 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatics Meets Culture: Culturally-adapted Artwork Description Generation and Evaluation
Apr 02, 2026Language models are known to exhibit various forms of cultural bias in decision-making tasks, yet much less is known about their degree of cultural familiarity in open-ended text generation tasks. In this paper, we introduce the task of culturally-adapted art description generation, where models describe artworks for audiences from different cultural groups who vary in their familiarity with the cultural symbols and narratives embedded in the artwork. To evaluate cultural competence in this pragmatic generation task, we propose a framework based on culturally grounded question answering. We find that base models are only marginally adequate for this task, but, through a pragmatic speaker model, we can improve simulated listener comprehension by up to 8.2%. A human study further confirms that the model with higher pragmatic competence is rated as more helpful for comprehension by 8.0%.
Hyperspectral Gaussian Splatting
May 28, 2025Hyperspectral imaging (HSI) has been widely used in agricultural applications for non-destructive estimation of plant nutrient composition and precise determination of nutritional elements in samples. Recently, 3D reconstruction methods have been used to create implicit neural representations of HSI scenes, which can help localize the target object's nutrient composition spatially and spectrally. Neural Radiance Field (NeRF) is a cutting-edge implicit representation that can render hyperspectral channel compositions of each spatial location from any viewing direction. However, it faces limitations in training time and rendering speed. In this paper, we propose Hyperspectral Gaussian Splatting (HS-GS), which combines the state-of-the-art 3D Gaussian Splatting (3DGS) with a diffusion model to enable 3D explicit reconstruction of the hyperspectral scenes and novel view synthesis for the entire spectral range. To enhance the model's ability to capture fine-grained reflectance variations across the light spectrum and leverage correlations between adjacent wavelengths for denoising, we introduce a wavelength encoder to generate wavelength-specific spherical harmonics offsets. We also introduce a novel Kullback--Leibler divergence-based loss to mitigate the spectral distribution gap between the rendered image and the ground truth. A diffusion model is further applied for denoising the rendered images and generating photorealistic hyperspectral images. We present extensive evaluations on five diverse hyperspectral scenes from the Hyper-NeRF dataset to show the effectiveness of our proposed HS-GS framework. The results demonstrate that HS-GS achieves new state-of-the-art performance among all previously published methods. Code will be released upon publication.
A Necessary Step toward Faithfulness: Measuring and Improving Consistency in Free-Text Explanations
May 25, 2025



Faithful free-text explanations are important to ensure transparency in high-stakes AI decision-making contexts, but they are challenging to generate by language models and assess by humans. In this paper, we present a measure for Prediction-EXplanation (PEX) consistency, by extending the concept of weight of evidence. This measure quantifies how much a free-text explanation supports or opposes a prediction, serving as an important aspect of explanation faithfulness. Our analysis reveals that more than 62% explanations generated by large language models lack this consistency. We show that applying direct preference optimization improves the consistency of generated explanations across three model families, with improvement ranging from 43.1% to 292.3%. Furthermore, we demonstrate that optimizing this consistency measure can improve explanation faithfulness by up to 9.7%.
GaussianFormer3D: Multi-Modal Gaussian-based Semantic Occupancy Prediction with 3D Deformable Attention
May 15, 2025
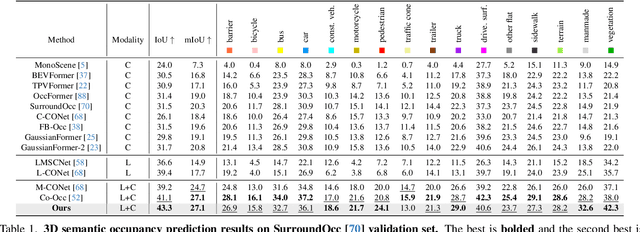
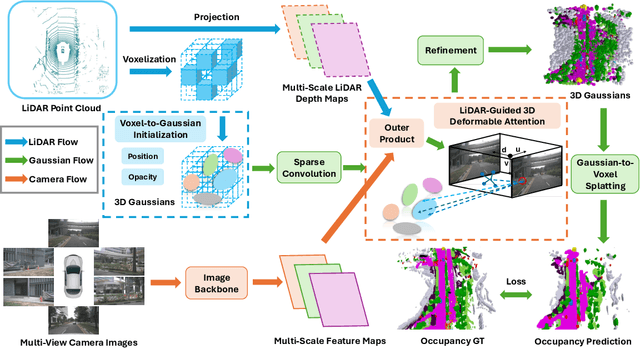
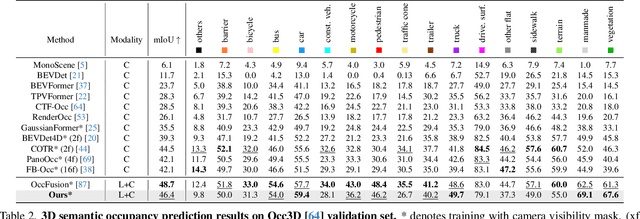
3D semantic occupancy prediction is critical for achieving safe and reliable autonomous driving. Compared to camera-only perception systems, multi-modal pipelines, especially LiDAR-camera fusion methods, can produce more accurate and detailed predictions. Although most existing works utilize a dense grid-based representation, in which the entire 3D space is uniformly divided into discrete voxels, the emergence of 3D Gaussians provides a compact and continuous object-centric representation. In this work, we propose a multi-modal Gaussian-based semantic occupancy prediction framework utilizing 3D deformable attention, named as GaussianFormer3D. We introduce a voxel-to-Gaussian initialization strategy to provide 3D Gaussians with geometry priors from LiDAR data, and design a LiDAR-guided 3D deformable attention mechanism for refining 3D Gaussians with LiDAR-camera fusion features in a lifted 3D space. We conducted extensive experiments on both on-road and off-road datasets, demonstrating that our GaussianFormer3D achieves high prediction accuracy that is comparable to state-of-the-art multi-modal fusion-based methods with reduced memory consumption and improved efficiency.
MTSGL: Multi-Task Structure Guided Learning for Robust and Interpretable SAR Aircraft Recognition
Apr 23, 2025



Aircraft recognition in synthetic aperture radar (SAR) imagery is a fundamental mission in both military and civilian applications. Recently deep learning (DL) has emerged a dominant paradigm for its explosive performance on extracting discriminative features. However, current classification algorithms focus primarily on learning decision hyperplane without enough comprehension on aircraft structural knowledge. Inspired by the fined aircraft annotation methods for optical remote sensing images (RSI), we first introduce a structure-based SAR aircraft annotations approach to provide structural and compositional supplement information. On this basis, we propose a multi-task structure guided learning (MTSGL) network for robust and interpretable SAR aircraft recognition. Besides the classification task, MTSGL includes a structural semantic awareness (SSA) module and a structural consistency regularization (SCR) module. The SSA is designed to capture structure semantic information, which is conducive to gain human-like comprehension of aircraft knowledge. The SCR helps maintain the geometric consistency between the aircraft structure in SAR imagery and the proposed annotation. In this process, the structural attribute can be disentangled in a geometrically meaningful manner. In conclusion, the MTSGL is presented with the expert-level aircraft prior knowledge and structure guided learning paradigm, aiming to comprehend the aircraft concept in a way analogous to the human cognitive process. Extensive experiments are conducted on a self-constructed multi-task SAR aircraft recognition dataset (MT-SARD) and the effective results illustrate the superiority of robustness and interpretation ability of the proposed MTSGL.
Can Hallucination Correction Improve Video-Language Alignment?
Feb 20, 2025Large Vision-Language Models often generate hallucinated content that is not grounded in its visual inputs. While prior work focuses on mitigating hallucinations, we instead explore leveraging hallucination correction as a training objective to improve video-language alignment. We introduce HACA, a self-training framework learning to correct hallucinations in descriptions that do not align with the video content. By identifying and correcting inconsistencies, HACA enhances the model's ability to align video and textual representations for spatio-temporal reasoning. Our experimental results show consistent gains in video-caption binding and text-to-video retrieval tasks, demonstrating that hallucination correction-inspired tasks serve as an effective strategy for improving vision and language alignment.
CRKD: Enhanced Camera-Radar Object Detection with Cross-modality Knowledge Distillation
Mar 28, 2024



In the field of 3D object detection for autonomous driving, LiDAR-Camera (LC) fusion is the top-performing sensor configuration. Still, LiDAR is relatively high cost, which hinders adoption of this technology for consumer automobiles. Alternatively, camera and radar are commonly deployed on vehicles already on the road today, but performance of Camera-Radar (CR) fusion falls behind LC fusion. In this work, we propose Camera-Radar Knowledge Distillation (CRKD) to bridge the performance gap between LC and CR detectors with a novel cross-modality KD framework. We use the Bird's-Eye-View (BEV) representation as the shared feature space to enable effective knowledge distillation. To accommodate the unique cross-modality KD path, we propose four distillation losses to help the student learn crucial features from the teacher model. We present extensive evaluations on the nuScenes dataset to demonstrate the effectiveness of the proposed CRKD framework. The project page for CRKD is https://song-jingyu.github.io/CRKD.
Successfully Guiding Humans with Imperfect Instructions by Highlighting Potential Errors and Suggesting Corrections
Feb 26, 2024This paper addresses the challenge of leveraging imperfect language models to guide human decision-making in the context of a grounded navigation task. We show that an imperfect instruction generation model can be complemented with an effective communication mechanism to become more successful at guiding humans. The communication mechanism we build comprises models that can detect potential hallucinations in instructions and suggest practical alternatives, and an intuitive interface to present that information to users. We show that this approach reduces the human navigation error by up to 29% with no additional cognitive burden. This result underscores the potential of integrating diverse communication channels into AI systems to compensate for their imperfections and enhance their utility for humans.
LiRaFusion: Deep Adaptive LiDAR-Radar Fusion for 3D Object Detection
Feb 18, 2024



We propose LiRaFusion to tackle LiDAR-radar fusion for 3D object detection to fill the performance gap of existing LiDAR-radar detectors. To improve the feature extraction capabilities from these two modalities, we design an early fusion module for joint voxel feature encoding, and a middle fusion module to adaptively fuse feature maps via a gated network. We perform extensive evaluation on nuScenes to demonstrate that LiRaFusion leverages the complementary information of LiDAR and radar effectively and achieves notable improvement over existing methods.
Hallucination Detection for Grounded Instruction Generation
Oct 23, 2023



We investigate the problem of generating instructions to guide humans to navigate in simulated residential environments. A major issue with current models is hallucination: they generate references to actions or objects that are inconsistent with what a human follower would perform or encounter along the described path. We develop a model that detects these hallucinated references by adopting a model pre-trained on a large corpus of image-text pairs, and fine-tuning it with a contrastive loss that separates correct instructions from instructions containing synthesized hallucinations. Our final model outperforms several baselines, including using word probability estimated by the instruction-generation model, and supervised models based on LSTM and Transformer.