes to cases such as "Find authors who only recently started working on a topic". They might offer possibilities to obtain this information only by requiring vast user interaction. We present SchenQL, a web interface of a domain-specific query language on bibliographic metadata, which offers information search and exploration by query formulation and navigation in the system. Our system focuses on supporting aggregation of data and providing specialised domain dependent functions while being suitable for domain experts as well as casual users of digital libraries.
Towards an Argument Mining Pipeline Transforming Texts to Argument Graphs
Jun 08, 2020


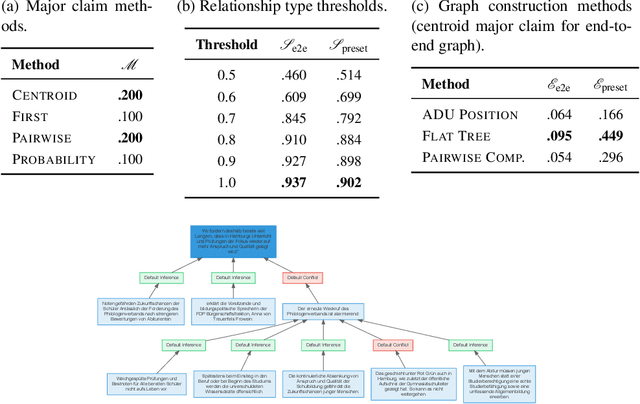
This paper targets the automated extraction of components of argumentative information and their relations from natural language text. Moreover, we address a current lack of systems to provide complete argumentative structure from arbitrary natural language text for general usage. We present an argument mining pipeline as a universally applicable approach for transforming German and English language texts to graph-based argument representations. We also introduce new methods for evaluating the results based on existing benchmark argument structures. Our results show that the generated argument graphs can be beneficial to detect new connections between different statements of an argumentative text. Our pipeline implementation is publicly available on GitHub.
Same Side Stance Classification Task: Facilitating Argument Stance Classification by Fine-tuning a BERT Model
Apr 23, 2020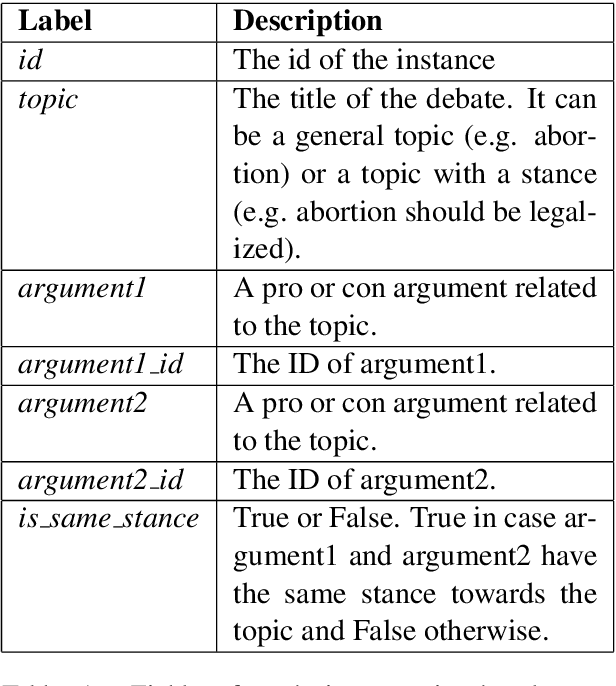
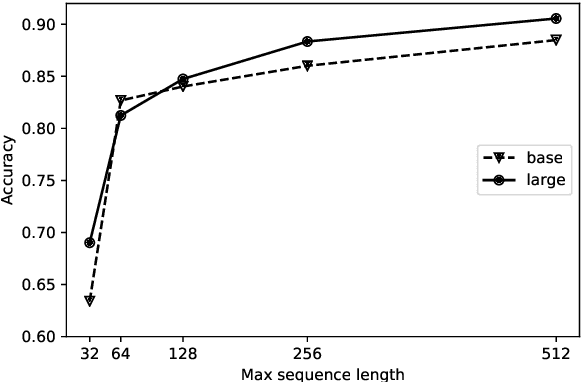
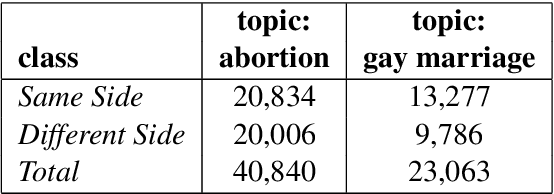
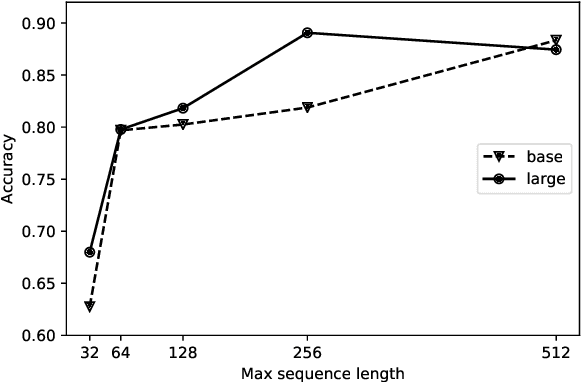
Research on computational argumentation is currently being intensively investigated. The goal of this community is to find the best pro and con arguments for a user given topic either to form an opinion for oneself, or to persuade others to adopt a certain standpoint. While existing argument mining methods can find appropriate arguments for a topic, a correct classification into pro and con is not yet reliable. The same side stance classification task provides a dataset of argument pairs classified by whether or not both arguments share the same stance and does not need to distinguish between topic-specific pro and con vocabulary but only the argument similarity within a stance needs to be assessed. The results of our contribution to the task are build on a setup based on the BERT architecture. We fine-tuned a pre-trained BERT model for three epochs and used the first 512 tokens of each argument to predict if two arguments share the same stance.