 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWestWorld: A Knowledge-Encoded Scalable Trajectory World Model for Diverse Robotic Systems
Mar 15, 2026Trajectory world models play a crucial role in robotic dynamics learning, planning, and control. While recent works have explored trajectory world models for diverse robotic systems, they struggle to scale to a large number of distinct system dynamics and overlook domain knowledge of physical structures. To address these limitations, we introduce WestWorld, a knoWledge-Encoded Scalable Trajectory World model for diverse robotic systems. To tackle the scalability challenge, we propose a novel system-aware Mixture-of-Experts (Sys-MoE) that dynamically combines and routes specialized experts for different robotic systems via a learnable system embedding. To further enhance zero-shot generalization, we incorporate domain knowledge of robot physical structures by introducing a structural embedding that aligns trajectory representations with morphological information. After pretraining on 89 complex environments spanning diverse morphologies across both simulation and real-world settings, WestWorld achieves significant improvements over competitive baselines in zero- and few-shot trajectory prediction. Additionally, it shows strong scalability across a wide range of robotic environments and significantly improves performance on downstream model-based control for different robots. Finally, we deploy our model on a real-world Unitree Go1, where it demonstrates stable locomotion performance (see our demo on the website: https://westworldrobot.github.io/). The code will be available upon publication.
Interlayer Error Calibration for Stacked Intelligent Metasurfaces:Modeling, Algorithms, and Future Perspectives
Mar 09, 2026Stacked intelligent metasurfaces (SIMs) have recently emerged as a key enabler for realizing electromagnetic wave-domain signal processing in next-generation wireless networks. However, practical SIM implementations often suffer from noticeable mismatches between theoretical models and measured responses due to fabrication and assembly imperfections. This article systematically investigates the problem of interlayer error calibration in SIMs. We first classify representative modeling and hardware-induced imperfections. Then, we outline the major challenges in SIM calibration and further develop a general framework that integrates a calibration protocol with the relevant solution strategies. Moreover, we investigate the effectiveness of the multi-stage calibration approach in mitigating geometric deviations and improving the alignment between the calibrated and practical propagation coefficients. Finally, we elaborate on key research opportunities and practical challenges toward realizing physically consistent and hardware-compliant SIM implementations for future research.
A Generalizable Physics-guided Causal Model for Trajectory Prediction in Autonomous Driving
Feb 15, 2026Trajectory prediction for traffic agents is critical for safe autonomous driving. However, achieving effective zero-shot generalization in previously unseen domains remains a significant challenge. Motivated by the consistent nature of kinematics across diverse domains, we aim to incorporate domain-invariant knowledge to enhance zero-shot trajectory prediction capabilities. The key challenges include: 1) effectively extracting domain-invariant scene representations, and 2) integrating invariant features with kinematic models to enable generalized predictions. To address these challenges, we propose a novel generalizable Physics-guided Causal Model (PCM), which comprises two core components: a Disentangled Scene Encoder, which adopts intervention-based disentanglement to extract domain-invariant features from scenes, and a CausalODE Decoder, which employs a causal attention mechanism to effectively integrate kinematic models with meaningful contextual information. Extensive experiments on real-world autonomous driving datasets demonstrate our method's superior zero-shot generalization performance in unseen cities, significantly outperforming competitive baselines. The source code is released at https://github.com/ZY-Zong/Physics-guided-Causal-Model.
Bit-Efficient Quantisation for Two-Channel Modulo-Sampling Systems
Jan 20, 2026Two-channel modulo analog-to-digital converters (ADCs) enable high-dynamic-range signal sensing at the Nyquist rate per channel, but existing designs quantise both channel outputs independently, incurring redundant bitrate costs. This paper proposes a bit-efficient quantisation scheme that exploits the integer-valued structure of inter-channel differences, transmitting one quantised channel output together with a compact difference index. We prove that this approach requires only 1-2 bits per signal sample overhead relative to conventional ADCs, despite operating with a much smaller per-channel dynamic range. Simulations confirm the theoretical error bounds and bitrate analysis, while hardware experiments demonstrate substantial bitrate savings compared with existing modulo sampling schemes, while maintaining comparable reconstruction accuracy. These results highlight a practical path towards high-resolution, bandwidth-efficient modulo ADCs for bitrate-constrained systems.
SRU-Pix2Pix: A Fusion-Driven Generator Network for Medical Image Translation with Few-Shot Learning
Jan 08, 2026Magnetic Resonance Imaging (MRI) provides detailed tissue information, but its clinical application is limited by long acquisition time, high cost, and restricted resolution. Image translation has recently gained attention as a strategy to address these limitations. Although Pix2Pix has been widely applied in medical image translation, its potential has not been fully explored. In this study, we propose an enhanced Pix2Pix framework that integrates Squeeze-and-Excitation Residual Networks (SEResNet) and U-Net++ to improve image generation quality and structural fidelity. SEResNet strengthens critical feature representation through channel attention, while U-Net++ enhances multi-scale feature fusion. A simplified PatchGAN discriminator further stabilizes training and refines local anatomical realism. Experimental results demonstrate that under few-shot conditions with fewer than 500 images, the proposed method achieves consistent structural fidelity and superior image quality across multiple intra-modality MRI translation tasks, showing strong generalization ability. These results suggest an effective extension of Pix2Pix for medical image translation.
GSAP-ERE: Fine-Grained Scholarly Entity and Relation Extraction Focused on Machine Learning
Nov 12, 2025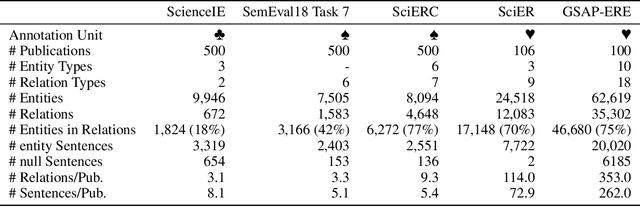
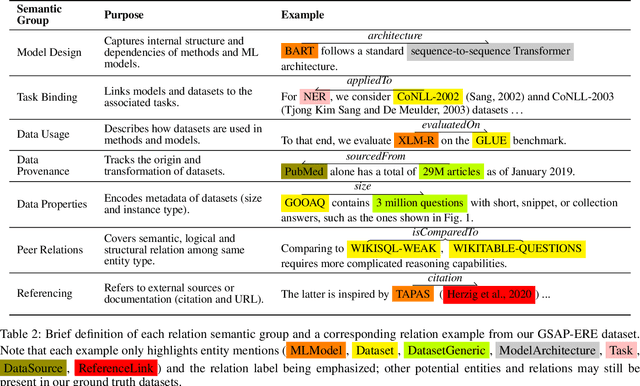
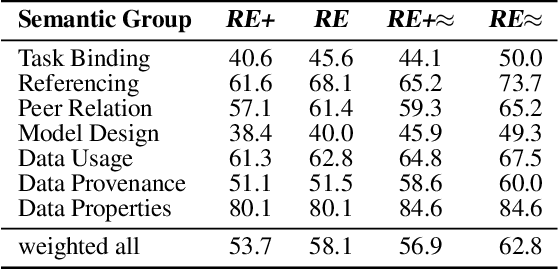
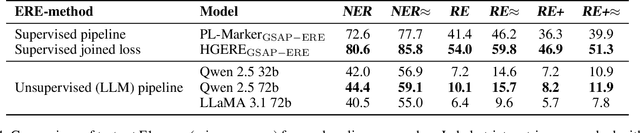
Research in Machine Learning (ML) and AI evolves rapidly. Information Extraction (IE) from scientific publications enables to identify information about research concepts and resources on a large scale and therefore is a pathway to improve understanding and reproducibility of ML-related research. To extract and connect fine-grained information in ML-related research, e.g. method training and data usage, we introduce GSAP-ERE. It is a manually curated fine-grained dataset with 10 entity types and 18 semantically categorized relation types, containing mentions of 63K entities and 35K relations from the full text of 100 ML publications. We show that our dataset enables fine-tuned models to automatically extract information relevant for downstream tasks ranging from knowledge graph (KG) construction, to monitoring the computational reproducibility of AI research at scale. Additionally, we use our dataset as a test suite to explore prompting strategies for IE using Large Language Models (LLM). We observe that the performance of state-of-the-art LLM prompting methods is largely outperformed by our best fine-tuned baseline model (NER: 80.6%, RE: 54.0% for the fine-tuned model vs. NER: 44.4%, RE: 10.1% for the LLM). This disparity of performance between supervised models and unsupervised usage of LLMs suggests datasets like GSAP-ERE are needed to advance research in the domain of scholarly information extraction.
Difference-Based Recovery for Modulo Sampling: Tightened Bounds and Robustness Guarantees
Sep 16, 2025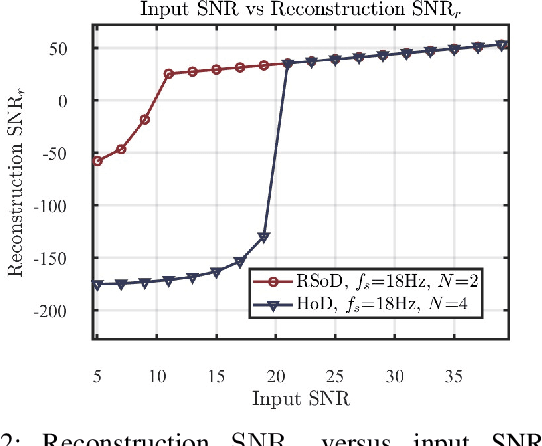
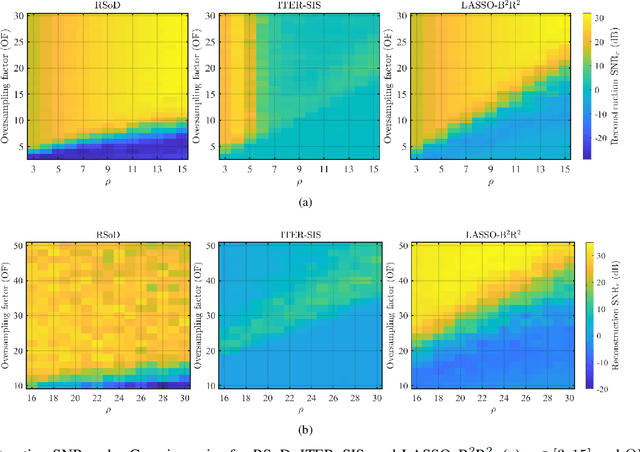
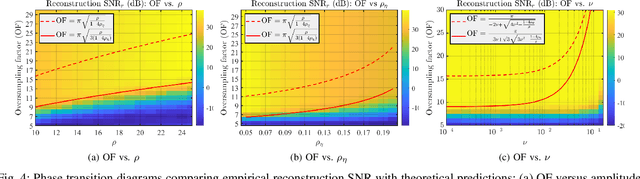
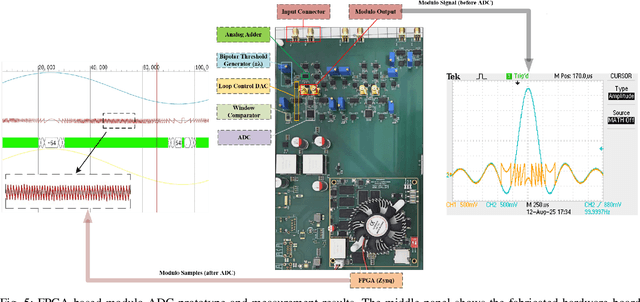
Conventional analog-to-digital converters (ADCs) clip when signals exceed their input range. Modulo (unlimited) sampling overcomes this limitation by folding the signal before digitization, but existing recovery methods are either computationally intensive or constrained by loose oversampling bounds that demand high sampling rates. In addition, none account for sampling jitter, which is unavoidable in practice. This paper revisits difference-based recovery and establishes new theoretical and practical guarantees. In the noiseless setting, we prove that arbitrarily high difference order reduces the sufficient oversampling factor from $2\pi e$ to $\pi$, substantially tightening classical bounds. For fixed order $N$, we derive a noise-aware sampling condition that guarantees stable recovery. For second-order difference-based recovery ($N=2$), we further extend the analysis to non-uniform sampling, proving robustness under bounded jitter. An FPGA-based hardware prototype demonstrates reliable reconstruction with amplitude expansion up to $\rho = 108$, confirming the feasibility of high-performance unlimited sensing with a simple and robust recovery pipeline.
Stacked Intelligent Metasurfaces for Multi-Modal Semantic Communications
Jun 14, 2025Semantic communication (SemCom) powered by generative artificial intelligence enables highly efficient and reliable information transmission. However, it still necessitates the transmission of substantial amounts of data when dealing with complex scene information. In contrast, the stacked intelligent metasurface (SIM), leveraging wave-domain computing, provides a cost-effective solution for directly imaging complex scenes. Building on this concept, we propose an innovative SIM-aided multi-modal SemCom system. Specifically, an SIM is positioned in front of the transmit antenna for transmitting visual semantic information of complex scenes via imaging on the uniform planar array at the receiver. Furthermore, the simple scene description that contains textual semantic information is transmitted via amplitude-phase modulation over electromagnetic waves. To simultaneously transmit multi-modal information, we optimize the amplitude and phase of meta-atoms in the SIM using a customized gradient descent algorithm. The optimization aims to gradually minimize the mean squared error between the normalized energy distribution on the receiver array and the desired pattern corresponding to the visual semantic information. By combining the textual and visual semantic information, a conditional generative adversarial network is used to recover the complex scene accurately. Extensive numerical results verify the effectiveness of the proposed multi-modal SemCom system in reducing bandwidth overhead as well as the capability of the SIM for imaging the complex scene.
Hyperspectral Gaussian Splatting
May 28, 2025Hyperspectral imaging (HSI) has been widely used in agricultural applications for non-destructive estimation of plant nutrient composition and precise determination of nutritional elements in samples. Recently, 3D reconstruction methods have been used to create implicit neural representations of HSI scenes, which can help localize the target object's nutrient composition spatially and spectrally. Neural Radiance Field (NeRF) is a cutting-edge implicit representation that can render hyperspectral channel compositions of each spatial location from any viewing direction. However, it faces limitations in training time and rendering speed. In this paper, we propose Hyperspectral Gaussian Splatting (HS-GS), which combines the state-of-the-art 3D Gaussian Splatting (3DGS) with a diffusion model to enable 3D explicit reconstruction of the hyperspectral scenes and novel view synthesis for the entire spectral range. To enhance the model's ability to capture fine-grained reflectance variations across the light spectrum and leverage correlations between adjacent wavelengths for denoising, we introduce a wavelength encoder to generate wavelength-specific spherical harmonics offsets. We also introduce a novel Kullback--Leibler divergence-based loss to mitigate the spectral distribution gap between the rendered image and the ground truth. A diffusion model is further applied for denoising the rendered images and generating photorealistic hyperspectral images. We present extensive evaluations on five diverse hyperspectral scenes from the Hyper-NeRF dataset to show the effectiveness of our proposed HS-GS framework. The results demonstrate that HS-GS achieves new state-of-the-art performance among all previously published methods. Code will be released upon publication.
GaussianFormer3D: Multi-Modal Gaussian-based Semantic Occupancy Prediction with 3D Deformable Attention
May 15, 2025
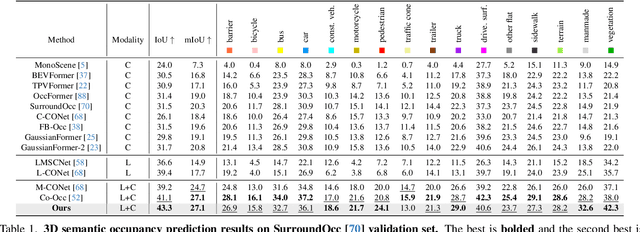
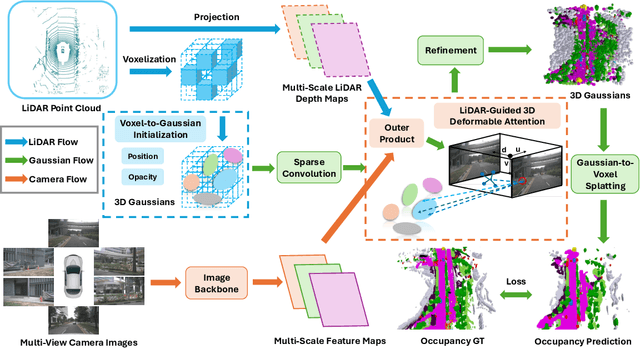
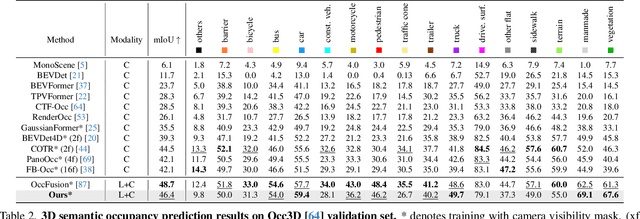
3D semantic occupancy prediction is critical for achieving safe and reliable autonomous driving. Compared to camera-only perception systems, multi-modal pipelines, especially LiDAR-camera fusion methods, can produce more accurate and detailed predictions. Although most existing works utilize a dense grid-based representation, in which the entire 3D space is uniformly divided into discrete voxels, the emergence of 3D Gaussians provides a compact and continuous object-centric representation. In this work, we propose a multi-modal Gaussian-based semantic occupancy prediction framework utilizing 3D deformable attention, named as GaussianFormer3D. We introduce a voxel-to-Gaussian initialization strategy to provide 3D Gaussians with geometry priors from LiDAR data, and design a LiDAR-guided 3D deformable attention mechanism for refining 3D Gaussians with LiDAR-camera fusion features in a lifted 3D space. We conducted extensive experiments on both on-road and off-road datasets, demonstrating that our GaussianFormer3D achieves high prediction accuracy that is comparable to state-of-the-art multi-modal fusion-based methods with reduced memory consumption and improved efficiency.