 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Inference Improves Compositionality in Vision-Language Models
Oct 29, 2024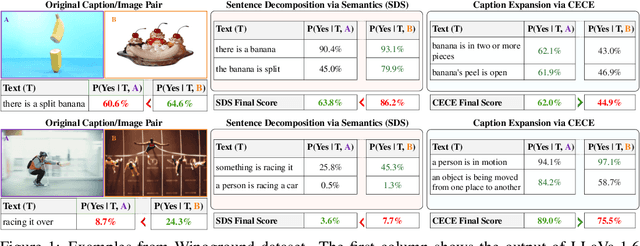
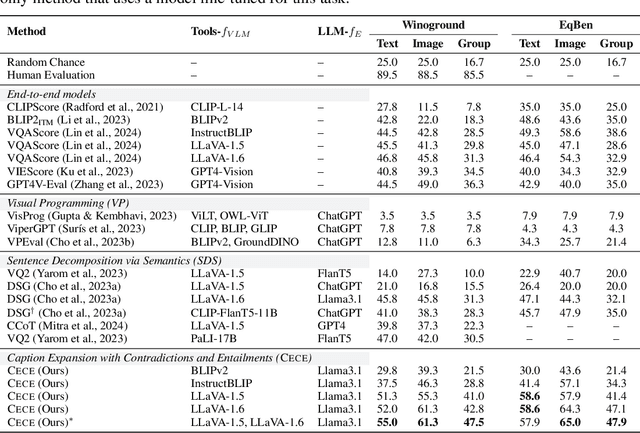
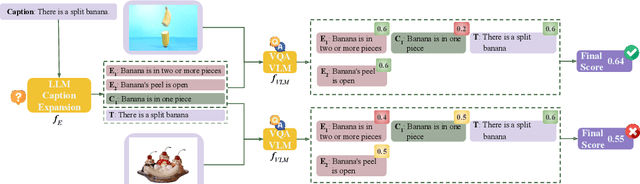

Compositional reasoning in Vision-Language Models (VLMs) remains challenging as these models often struggle to relate objects, attributes, and spatial relationships. Recent methods aim to address these limitations by relying on the semantics of the textual description, using Large Language Models (LLMs) to break them down into subsets of questions and answers. However, these methods primarily operate on the surface level, failing to incorporate deeper lexical understanding while introducing incorrect assumptions generated by the LLM. In response to these issues, we present Caption Expansion with Contradictions and Entailments (CECE), a principled approach that leverages Natural Language Inference (NLI) to generate entailments and contradictions from a given premise. CECE produces lexically diverse sentences while maintaining their core meaning. Through extensive experiments, we show that CECE enhances interpretability and reduces overreliance on biased or superficial features. By balancing CECE along the original premise, we achieve significant improvements over previous methods without requiring additional fine-tuning, producing state-of-the-art results on benchmarks that score agreement with human judgments for image-text alignment, and achieving an increase in performance on Winoground of +19.2% (group score) and +12.9% on EqBen (group score) over the best prior work (finetuned with targeted data).
Multilingual large language models leak human stereotypes across language boundaries
Dec 12, 2023



Multilingual large language models have been increasingly popular for their proficiency in comprehending and generating text across various languages. Previous research has shown that the presence of stereotypes and biases in monolingual large language models can be attributed to the nature of their training data, which is collected from humans and reflects societal biases. Multilingual language models undergo the same training procedure as monolingual ones, albeit with training data sourced from various languages. This raises the question: do stereotypes present in one social context leak across languages within the model? In our work, we first define the term ``stereotype leakage'' and propose a framework for its measurement. With this framework, we investigate how stereotypical associations leak across four languages: English, Russian, Chinese, and Hindi. To quantify the stereotype leakage, we employ an approach from social psychology, measuring stereotypes via group-trait associations. We evaluate human stereotypes and stereotypical associations manifested in multilingual large language models such as mBERT, mT5, and ChatGPT. Our findings show a noticeable leakage of positive, negative, and non-polar associations across all languages. Notably, Hindi within multilingual models appears to be the most susceptible to influence from other languages, while Chinese is the least. Additionally, ChatGPT exhibits a better alignment with human scores than other models.
Toxicity Detection is NOT all you Need: Measuring the Gaps to Supporting Volunteer Content Moderators
Nov 14, 2023



Extensive efforts in automated approaches for content moderation have been focused on developing models to identify toxic, offensive, and hateful content -- with the aim of lightening the load for moderators. Yet, it remains uncertain whether improvements on those tasks truly address the needs that moderators have in accomplishing their work. In this paper, we surface the gaps between past research efforts that have aimed to provide automation for aspects of the content moderation task, and the needs of volunteer content moderators. To do so, we conduct a model review on Hugging Face to reveal the availability of models to cover various moderation rules and guidelines. We further put state-of-the-art LLMs to the test (GPT-4 and Llama-2), evaluating how well these models perform in flagging violations of platform rules. Overall, we observe a non-trivial gap, as missing developed models and LLMs exhibit low recall on a significant portion of the rules.
What's Different between Visual Question Answering for Machine "Understanding" Versus for Accessibility?
Oct 26, 2022In visual question answering (VQA), a machine must answer a question given an associated image. Recently, accessibility researchers have explored whether VQA can be deployed in a real-world setting where users with visual impairments learn about their environment by capturing their visual surroundings and asking questions. However, most of the existing benchmarking datasets for VQA focus on machine "understanding" and it remains unclear how progress on those datasets corresponds to improvements in this real-world use case. We aim to answer this question by evaluating discrepancies between machine "understanding" datasets (VQA-v2) and accessibility datasets (VizWiz) by evaluating a variety of VQA models. Based on our findings, we discuss opportunities and challenges in VQA for accessibility and suggest directions for future work.
Theory-Grounded Measurement of U.S. Social Stereotypes in English Language Models
Jun 23, 2022


NLP models trained on text have been shown to reproduce human stereotypes, which can magnify harms to marginalized groups when systems are deployed at scale. We adapt the Agency-Belief-Communion (ABC) stereotype model of Koch et al. (2016) from social psychology as a framework for the systematic study and discovery of stereotypic group-trait associations in language models (LMs). We introduce the sensitivity test (SeT) for measuring stereotypical associations from language models. To evaluate SeT and other measures using the ABC model, we collect group-trait judgments from U.S.-based subjects to compare with English LM stereotypes. Finally, we extend this framework to measure LM stereotyping of intersectional identities.
On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
Mar 25, 2022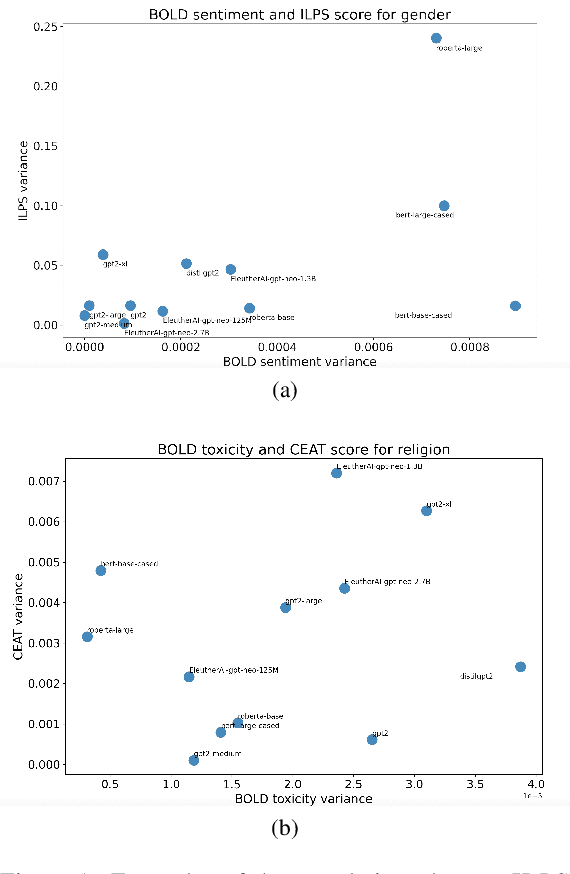
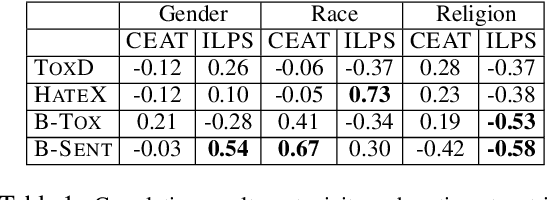
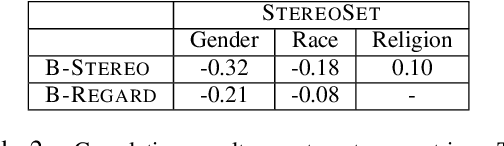
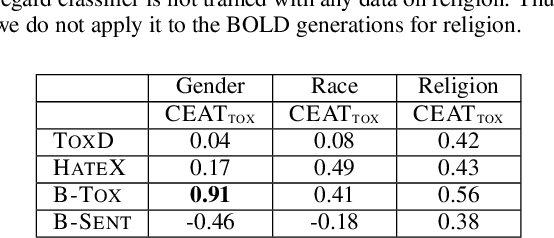
Multiple metrics have been introduced to measure fairness in various natural language processing tasks. These metrics can be roughly categorized into two categories: 1) \emph{extrinsic metrics} for evaluating fairness in downstream applications and 2) \emph{intrinsic metrics} for estimating fairness in upstream contextualized language representation models. In this paper, we conduct an extensive correlation study between intrinsic and extrinsic metrics across bias notions using 19 contextualized language models. We find that intrinsic and extrinsic metrics do not necessarily correlate in their original setting, even when correcting for metric misalignments, noise in evaluation datasets, and confounding factors such as experiment configuration for extrinsic metrics. %al
Toward Gender-Inclusive Coreference Resolution
Nov 01, 2019



Correctly resolving textual mentions of people fundamentally entails making inferences about those people. Such inferences raise the risk of systemic biases in coreference resolution systems, including biases that reinforce cis-normativity and can harm binary and non-binary trans (and cis) stakeholders. To better understand such biases, we foreground nuanced conceptualizations of gender from sociology and sociolinguistics, and investigate where in the machine learning pipeline such biases can enter a system. We inspect many existing datasets for trans-exclusionary biases, and develop two new datasets for interrogating bias in crowd annotations and in existing coreference resolution systems. Through these studies, conducted on English text, we confirm that without acknowledging and building systems that recognize the complexity of gender, we will build systems that fail for: quality of service, stereotyping, and over- or under-representation.