 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden Entity Detection from GitHub Leveraging Large Language Models
Jan 08, 2025Named entity recognition is an important task when constructing knowledge bases from unstructured data sources. Whereas entity detection methods mostly rely on extensive training data, Large Language Models (LLMs) have paved the way towards approaches that rely on zero-shot learning (ZSL) or few-shot learning (FSL) by taking advantage of the capabilities LLMs acquired during pretraining. Specifically, in very specialized scenarios where large-scale training data is not available, ZSL / FSL opens new opportunities. This paper follows this recent trend and investigates the potential of leveraging Large Language Models (LLMs) in such scenarios to automatically detect datasets and software within textual content from GitHub repositories. While existing methods focused solely on named entities, this study aims to broaden the scope by incorporating resources such as repositories and online hubs where entities are also represented by URLs. The study explores different FSL prompt learning approaches to enhance the LLMs' ability to identify dataset and software mentions within repository texts. Through analyses of LLM effectiveness and learning strategies, this paper offers insights into the potential of advanced language models for automated entity detection.
TF-IDF vs Word Embeddings for Morbidity Identification in Clinical Notes: An Initial Study
Jun 09, 2021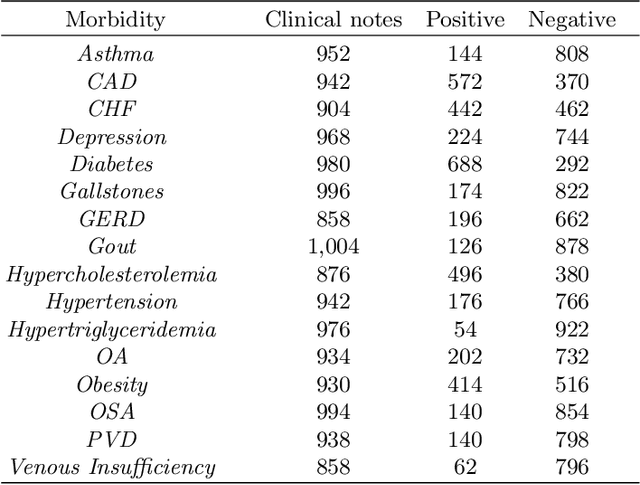
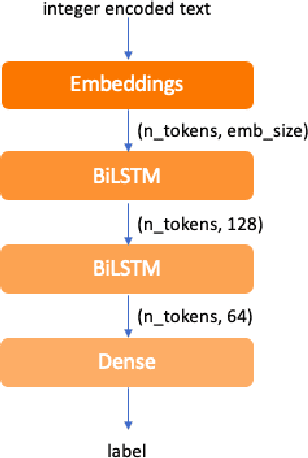
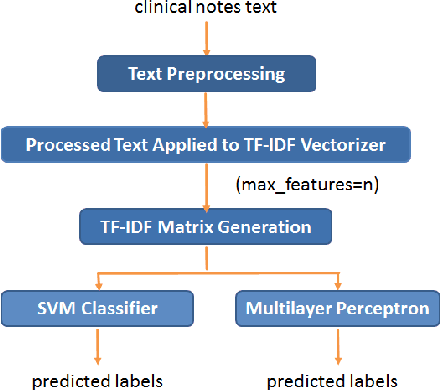
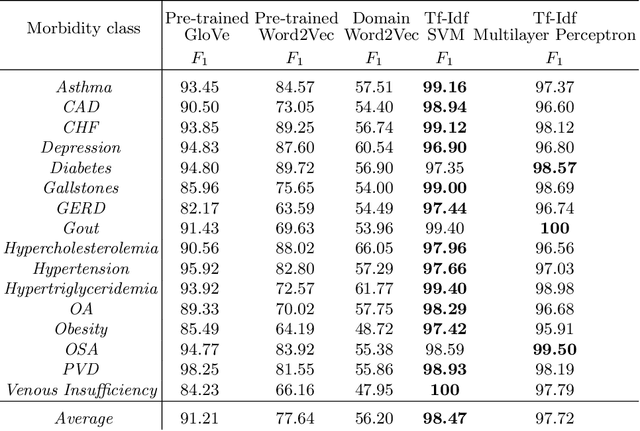
Today, we are seeing an ever-increasing number of clinical notes that contain clinical results, images, and textual descriptions of patient's health state. All these data can be analyzed and employed to cater novel services that can help people and domain experts with their common healthcare tasks. However, many technologies such as Deep Learning and tools like Word Embeddings have started to be investigated only recently, and many challenges remain open when it comes to healthcare domain applications. To address these challenges, we propose the use of Deep Learning and Word Embeddings for identifying sixteen morbidity types within textual descriptions of clinical records. For this purpose, we have used a Deep Learning model based on Bidirectional Long-Short Term Memory (LSTM) layers which can exploit state-of-the-art vector representations of data such as Word Embeddings. We have employed pre-trained Word Embeddings namely GloVe and Word2Vec, and our own Word Embeddings trained on the target domain. Furthermore, we have compared the performances of the deep learning approaches against the traditional tf-idf using Support Vector Machine and Multilayer perceptron (our baselines). From the obtained results it seems that the latter outperforms the combination of Deep Learning approaches using any word embeddings. Our preliminary results indicate that there are specific features that make the dataset biased in favour of traditional machine learning approaches.