 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCritic: A Symbolic Evaluator for 3D Indoor Scene Synthesis
Apr 14, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) increasingly generate indoor scenes through intermediate structures such as layouts and scene graphs, yet evaluation still relies on LLM or VLM judges that score rendered views, making judgments sensitive to viewpoint, prompt phrasing, and hallucination. When the evaluator is unstable, it becomes difficult to determine whether a model has produced a spatially plausible scene or whether the output score reflects the choice of viewpoint, rendering, or prompt. We introduce SceneCritic, a symbolic evaluator for floor-plan-level layouts. SceneCritic's constraints are grounded in SceneOnto, a structured spatial ontology we construct by aggregating indoor scene priors from 3D-FRONT, ScanNet, and Visual Genome. SceneOnto traverses this ontology to jointly verify semantic, orientation, and geometric coherence across object relationships, providing object-level and relationship-level assessments that identify specific violations and successful placements. Furthermore, we pair SceneCritic with an iterative refinement test bed that probes how models build and revise spatial structure under different critic modalities: a rule-based critic using collision constraints as feedback, an LLM critic operating on the layout as text, and a VLM critic operating on rendered observations. Through extensive experiments, we show that (a) SceneCritic aligns substantially better with human judgments than VLM-based evaluators, (b) text-only LLMs can outperform VLMs on semantic layout quality, and (c) image-based VLM refinement is the most effective critic modality for semantic and orientation correction.
EgoGroups: A Benchmark For Detecting Social Groups of People in the Wild
Mar 23, 2026Social group detection, or the identification of humans involved in reciprocal interpersonal interactions (e.g., family members, friends, and customers and merchants), is a crucial component of social intelligence needed for agents transacting in the world. The few existing benchmarks for social group detection are limited by low scene diversity and reliance on third-person camera sources (e.g., surveillance footage). Consequently, these benchmarks generally lack real-world evaluation on how groups form and evolve in diverse cultural contexts and unconstrained settings. To address this gap, we introduce EgoGroups, a first-person view dataset that captures social dynamics in cities around the world. EgoGroups spans 65 countries covering low, medium, and high-crowd settings under four weather/time-of-day conditions. We include dense human annotations for person and social groups, along with rich geographic and scene metadata. Using this dataset, we performed an extensive evaluation of state-of-the-art VLM/LLMs and supervised models on their group detection capabilities. We found several interesting findings, including VLMs and LLMs can outperform supervised baselines in a zero-shot setting, while crowd density and cultural regions clearly influence model performance.
Do VLMs Need Vision Transformers? Evaluating State Space Models as Vision Encoders
Mar 19, 2026Large vision--language models (VLMs) often use a frozen vision backbone, whose image features are mapped into a large language model through a lightweight connector. While transformer-based encoders are the standard visual backbone, we ask whether state space model (SSM) vision backbones can be a strong alternative. We systematically evaluate SSM vision backbones for VLMs in a controlled setting. Under matched ImageNet-1K initialization, the SSM backbone achieves the strongest overall performance across both VQA and grounding/localization. We further adapt both SSM and ViT-family backbones with detection or segmentation training and find that dense-task tuning generally improves performance across families; after this adaptation, the SSM backbone remains competitive while operating at a substantially smaller model scale. We further observe that (i) higher ImageNet accuracy or larger backbones do not reliably translate into better VLM performance, and (ii) some visual backbones are unstable in localization. Based on these findings, we propose stabilization strategies that improve robustness for both backbone families and highlight SSM backbones as a strong alternative to transformer-based vision encoders in VLMs.
Can Hallucination Correction Improve Video-Language Alignment?
Feb 20, 2025Large Vision-Language Models often generate hallucinated content that is not grounded in its visual inputs. While prior work focuses on mitigating hallucinations, we instead explore leveraging hallucination correction as a training objective to improve video-language alignment. We introduce HACA, a self-training framework learning to correct hallucinations in descriptions that do not align with the video content. By identifying and correcting inconsistencies, HACA enhances the model's ability to align video and textual representations for spatio-temporal reasoning. Our experimental results show consistent gains in video-caption binding and text-to-video retrieval tasks, demonstrating that hallucination correction-inspired tasks serve as an effective strategy for improving vision and language alignment.
Natural Language Inference Improves Compositionality in Vision-Language Models
Oct 29, 2024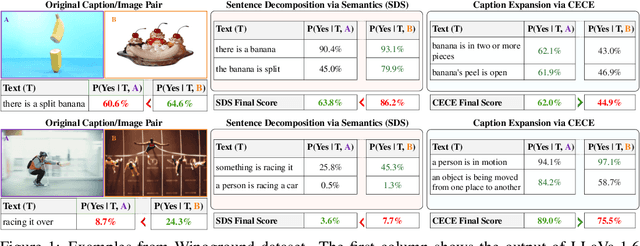
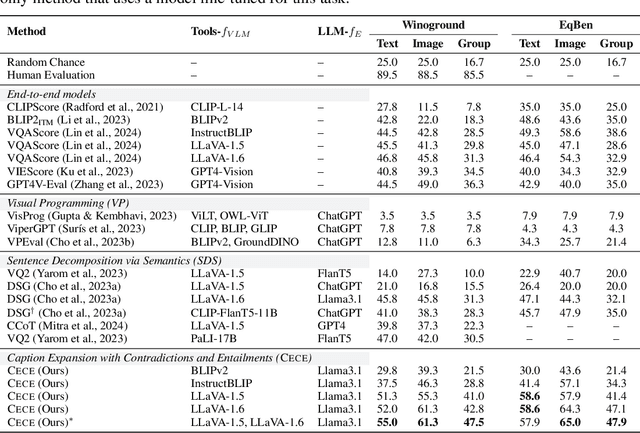
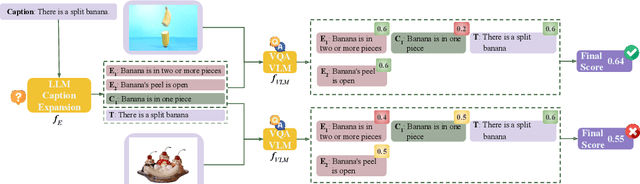

Compositional reasoning in Vision-Language Models (VLMs) remains challenging as these models often struggle to relate objects, attributes, and spatial relationships. Recent methods aim to address these limitations by relying on the semantics of the textual description, using Large Language Models (LLMs) to break them down into subsets of questions and answers. However, these methods primarily operate on the surface level, failing to incorporate deeper lexical understanding while introducing incorrect assumptions generated by the LLM. In response to these issues, we present Caption Expansion with Contradictions and Entailments (CECE), a principled approach that leverages Natural Language Inference (NLI) to generate entailments and contradictions from a given premise. CECE produces lexically diverse sentences while maintaining their core meaning. Through extensive experiments, we show that CECE enhances interpretability and reduces overreliance on biased or superficial features. By balancing CECE along the original premise, we achieve significant improvements over previous methods without requiring additional fine-tuning, producing state-of-the-art results on benchmarks that score agreement with human judgments for image-text alignment, and achieving an increase in performance on Winoground of +19.2% (group score) and +12.9% on EqBen (group score) over the best prior work (finetuned with targeted data).
PropTest: Automatic Property Testing for Improved Visual Programming
Mar 25, 2024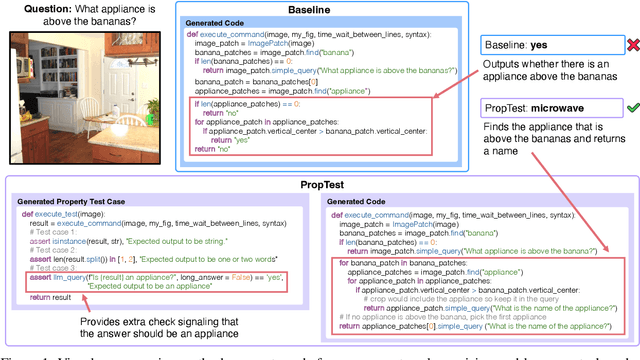
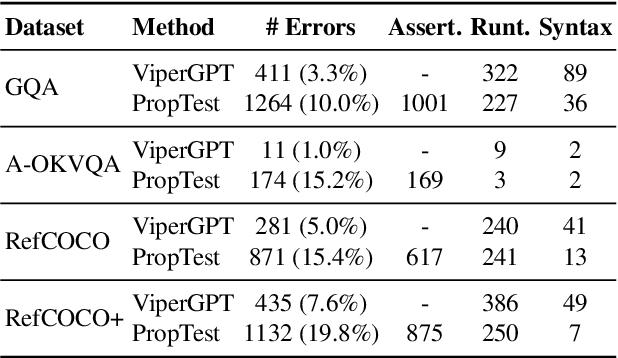
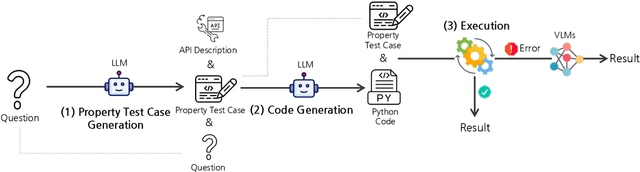
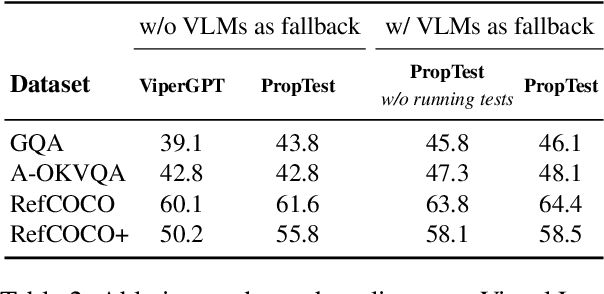
Visual Programming has emerged as an alternative to end-to-end black-box visual reasoning models. This type of methods leverage Large Language Models (LLMs) to decompose a problem and generate the source code for an executable computer program. This strategy has the advantage of offering an interpretable reasoning path and does not require finetuning a model with task-specific data. We propose PropTest, a general strategy that improves visual programming by further using an LLM to generate code that tests for visual properties in an initial round of proposed solutions. Particularly, our method tests for data-type consistency, as well as syntactic and semantic properties in the generated solutions. Our proposed solution outperforms baselines and achieves comparable results to state-of-the-art methods while using smaller and publicly available LLMs (CodeLlama-7B and WizardCoder-15B). This is demonstrated across different benchmarks on visual question answering and referring expression comprehension, showing the efficacy of our approach in enhancing the performance and generalization of visual reasoning tasks. Specifically, PropTest improves ViperGPT by obtaining 48.66% accuracy (+8.3%) on the A-OKVQA benchmark and 52.8% (+3.3%) on the RefCOCO+ benchmark using CodeLlama-7B.
Learning from Models and Data for Visual Grounding
Mar 20, 2024



We introduce SynGround, a novel framework that combines data-driven learning and knowledge transfer from various large-scale pretrained models to enhance the visual grounding capabilities of a pretrained vision-and-language model. The knowledge transfer from the models initiates the generation of image descriptions through an image description generator. These descriptions serve dual purposes: they act as prompts for synthesizing images through a text-to-image generator, and as queries for synthesizing text, from which phrases are extracted using a large language model. Finally, we leverage an open-vocabulary object detector to generate synthetic bounding boxes for the synthetic images and texts. We finetune a pretrained vision-and-language model on this dataset by optimizing a mask-attention consistency objective that aligns region annotations with gradient-based model explanations. The resulting model improves the grounding capabilities of an off-the-shelf vision-and-language model. Particularly, SynGround improves the pointing game accuracy of ALBEF on the Flickr30k dataset from 79.38% to 87.26%, and on RefCOCO+ Test A from 69.35% to 79.06% and on RefCOCO+ Test B from 53.77% to 63.67%.
Grounding Language Models for Visual Entity Recognition
Feb 28, 2024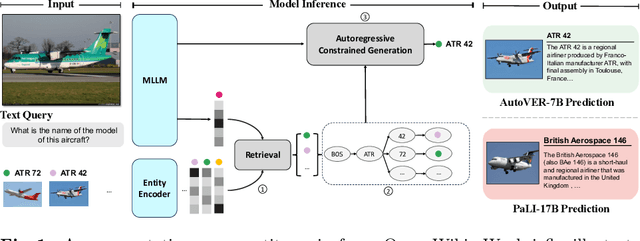
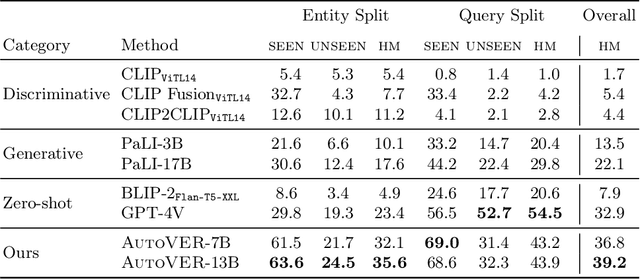
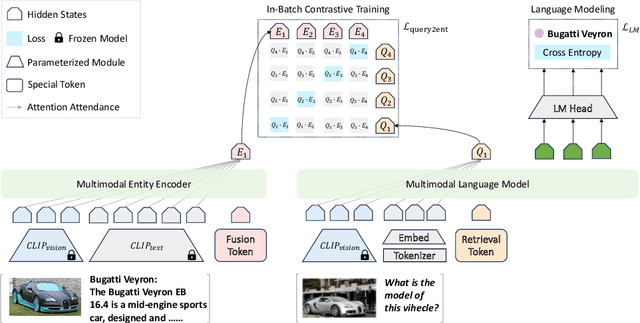
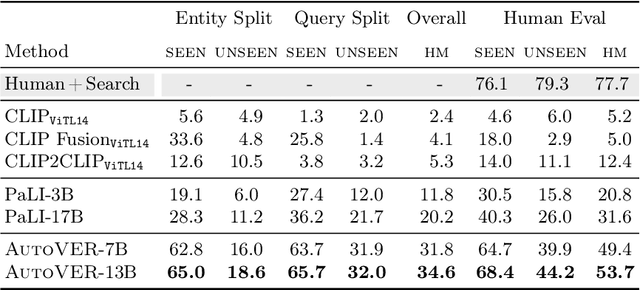
We introduce AutoVER, an Autoregressive model for Visual Entity Recognition. Our model extends an autoregressive Multi-modal Large Language Model by employing retrieval augmented constrained generation. It mitigates low performance on out-of-domain entities while excelling in queries that require visually-situated reasoning. Our method learns to distinguish similar entities within a vast label space by contrastively training on hard negative pairs in parallel with a sequence-to-sequence objective without an external retriever. During inference, a list of retrieved candidate answers explicitly guides language generation by removing invalid decoding paths. The proposed method achieves significant improvements across different dataset splits in the recently proposed Oven-Wiki benchmark. Accuracy on the Entity seen split rises from 32.7% to 61.5%. It also demonstrates superior performance on the unseen and query splits by a substantial double-digit margin.
Improved Visual Grounding through Self-Consistent Explanations
Dec 07, 2023Vision-and-language models trained to match images with text can be combined with visual explanation methods to point to the locations of specific objects in an image. Our work shows that the localization --"grounding"-- abilities of these models can be further improved by finetuning for self-consistent visual explanations. We propose a strategy for augmenting existing text-image datasets with paraphrases using a large language model, and SelfEQ, a weakly-supervised strategy on visual explanation maps for paraphrases that encourages self-consistency. Specifically, for an input textual phrase, we attempt to generate a paraphrase and finetune the model so that the phrase and paraphrase map to the same region in the image. We posit that this both expands the vocabulary that the model is able to handle, and improves the quality of the object locations highlighted by gradient-based visual explanation methods (e.g. GradCAM). We demonstrate that SelfEQ improves performance on Flickr30k, ReferIt, and RefCOCO+ over a strong baseline method and several prior works. Particularly, comparing to other methods that do not use any type of box annotations, we obtain 84.07% on Flickr30k (an absolute improvement of 4.69%), 67.40% on ReferIt (an absolute improvement of 7.68%), and 75.10%, 55.49% on RefCOCO+ test sets A and B respectively (an absolute improvement of 3.74% on average).
Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Mar 30, 2023



Large-scale pre-trained Vision & Language (VL) models have shown remarkable performance in many applications, enabling replacing a fixed set of supported classes with zero-shot open vocabulary reasoning over (almost arbitrary) natural language prompts. However, recent works have uncovered a fundamental weakness of these models. For example, their difficulty to understand Visual Language Concepts (VLC) that go 'beyond nouns' such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or difficulty in performing compositional reasoning such as understanding the significance of the order of the words in a sentence. In this work, we investigate to which extent purely synthetic data could be leveraged to teach these models to overcome such shortcomings without compromising their zero-shot capabilities. We contribute Synthetic Visual Concepts (SyViC) - a million-scale synthetic dataset and data generation codebase allowing to generate additional suitable data to improve VLC understanding and compositional reasoning of VL models. Additionally, we propose a general VL finetuning strategy for effectively leveraging SyViC towards achieving these improvements. Our extensive experiments and ablations on VL-Checklist, Winoground, and ARO benchmarks demonstrate that it is possible to adapt strong pre-trained VL models with synthetic data significantly enhancing their VLC understanding (e.g. by 9.9% on ARO and 4.3% on VL-Checklist) with under 1% drop in their zero-shot accuracy.