 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterviewSim: A Scalable Framework for Interview-Grounded Personality Simulation
Feb 23, 2026Simulating real personalities with large language models requires grounding generation in authentic personal data. Existing evaluation approaches rely on demographic surveys, personality questionnaires, or short AI-led interviews as proxies, but lack direct assessment against what individuals actually said. We address this gap with an interview-grounded evaluation framework for personality simulation at a large scale. We extract over 671,000 question-answer pairs from 23,000 verified interview transcripts across 1,000 public personalities, each with an average of 11.5 hours of interview content. We propose a multi-dimensional evaluation framework with four complementary metrics measuring content similarity, factual consistency, personality alignment, and factual knowledge retention. Through systematic comparison, we demonstrate that methods grounded in real interview data substantially outperform those relying solely on biographical profiles or the model's parametric knowledge. We further reveal a trade-off in how interview data is best utilized: retrieval-augmented methods excel at capturing personality style and response quality, while chronological-based methods better preserve factual consistency and knowledge retention. Our evaluation framework enables principled method selection based on application requirements, and our empirical findings provide actionable insights for advancing personality simulation research.
The Need for a Socially-Grounded Persona Framework for User Simulation
Jan 12, 2026Synthetic personas are widely used to condition large language models (LLMs) for social simulation, yet most personas are still constructed from coarse sociodemographic attributes or summaries. We revisit persona creation by introducing SCOPE, a socially grounded framework for persona construction and evaluation, built from a 141-item, two-hour sociopsychological protocol collected from 124 U.S.-based participants. Across seven models, we find that demographic-only personas are a structural bottleneck: demographics explain only ~1.5% of variance in human response similarity. Adding sociopsychological facets improves behavioral prediction and reduces over-accentuation, and non-demographic personas based on values and identity achieve strong alignment with substantially lower bias. These trends generalize to SimBench (441 aligned questions), where SCOPE personas outperform default prompting and NVIDIA Nemotron personas, and SCOPE augmentation improves Nemotron-based personas. Our results indicate that persona quality depends on sociopsychological structure rather than demographic templates or summaries.
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Jul 03, 2025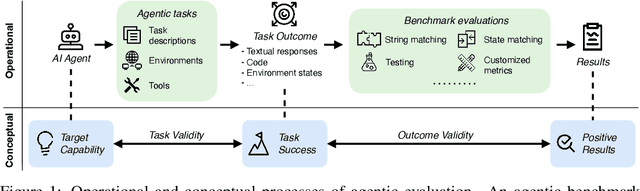
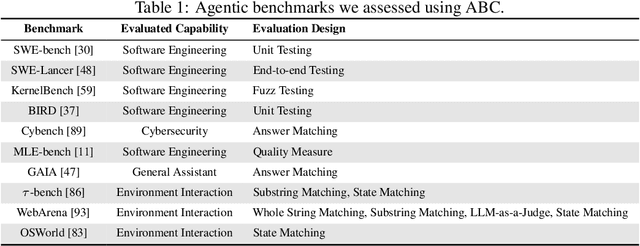
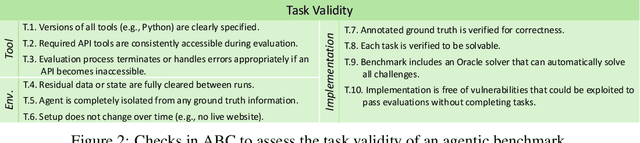
Benchmarks are essential for quantitatively tracking progress in AI. As AI agents become increasingly capable, researchers and practitioners have introduced agentic benchmarks to evaluate agents on complex, real-world tasks. These benchmarks typically measure agent capabilities by evaluating task outcomes via specific reward designs. However, we show that many agentic benchmarks have issues task setup or reward design. For example, SWE-bench Verified uses insufficient test cases, while TAU-bench counts empty responses as successful. Such issues can lead to under- or overestimation agents' performance by up to 100% in relative terms. To make agentic evaluation rigorous, we introduce the Agentic Benchmark Checklist (ABC), a set of guidelines that we synthesized from our benchmark-building experience, a survey of best practices, and previously reported issues. When applied to CVE-Bench, a benchmark with a particularly complex evaluation design, ABC reduces the performance overestimation by 33%.
Leveraging Explicit Procedural Instructions for Data-Efficient Action Prediction
Jun 06, 2023Task-oriented dialogues often require agents to enact complex, multi-step procedures in order to meet user requests. While large language models have found success automating these dialogues in constrained environments, their widespread deployment is limited by the substantial quantities of task-specific data required for training. The following paper presents a data-efficient solution to constructing dialogue systems, leveraging explicit instructions derived from agent guidelines, such as company policies or customer service manuals. Our proposed Knowledge-Augmented Dialogue System (KADS) combines a large language model with a knowledge retrieval module that pulls documents outlining relevant procedures from a predefined set of policies, given a user-agent interaction. To train this system, we introduce a semi-supervised pre-training scheme that employs dialogue-document matching and action-oriented masked language modeling with partial parameter freezing. We evaluate the effectiveness of our approach on prominent task-oriented dialogue datasets, Action-Based Conversations Dataset and Schema-Guided Dialogue, for two dialogue tasks: action state tracking and workflow discovery. Our results demonstrate that procedural knowledge augmentation improves accuracy predicting in- and out-of-distribution actions while preserving high performance in settings with low or sparse data.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
Mar 25, 2022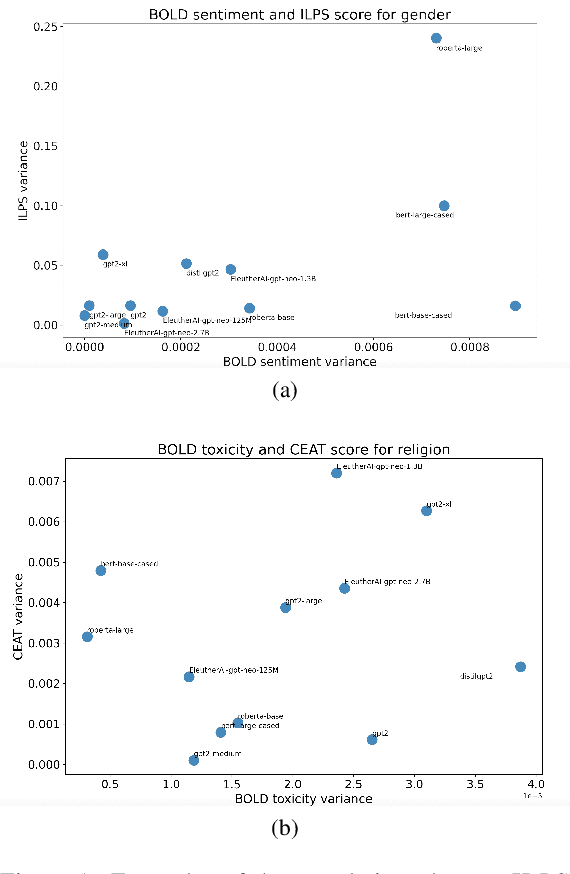
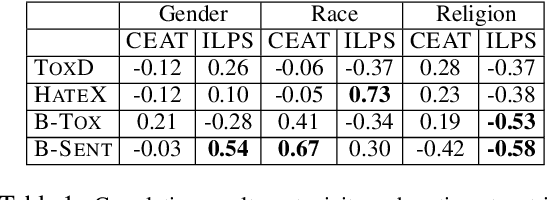
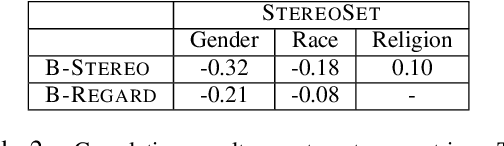
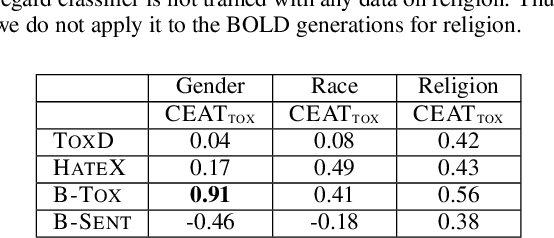
Multiple metrics have been introduced to measure fairness in various natural language processing tasks. These metrics can be roughly categorized into two categories: 1) \emph{extrinsic metrics} for evaluating fairness in downstream applications and 2) \emph{intrinsic metrics} for estimating fairness in upstream contextualized language representation models. In this paper, we conduct an extensive correlation study between intrinsic and extrinsic metrics across bias notions using 19 contextualized language models. We find that intrinsic and extrinsic metrics do not necessarily correlate in their original setting, even when correcting for metric misalignments, noise in evaluation datasets, and confounding factors such as experiment configuration for extrinsic metrics. %al
Mitigating Gender Bias in Distilled Language Models via Counterfactual Role Reversal
Mar 23, 2022

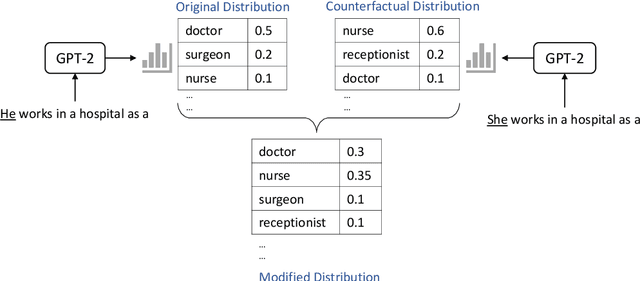
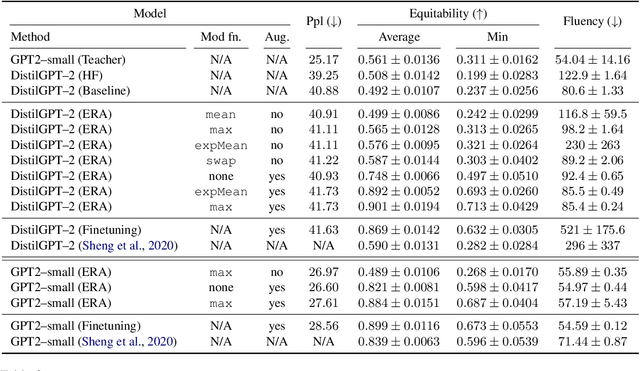
Language models excel at generating coherent text, and model compression techniques such as knowledge distillation have enabled their use in resource-constrained settings. However, these models can be biased in multiple ways, including the unfounded association of male and female genders with gender-neutral professions. Therefore, knowledge distillation without any fairness constraints may preserve or exaggerate the teacher model's biases onto the distilled model. To this end, we present a novel approach to mitigate gender disparity in text generation by learning a fair model during knowledge distillation. We propose two modifications to the base knowledge distillation based on counterfactual role reversal$\unicode{x2014}$modifying teacher probabilities and augmenting the training set. We evaluate gender polarity across professions in open-ended text generated from the resulting distilled and finetuned GPT$\unicode{x2012}$2 models and demonstrate a substantial reduction in gender disparity with only a minor compromise in utility. Finally, we observe that language models that reduce gender polarity in language generation do not improve embedding fairness or downstream classification fairness.
Measuring Fairness of Text Classifiers via Prediction Sensitivity
Mar 16, 2022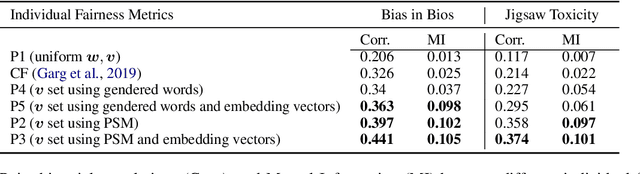
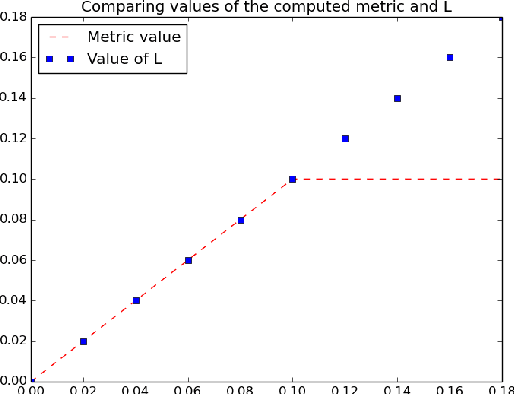

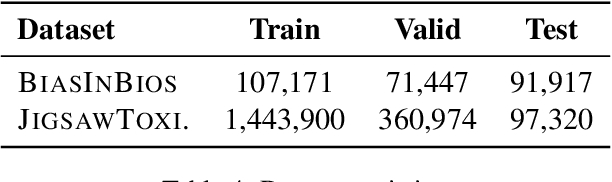
With the rapid growth in language processing applications, fairness has emerged as an important consideration in data-driven solutions. Although various fairness definitions have been explored in the recent literature, there is lack of consensus on which metrics most accurately reflect the fairness of a system. In this work, we propose a new formulation : ACCUMULATED PREDICTION SENSITIVITY, which measures fairness in machine learning models based on the model's prediction sensitivity to perturbations in input features. The metric attempts to quantify the extent to which a single prediction depends on a protected attribute, where the protected attribute encodes the membership status of an individual in a protected group. We show that the metric can be theoretically linked with a specific notion of group fairness (statistical parity) and individual fairness. It also correlates well with humans' perception of fairness. We conduct experiments on two text classification datasets : JIGSAW TOXICITY, and BIAS IN BIOS, and evaluate the correlations between metrics and manual annotations on whether the model produced a fair outcome. We observe that the proposed fairness metric based on prediction sensitivity is statistically significantly more correlated with human annotation than the existing counterfactual fairness metric.
Does Robustness Improve Fairness? Approaching Fairness with Word Substitution Robustness Methods for Text Classification
Jun 21, 2021



Existing bias mitigation methods to reduce disparities in model outcomes across cohorts have focused on data augmentation, debiasing model embeddings, or adding fairness-based optimization objectives during training. Separately, certified word substitution robustness methods have been developed to decrease the impact of spurious features and synonym substitutions on model predictions. While their end goals are different, they both aim to encourage models to make the same prediction for certain changes in the input. In this paper, we investigate the utility of certified word substitution robustness methods to improve equality of odds and equality of opportunity on multiple text classification tasks. We observe that certified robustness methods improve fairness, and using both robustness and bias mitigation methods in training results in an improvement in both fronts
CLIP: A Dataset for Extracting Action Items for Physicians from Hospital Discharge Notes
Jun 04, 2021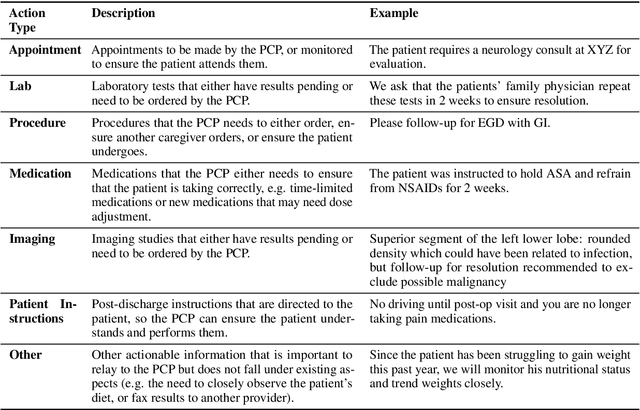
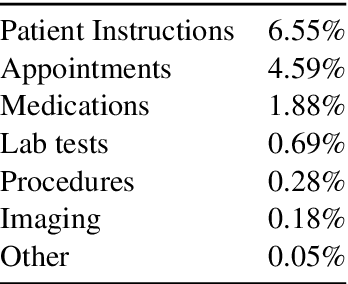
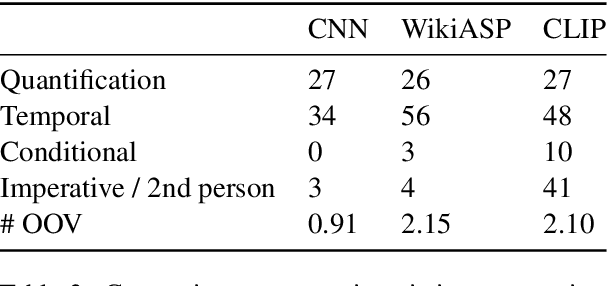
Continuity of care is crucial to ensuring positive health outcomes for patients discharged from an inpatient hospital setting, and improved information sharing can help. To share information, caregivers write discharge notes containing action items to share with patients and their future caregivers, but these action items are easily lost due to the lengthiness of the documents. In this work, we describe our creation of a dataset of clinical action items annotated over MIMIC-III, the largest publicly available dataset of real clinical notes. This dataset, which we call CLIP, is annotated by physicians and covers 718 documents representing 100K sentences. We describe the task of extracting the action items from these documents as multi-aspect extractive summarization, with each aspect representing a type of action to be taken. We evaluate several machine learning models on this task, and show that the best models exploit in-domain language model pre-training on 59K unannotated documents, and incorporate context from neighboring sentences. We also propose an approach to pre-training data selection that allows us to explore the trade-off between size and domain-specificity of pre-training datasets for this task.