 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Eval Ever: A Unifying Schema and Community Repository for AI Evaluation Results
Jun 12, 2026AI evaluations are widely used for testing and understanding progress. However, the diverse evaluators bring with them inconsistencies that challenge analysis and comparison. First, results are saved in incompatible formats, scattered across leaderboards, papers, blog posts, evaluation harness logs, and custom repositories. Second, results are created by different evaluation frameworks, which produce divergent scores for nominally identical evaluations and record metadata inconsistently, hindering comparison, cross-community evaluation science, cost reduction, and reuse. We introduce Every Eval Ever, the first shared schema and community-crowdsourced repository for AI evaluation results. The schema standardizes how evaluations are represented in a unified, single JSON document. It is source-agnostic by design, ingesting results from evaluation harnesses and papers alike, and optionally stores per-instance outputs for fine-grained analysis. We contribute: (i) a community-governed metadata schema with a companion instance-level schema, the first standardization effort of its kind; (ii) automatic converters from popular formats, evaluation harnesses, and leaderboards to the unified schema; and (iii) a crowdsourced community database hosted on Hugging Face, currently spanning to date 22,235 models, 2,273 unique benchmarks, and 31 evaluation formats.
Evaluation Cards: An Interpretive Layer for AI Evaluation Reporting
Jun 09, 2026AI evaluation results are produced at scale but reported inconsistently across leaderboards, model cards, benchmark papers, and company blogs. The cost is interpretive: readers cannot reliably compare results across sources, identify what a report omits, or trace an aggregate claim to its underlying evidence. Recent efforts address isolated components but leave three gaps: they cover only narrow slices of the evaluation lifecycle and do not compose into a single interpretable record; they specify static representations that do not differentiate the questions different stakeholders bring to the same evidence; and they remain proposals on paper, lacking the extraction infrastructure required for adoption at scale. We present \EvalCards{}, an operational reporting layer that composes benchmark metadata, evaluation run data, and model metadata into a unified record. We (1) derive a reporting schema from a structured review of 52 papers and 10 stakeholder interviews, (2) implement four interpretive signals (reproducibility, documentation completeness, provenance and risk, and score comparability), rendered through reader modes calibrated to research and non-research audiences, and (3) deploy a monitoring tool that applies \EvalCards{} across 5,816 models, 635 benchmarks, and 101,843 results, surfacing systematic gaps in current reporting practice.
When AI Benchmarks Plateau: A Systematic Study of Benchmark Saturation
Feb 18, 2026Artificial Intelligence (AI) benchmarks play a central role in measuring progress in model development and guiding deployment decisions. However, many benchmarks quickly become saturated, meaning that they can no longer differentiate between the best-performing models, diminishing their long-term value. In this study, we analyze benchmark saturation across 60 Large Language Model (LLM) benchmarks selected from technical reports by major model developers. To identify factors driving saturation, we characterize benchmarks along 14 properties spanning task design, data construction, and evaluation format. We test five hypotheses examining how each property contributes to saturation rates. Our analysis reveals that nearly half of the benchmarks exhibit saturation, with rates increasing as benchmarks age. Notably, hiding test data (i.e., public vs. private) shows no protective effect, while expert-curated benchmarks resist saturation better than crowdsourced ones. Our findings highlight which design choices extend benchmark longevity and inform strategies for more durable evaluation.
Who Evaluates AI's Social Impacts? Mapping Coverage and Gaps in First and Third Party Evaluations
Nov 06, 2025



Foundation models are increasingly central to high-stakes AI systems, and governance frameworks now depend on evaluations to assess their risks and capabilities. Although general capability evaluations are widespread, social impact assessments covering bias, fairness, privacy, environmental costs, and labor practices remain uneven across the AI ecosystem. To characterize this landscape, we conduct the first comprehensive analysis of both first-party and third-party social impact evaluation reporting across a wide range of model developers. Our study examines 186 first-party release reports and 183 post-release evaluation sources, and complements this quantitative analysis with interviews of model developers. We find a clear division of evaluation labor: first-party reporting is sparse, often superficial, and has declined over time in key areas such as environmental impact and bias, while third-party evaluators including academic researchers, nonprofits, and independent organizations provide broader and more rigorous coverage of bias, harmful content, and performance disparities. However, this complementarity has limits. Only model developers can authoritatively report on data provenance, content moderation labor, financial costs, and training infrastructure, yet interviews reveal that these disclosures are often deprioritized unless tied to product adoption or regulatory compliance. Our findings indicate that current evaluation practices leave major gaps in assessing AI's societal impacts, highlighting the urgent need for policies that promote developer transparency, strengthen independent evaluation ecosystems, and create shared infrastructure to aggregate and compare third-party evaluations in a consistent and accessible way.
A Scaling Law for Token Efficiency in LLM Fine-Tuning Under Fixed Compute Budgets
May 09, 2025



We introduce a scaling law for fine-tuning large language models (LLMs) under fixed compute budgets that explicitly accounts for data composition. Conventional approaches measure training data solely by total tokens, yet the number of examples and their average token length -- what we term \emph{dataset volume} -- play a decisive role in model performance. Our formulation is tuned following established procedures. Experiments on the BRICC dataset \cite{salavati2024reducing} and subsets of the MMLU dataset \cite{hendrycks2021measuringmassivemultitasklanguage}, evaluated under multiple subsampling strategies, reveal that data composition significantly affects token efficiency. These results motivate refined scaling laws for practical LLM fine-tuning in resource-constrained settings.
"It's not a representation of me": Examining Accent Bias and Digital Exclusion in Synthetic AI Voice Services
Apr 12, 2025



Recent advances in artificial intelligence (AI) speech generation and voice cloning technologies have produced naturalistic speech and accurate voice replication, yet their influence on sociotechnical systems across diverse accents and linguistic traits is not fully understood. This study evaluates two synthetic AI voice services (Speechify and ElevenLabs) through a mixed methods approach using surveys and interviews to assess technical performance and uncover how users' lived experiences influence their perceptions of accent variations in these speech technologies. Our findings reveal technical performance disparities across five regional, English-language accents and demonstrate how current speech generation technologies may inadvertently reinforce linguistic privilege and accent-based discrimination, potentially creating new forms of digital exclusion. Overall, our study highlights the need for inclusive design and regulation by providing actionable insights for developers, policymakers, and organizations to ensure equitable and socially responsible AI speech technologies.
Fully Autonomous AI Agents Should Not be Developed
Feb 06, 2025This paper argues that fully autonomous AI agents should not be developed. In support of this position, we build from prior scientific literature and current product marketing to delineate different AI agent levels and detail the ethical values at play in each, documenting trade-offs in potential benefits and risks. Our analysis reveals that risks to people increase with the autonomy of a system: The more control a user cedes to an AI agent, the more risks to people arise. Particularly concerning are safety risks, which affect human life and impact further values.
To Err is AI : A Case Study Informing LLM Flaw Reporting Practices
Oct 15, 2024



In August of 2024, 495 hackers generated evaluations in an open-ended bug bounty targeting the Open Language Model (OLMo) from The Allen Institute for AI. A vendor panel staffed by representatives of OLMo's safety program adjudicated changes to OLMo's documentation and awarded cash bounties to participants who successfully demonstrated a need for public disclosure clarifying the intent, capacities, and hazards of model deployment. This paper presents a collection of lessons learned, illustrative of flaw reporting best practices intended to reduce the likelihood of incidents and produce safer large language models (LLMs). These include best practices for safety reporting processes, their artifacts, and safety program staffing.
Quantifying Misalignment Between Agents
Jun 06, 2024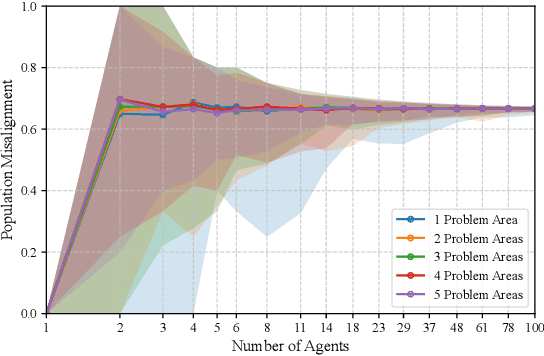
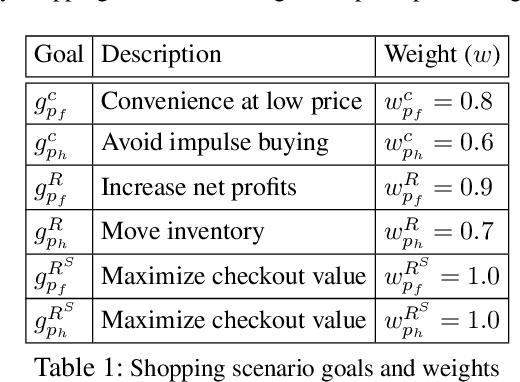
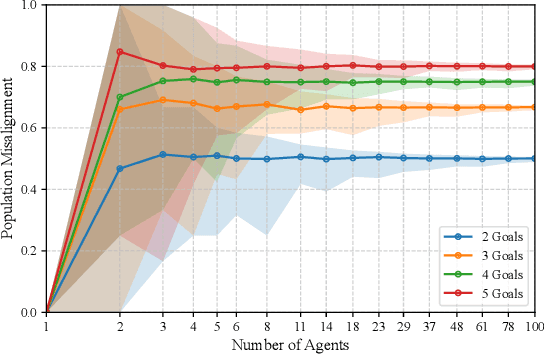
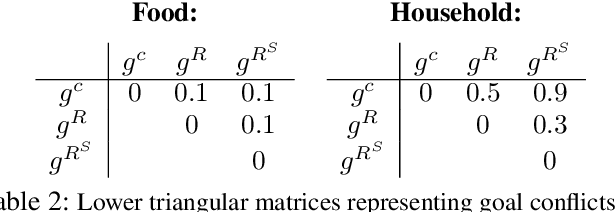
Growing concerns about the AI alignment problem have emerged in recent years, with previous work focusing mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a singular unit. Recent work in sociotechnical AI alignment has made some progress in defining alignment inclusively, but the field as a whole still lacks a systematic understanding of how to specify, describe, and analyze misalignment among entities, which may include individual humans, AI agents, and complex compositional entities such as corporations, nation-states, and so forth. Previous work on controversy in computational social science offers a mathematical model of contention among populations (of humans). In this paper, we adapt this contention model to the alignment problem, and show how misalignment can vary depending on the population of agents (human or otherwise) being observed, the domain in question, and the agents' probability-weighted preferences between possible outcomes. Our model departs from value specification approaches and focuses instead on the morass of complex, interlocking, sometimes contradictory goals that agents may have in practice. We apply our model by analyzing several case studies ranging from social media moderation to autonomous vehicle behavior. By applying our model with appropriately representative value data, AI engineers can ensure that their systems learn values maximally aligned with diverse human interests.
Coordinated Disclosure for AI: Beyond Security Vulnerabilities
Feb 10, 2024


Harm reporting in the field of Artificial Intelligence (AI) currently operates on an ad hoc basis, lacking a structured process for disclosing or addressing algorithmic flaws. In contrast, the Coordinated Vulnerability Disclosure (CVD) ethos and ecosystem play a pivotal role in software security and transparency. Within the U.S. context, there has been a protracted legal and policy struggle to establish a safe harbor from the Computer Fraud and Abuse Act, aiming to foster institutional support for security researchers acting in good faith. Notably, algorithmic flaws in Machine Learning (ML) models present distinct challenges compared to traditional software vulnerabilities, warranting a specialized approach. To address this gap, we propose the implementation of a dedicated Coordinated Flaw Disclosure (CFD) framework tailored to the intricacies of machine learning and artificial intelligence issues. This paper delves into the historical landscape of disclosures in ML, encompassing the ad hoc reporting of harms and the emergence of participatory auditing. By juxtaposing these practices with the well-established disclosure norms in cybersecurity, we argue that the broader adoption of CFD has the potential to enhance public trust through transparent processes that carefully balance the interests of both organizations and the community.