 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing Google's AI Overviews and Featured Snippets: A Case Study on Baby Care and Pregnancy
Nov 17, 2025Google Search increasingly surfaces AI-generated content through features like AI Overviews (AIO) and Featured Snippets (FS), which users frequently rely on despite having no control over their presentation. Through a systematic algorithm audit of 1,508 real baby care and pregnancy-related queries, we evaluate the quality and consistency of these information displays. Our robust evaluation framework assesses multiple quality dimensions, including answer consistency, relevance, presence of medical safeguards, source categories, and sentiment alignment. Our results reveal concerning gaps in information consistency, with information in AIO and FS displayed on the same search result page being inconsistent with each other in 33% of cases. Despite high relevance scores, both features critically lack medical safeguards (present in just 11% of AIO and 7% of FS responses). While health and wellness websites dominate source categories for both, AIO and FS, FS also often link to commercial sources. These findings have important implications for public health information access and demonstrate the need for stronger quality controls in AI-mediated health information. Our methodology provides a transferable framework for auditing AI systems across high-stakes domains where information quality directly impacts user well-being.
"It's not a representation of me": Examining Accent Bias and Digital Exclusion in Synthetic AI Voice Services
Apr 12, 2025



Recent advances in artificial intelligence (AI) speech generation and voice cloning technologies have produced naturalistic speech and accurate voice replication, yet their influence on sociotechnical systems across diverse accents and linguistic traits is not fully understood. This study evaluates two synthetic AI voice services (Speechify and ElevenLabs) through a mixed methods approach using surveys and interviews to assess technical performance and uncover how users' lived experiences influence their perceptions of accent variations in these speech technologies. Our findings reveal technical performance disparities across five regional, English-language accents and demonstrate how current speech generation technologies may inadvertently reinforce linguistic privilege and accent-based discrimination, potentially creating new forms of digital exclusion. Overall, our study highlights the need for inclusive design and regulation by providing actionable insights for developers, policymakers, and organizations to ensure equitable and socially responsible AI speech technologies.
When Fair Classification Meets Noisy Protected Attributes
Jul 11, 2023



The operationalization of algorithmic fairness comes with several practical challenges, not the least of which is the availability or reliability of protected attributes in datasets. In real-world contexts, practical and legal impediments may prevent the collection and use of demographic data, making it difficult to ensure algorithmic fairness. While initial fairness algorithms did not consider these limitations, recent proposals aim to achieve algorithmic fairness in classification by incorporating noisiness in protected attributes or not using protected attributes at all. To the best of our knowledge, this is the first head-to-head study of fair classification algorithms to compare attribute-reliant, noise-tolerant and attribute-blind algorithms along the dual axes of predictivity and fairness. We evaluated these algorithms via case studies on four real-world datasets and synthetic perturbations. Our study reveals that attribute-blind and noise-tolerant fair classifiers can potentially achieve similar level of performance as attribute-reliant algorithms, even when protected attributes are noisy. However, implementing them in practice requires careful nuance. Our study provides insights into the practical implications of using fair classification algorithms in scenarios where protected attributes are noisy or partially available.
Subverting Fair Image Search with Generative Adversarial Perturbations
May 06, 2022

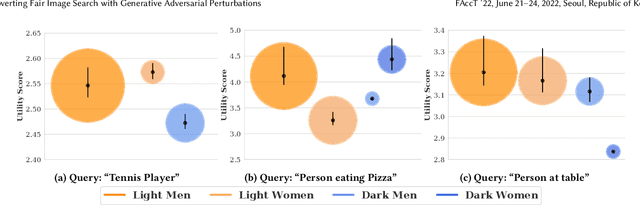
In this work we explore the intersection fairness and robustness in the context of ranking: when a ranking model has been calibrated to achieve some definition of fairness, is it possible for an external adversary to make the ranking model behave unfairly without having access to the model or training data? To investigate this question, we present a case study in which we develop and then attack a state-of-the-art, fairness-aware image search engine using images that have been maliciously modified using a Generative Adversarial Perturbation (GAP) model. These perturbations attempt to cause the fair re-ranking algorithm to unfairly boost the rank of images containing people from an adversary-selected subpopulation. We present results from extensive experiments demonstrating that our attacks can successfully confer significant unfair advantage to people from the majority class relative to fairly-ranked baseline search results. We demonstrate that our attacks are robust across a number of variables, that they have close to zero impact on the relevance of search results, and that they succeed under a strict threat model. Our findings highlight the danger of deploying fair machine learning algorithms in-the-wild when (1) the data necessary to achieve fairness may be adversarially manipulated, and (2) the models themselves are not robust against attacks.
Subscriptions and external links help drive resentful users to alternative and extremist YouTube videos
Apr 22, 2022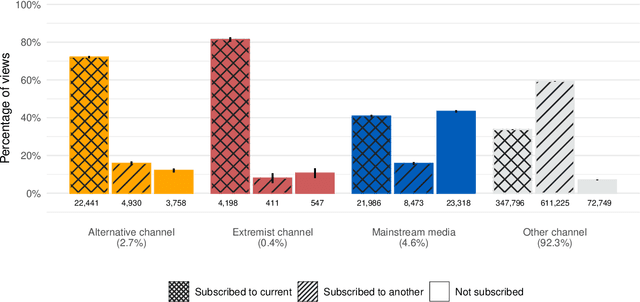
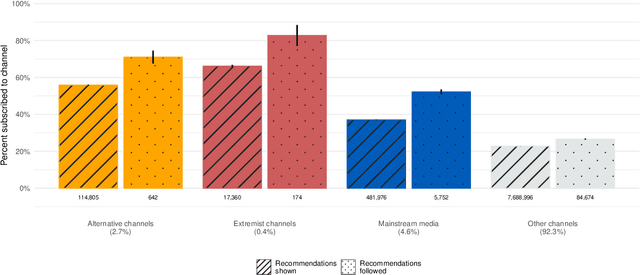
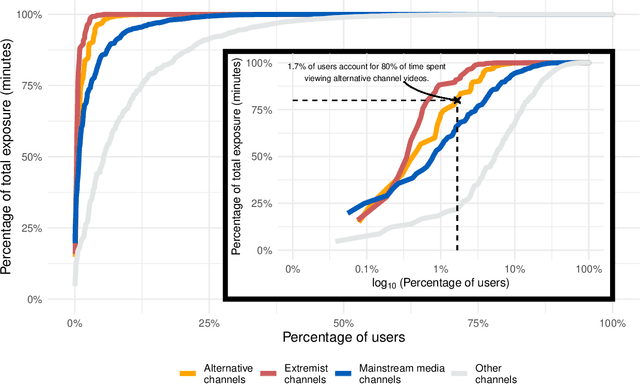
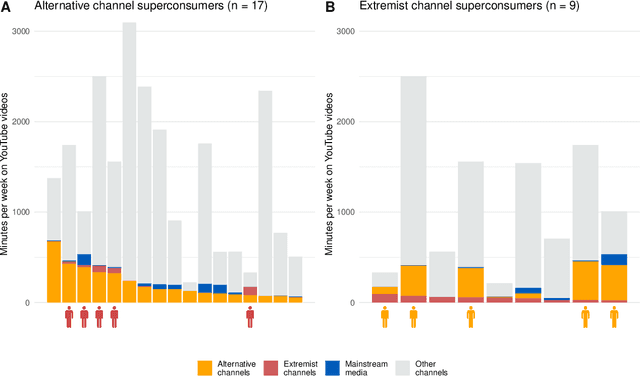
Do online platforms facilitate the consumption of potentially harmful content? Despite widespread concerns that YouTube's algorithms send people down "rabbit holes" with recommendations to extremist videos, little systematic evidence exists to support this conjecture. Using paired behavioral and survey data provided by participants recruited from a representative sample (n=1,181), we show that exposure to alternative and extremist channel videos on YouTube is heavily concentrated among a small group of people with high prior levels of gender and racial resentment. These viewers typically subscribe to these channels (causing YouTube to recommend their videos more often) and often follow external links to them. Contrary to the "rabbit holes" narrative, non-subscribers are rarely recommended videos from alternative and extremist channels and seldom follow such recommendations when offered.
When Fair Ranking Meets Uncertain Inference
May 05, 2021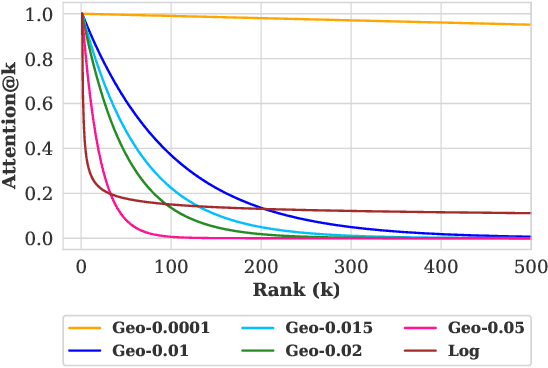
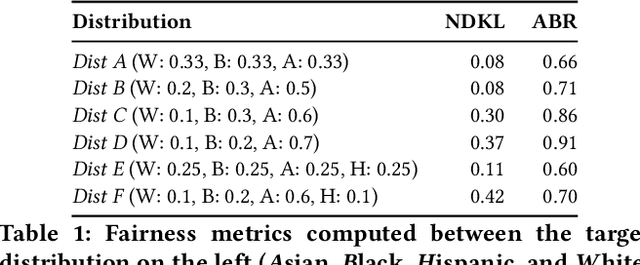
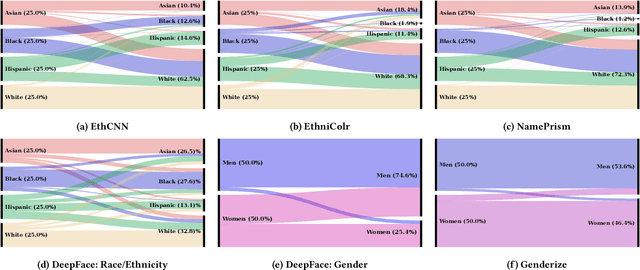
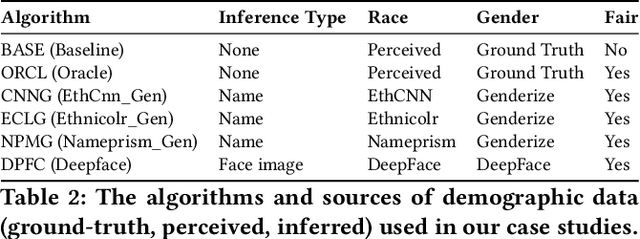
Existing fair ranking systems, especially those designed to be demographically fair, assume that accurate demographic information about individuals is available to the ranking algorithm. In practice, however, this assumption may not hold -- in real-world contexts like ranking job applicants or credit seekers, social and legal barriers may prevent algorithm operators from collecting peoples' demographic information. In these cases, algorithm operators may attempt to infer peoples' demographics and then supply these inferences as inputs to the ranking algorithm. In this study, we investigate how uncertainty and errors in demographic inference impact the fairness offered by fair ranking algorithms. Using simulations and three case studies with real datasets, we show how demographic inferences drawn from real systems can lead to unfair rankings. Our results suggest that developers should not use inferred demographic data as input to fair ranking algorithms, unless the inferences are extremely accurate.