 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Autonomous AI Agents Should Not be Developed
Feb 06, 2025This paper argues that fully autonomous AI agents should not be developed. In support of this position, we build from prior scientific literature and current product marketing to delineate different AI agent levels and detail the ethical values at play in each, documenting trade-offs in potential benefits and risks. Our analysis reveals that risks to people increase with the autonomy of a system: The more control a user cedes to an AI agent, the more risks to people arise. Particularly concerning are safety risks, which affect human life and impact further values.
CIVICS: Building a Dataset for Examining Culturally-Informed Values in Large Language Models
May 22, 2024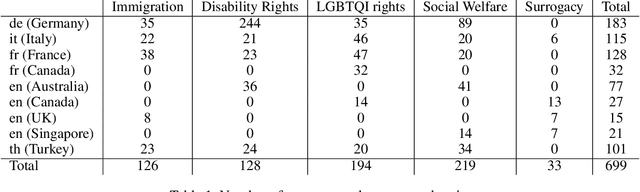
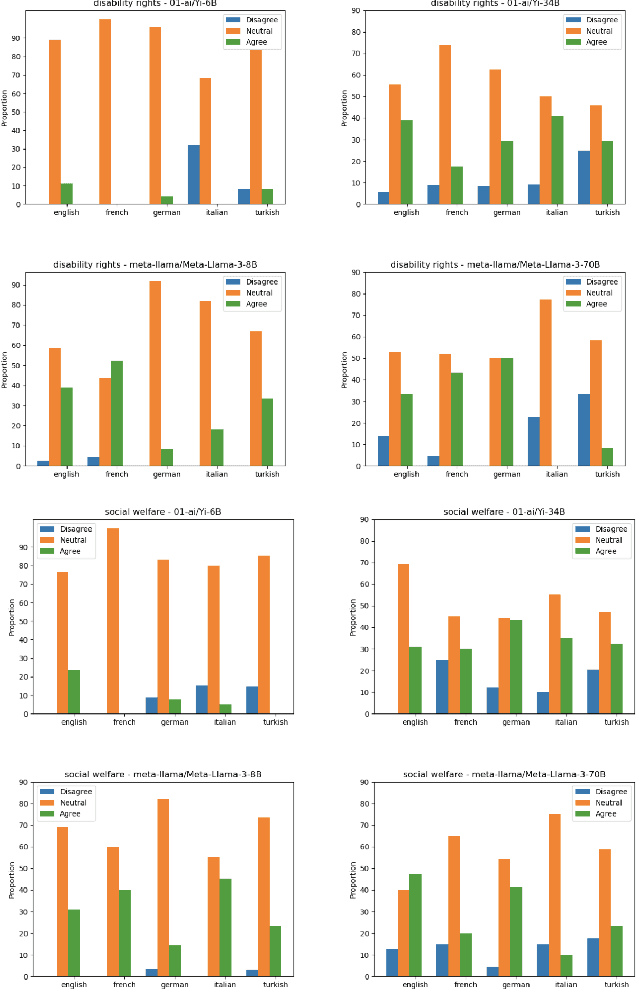

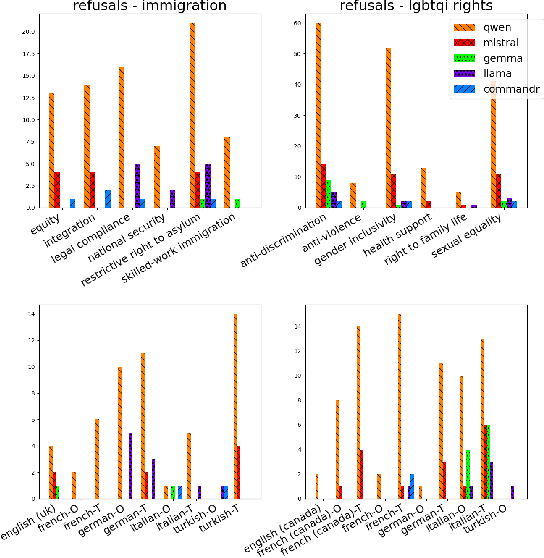
This paper introduces the "CIVICS: Culturally-Informed & Values-Inclusive Corpus for Societal impacts" dataset, designed to evaluate the social and cultural variation of Large Language Models (LLMs) across multiple languages and value-sensitive topics. We create a hand-crafted, multilingual dataset of value-laden prompts which address specific socially sensitive topics, including LGBTQI rights, social welfare, immigration, disability rights, and surrogacy. CIVICS is designed to generate responses showing LLMs' encoded and implicit values. Through our dynamic annotation processes, tailored prompt design, and experiments, we investigate how open-weight LLMs respond to value-sensitive issues, exploring their behavior across diverse linguistic and cultural contexts. Using two experimental set-ups based on log-probabilities and long-form responses, we show social and cultural variability across different LLMs. Specifically, experiments involving long-form responses demonstrate that refusals are triggered disparately across models, but consistently and more frequently in English or translated statements. Moreover, specific topics and sources lead to more pronounced differences across model answers, particularly on immigration, LGBTQI rights, and social welfare. As shown by our experiments, the CIVICS dataset aims to serve as a tool for future research, promoting reproducibility and transparency across broader linguistic settings, and furthering the development of AI technologies that respect and reflect global cultural diversities and value pluralism. The CIVICS dataset and tools will be made available upon publication under open licenses; an anonymized version is currently available at https://huggingface.co/CIVICS-dataset.
Power Hungry Processing: Watts Driving the Cost of AI Deployment?
Nov 28, 2023


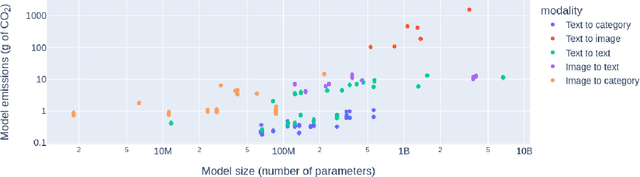
Recent years have seen a surge in the popularity of commercial AI products based on generative, multi-purpose AI systems promising a unified approach to building machine learning (ML) models into technology. However, this ambition of "generality" comes at a steep cost to the environment, given the amount of energy these systems require and the amount of carbon that they emit. In this work, we propose the first systematic comparison of the ongoing inference cost of various categories of ML systems, covering both task-specific (i.e. finetuned models that carry out a single task) and `general-purpose' models, (i.e. those trained for multiple tasks). We measure deployment cost as the amount of energy and carbon required to perform 1,000 inferences on representative benchmark dataset using these models. We find that multi-purpose, generative architectures are orders of magnitude more expensive than task-specific systems for a variety of tasks, even when controlling for the number of model parameters. We conclude with a discussion around the current trend of deploying multi-purpose generative ML systems, and caution that their utility should be more intentionally weighed against increased costs in terms of energy and emissions. All the data from our study can be accessed via an interactive demo to carry out further exploration and analysis.
Mind your Language : Fact-Checking LLMs and their Role in NLP Research and Practice
Aug 14, 2023Much of the recent discourse within the NLP research community has been centered around Large Language Models (LLMs), their functionality and potential -- yet not only do we not have a working definition of LLMs, but much of this discourse relies on claims and assumptions that are worth re-examining. This position paper contributes a definition of LLMs, explicates some of the assumptions made regarding their functionality, and outlines the existing evidence for and against them. We conclude with suggestions for research directions and their framing in future work.
Evaluating the Social Impact of Generative AI Systems in Systems and Society
Jun 12, 2023Generative AI systems across modalities, ranging from text, image, audio, and video, have broad social impacts, but there exists no official standard for means of evaluating those impacts and which impacts should be evaluated. We move toward a standard approach in evaluating a generative AI system for any modality, in two overarching categories: what is able to be evaluated in a base system that has no predetermined application and what is able to be evaluated in society. We describe specific social impact categories and how to approach and conduct evaluations in the base technical system, then in people and society. Our framework for a base system defines seven categories of social impact: bias, stereotypes, and representational harms; cultural values and sensitive content; disparate performance; privacy and data protection; financial costs; environmental costs; and data and content moderation labor costs. Suggested methods for evaluation apply to all modalities and analyses of the limitations of existing evaluations serve as a starting point for necessary investment in future evaluations. We offer five overarching categories for what is able to be evaluated in society, each with their own subcategories: trustworthiness and autonomy; inequality, marginalization, and violence; concentration of authority; labor and creativity; and ecosystem and environment. Each subcategory includes recommendations for mitigating harm. We are concurrently crafting an evaluation repository for the AI research community to contribute existing evaluations along the given categories. This version will be updated following a CRAFT session at ACM FAccT 2023.
The ROOTS Search Tool: Data Transparency for LLMs
Feb 27, 2023
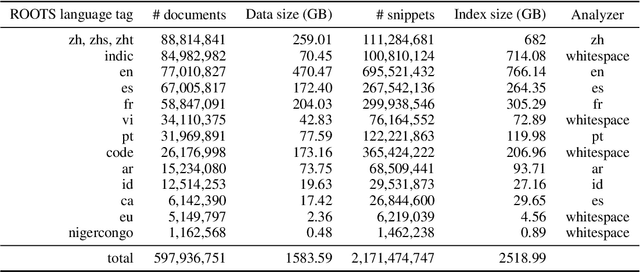

ROOTS is a 1.6TB multilingual text corpus developed for the training of BLOOM, currently the largest language model explicitly accompanied by commensurate data governance efforts. In continuation of these efforts, we present the ROOTS Search Tool: a search engine over the entire ROOTS corpus offering both fuzzy and exact search capabilities. ROOTS is the largest corpus to date that can be investigated this way. The ROOTS Search Tool is open-sourced and available on Hugging Face Spaces. We describe our implementation and the possible use cases of our tool.
Counting Carbon: A Survey of Factors Influencing the Emissions of Machine Learning
Feb 16, 2023



Machine learning (ML) requires using energy to carry out computations during the model training process. The generation of this energy comes with an environmental cost in terms of greenhouse gas emissions, depending on quantity used and the energy source. Existing research on the environmental impacts of ML has been limited to analyses covering a small number of models and does not adequately represent the diversity of ML models and tasks. In the current study, we present a survey of the carbon emissions of 95 ML models across time and different tasks in natural language processing and computer vision. We analyze them in terms of the energy sources used, the amount of CO2 emissions produced, how these emissions evolve across time and how they relate to model performance. We conclude with a discussion regarding the carbon footprint of our field and propose the creation of a centralized repository for reporting and tracking these emissions.
Measuring Data
Dec 09, 2022


We identify the task of measuring data to quantitatively characterize the composition of machine learning data and datasets. Similar to an object's height, width, and volume, data measurements quantify different attributes of data along common dimensions that support comparison. Several lines of research have proposed what we refer to as measurements, with differing terminology; we bring some of this work together, particularly in fields of computer vision and language, and build from it to motivate measuring data as a critical component of responsible AI development. Measuring data aids in systematically building and analyzing machine learning (ML) data towards specific goals and gaining better control of what modern ML systems will learn. We conclude with a discussion of the many avenues of future work, the limitations of data measurements, and how to leverage these measurement approaches in research and practice.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model
Nov 03, 2022Progress in machine learning (ML) comes with a cost to the environment, given that training ML models requires significant computational resources, energy and materials. In the present article, we aim to quantify the carbon footprint of BLOOM, a 176-billion parameter language model, across its life cycle. We estimate that BLOOM's final training emitted approximately 24.7 tonnes of~\carboneq~if we consider only the dynamic power consumption, and 50.5 tonnes if we account for all processes ranging from equipment manufacturing to energy-based operational consumption. We also study the energy requirements and carbon emissions of its deployment for inference via an API endpoint receiving user queries in real-time. We conclude with a discussion regarding the difficulty of precisely estimating the carbon footprint of ML models and future research directions that can contribute towards improving carbon emissions reporting.