 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChemical Reaction Extraction from Long Patent Documents
Jul 23, 2024



The task of searching through patent documents is crucial for chemical patent recommendation and retrieval. This can be enhanced by creating a patent knowledge base (ChemPatKB) to aid in prior art searches and to provide a platform for domain experts to explore new innovations in chemical compound synthesis and use-cases. An essential foundational component of this KB is the extraction of important reaction snippets from long patents documents which facilitates multiple downstream tasks such as reaction co-reference resolution and chemical entity role identification. In this work, we explore the problem of extracting reactions spans from chemical patents in order to create a reactions resource database. We formulate this task as a paragraph-level sequence tagging problem, where the system is required to return a sequence of paragraphs that contain a description of a reaction. We propose several approaches and modifications of the baseline models and study how different methods generalize across different domains of chemical patents.
Leveraging Machine-Generated Rationales to Facilitate Social Meaning Detection in Conversations
Jun 27, 2024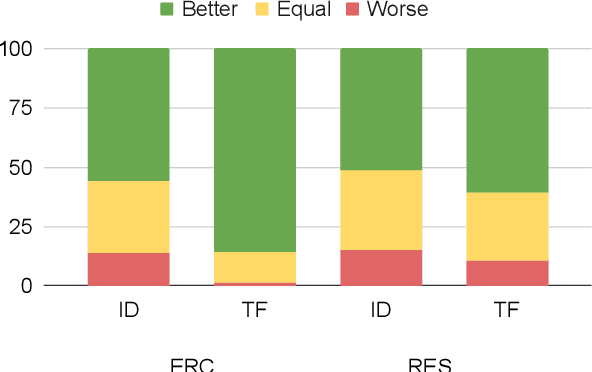
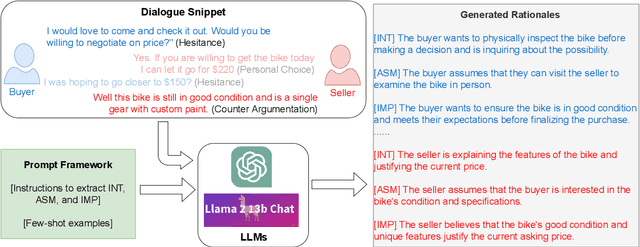

We present a generalizable classification approach that leverages Large Language Models (LLMs) to facilitate the detection of implicitly encoded social meaning in conversations. We design a multi-faceted prompt to extract a textual explanation of the reasoning that connects visible cues to underlying social meanings. These extracted explanations or rationales serve as augmentations to the conversational text to facilitate dialogue understanding and transfer. Our empirical results over 2,340 experimental settings demonstrate the significant positive impact of adding these rationales. Our findings hold true for in-domain classification, zero-shot, and few-shot domain transfer for two different social meaning detection tasks, each spanning two different corpora.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023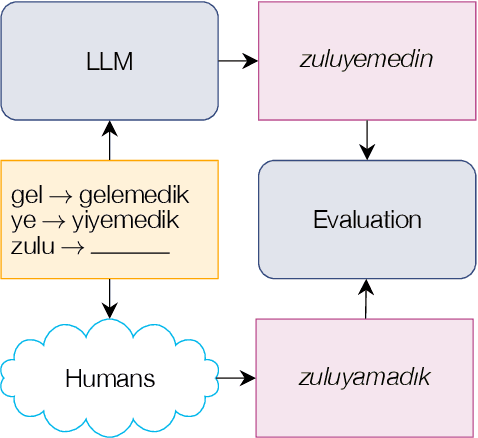
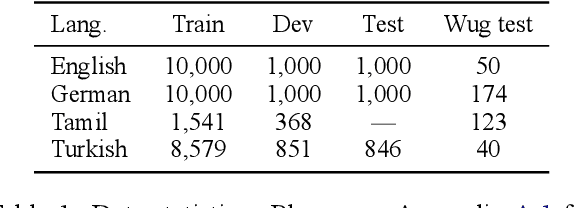
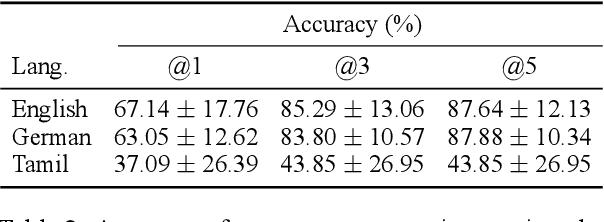
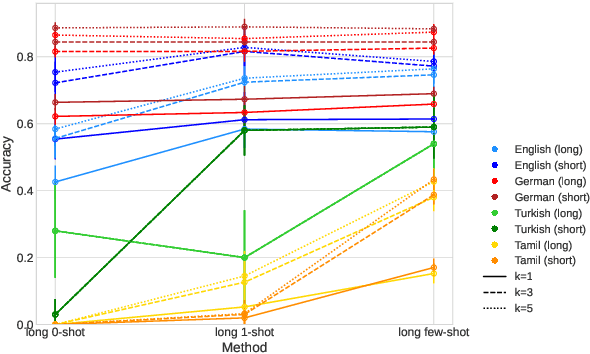
Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
Linguistic representations for fewer-shot relation extraction across domains
Jul 07, 2023

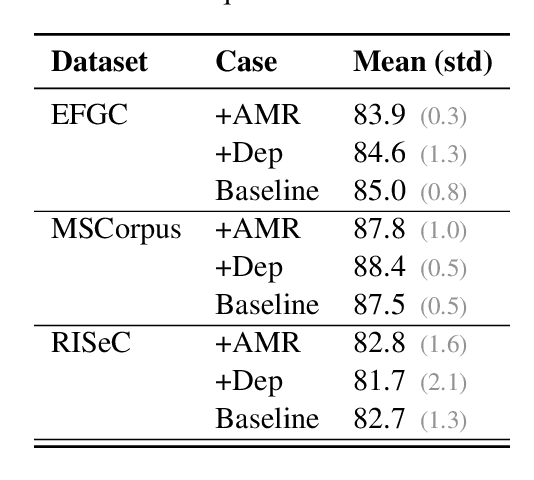
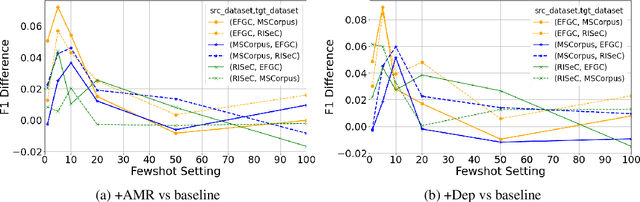
Recent work has demonstrated the positive impact of incorporating linguistic representations as additional context and scaffolding on the in-domain performance of several NLP tasks. We extend this work by exploring the impact of linguistic representations on cross-domain performance in a few-shot transfer setting. An important question is whether linguistic representations enhance generalizability by providing features that function as cross-domain pivots. We focus on the task of relation extraction on three datasets of procedural text in two domains, cooking and materials science. Our approach augments a popular transformer-based architecture by alternately incorporating syntactic and semantic graphs constructed by freely available off-the-shelf tools. We examine their utility for enhancing generalization, and investigate whether earlier findings, e.g. that semantic representations can be more helpful than syntactic ones, extend to relation extraction in multiple domains. We find that while the inclusion of these graphs results in significantly higher performance in few-shot transfer, both types of graph exhibit roughly equivalent utility.
You too Brutus! Trapping Hateful Users in Social Media: Challenges, Solutions & Insights
Aug 01, 2021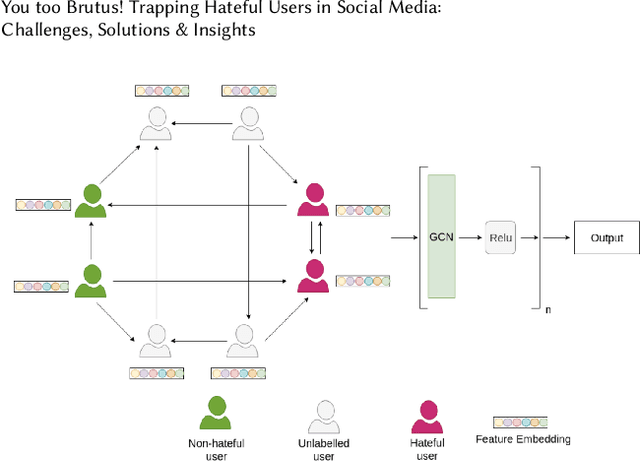
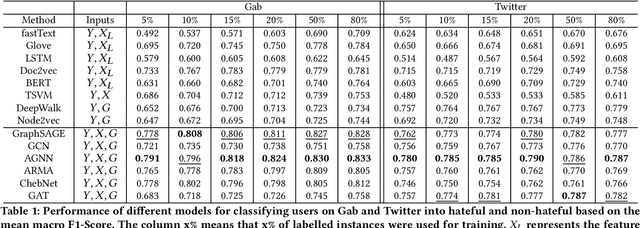
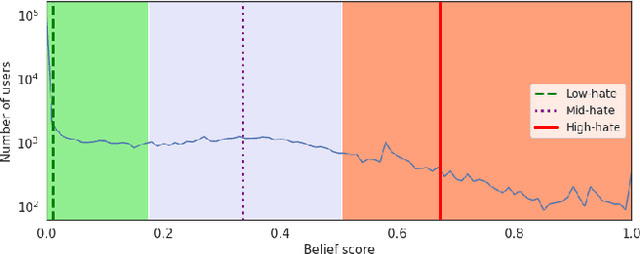
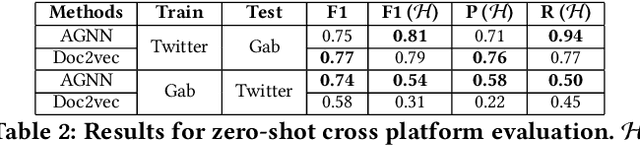
Hate speech is regarded as one of the crucial issues plaguing the online social media. The current literature on hate speech detection leverages primarily the textual content to find hateful posts and subsequently identify hateful users. However, this methodology disregards the social connections between users. In this paper, we run a detailed exploration of the problem space and investigate an array of models ranging from purely textual to graph based to finally semi-supervised techniques using Graph Neural Networks (GNN) that utilize both textual and graph-based features. We run exhaustive experiments on two datasets -- Gab, which is loosely moderated and Twitter, which is strictly moderated. Overall the AGNN model achieves 0.791 macro F1-score on the Gab dataset and 0.780 macro F1-score on the Twitter dataset using only 5% of the labeled instances, considerably outperforming all the other models including the fully supervised ones. We perform detailed error analysis on the best performing text and graph based models and observe that hateful users have unique network neighborhood signatures and the AGNN model benefits by paying attention to these signatures. This property, as we observe, also allows the model to generalize well across platforms in a zero-shot setting. Lastly, we utilize the best performing GNN model to analyze the evolution of hateful users and their targets over time in Gab.
When Fair Ranking Meets Uncertain Inference
May 05, 2021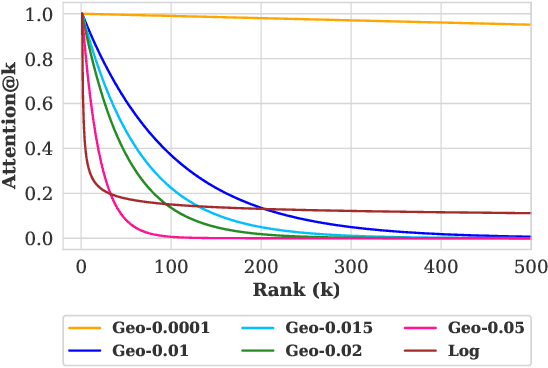
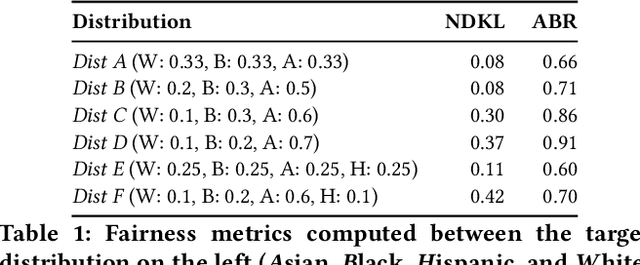
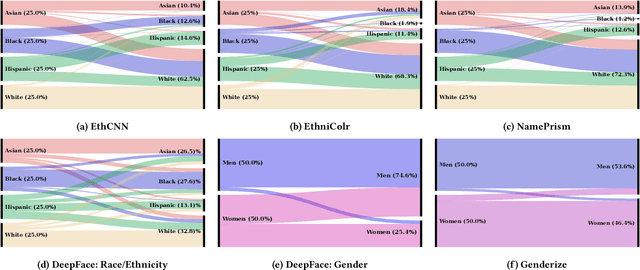
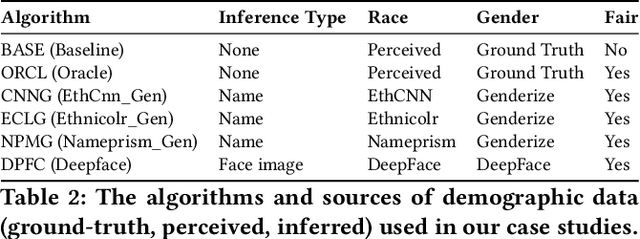
Existing fair ranking systems, especially those designed to be demographically fair, assume that accurate demographic information about individuals is available to the ranking algorithm. In practice, however, this assumption may not hold -- in real-world contexts like ranking job applicants or credit seekers, social and legal barriers may prevent algorithm operators from collecting peoples' demographic information. In these cases, algorithm operators may attempt to infer peoples' demographics and then supply these inferences as inputs to the ranking algorithm. In this study, we investigate how uncertainty and errors in demographic inference impact the fairness offered by fair ranking algorithms. Using simulations and three case studies with real datasets, we show how demographic inferences drawn from real systems can lead to unfair rankings. Our results suggest that developers should not use inferred demographic data as input to fair ranking algorithms, unless the inferences are extremely accurate.
RESPER: Computationally Modelling Resisting Strategies in Persuasive Conversations
Jan 26, 2021
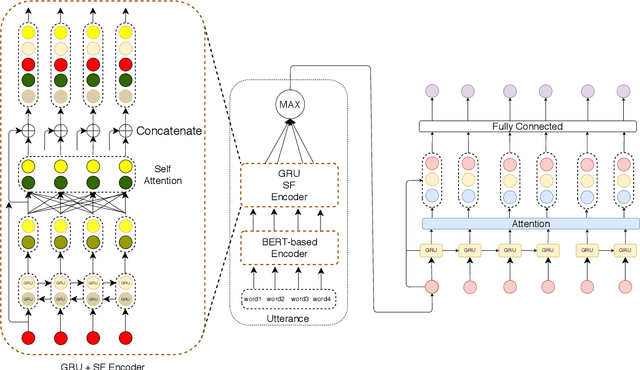

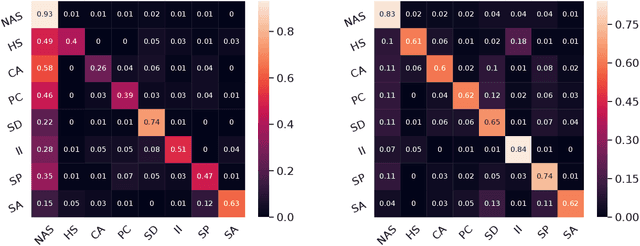
Modelling persuasion strategies as predictors of task outcome has several real-world applications and has received considerable attention from the computational linguistics community. However, previous research has failed to account for the resisting strategies employed by an individual to foil such persuasion attempts. Grounded in prior literature in cognitive and social psychology, we propose a generalised framework for identifying resisting strategies in persuasive conversations. We instantiate our framework on two distinct datasets comprising persuasion and negotiation conversations. We also leverage a hierarchical sequence-labelling neural architecture to infer the aforementioned resisting strategies automatically. Our experiments reveal the asymmetry of power roles in non-collaborative goal-directed conversations and the benefits accrued from incorporating resisting strategies on the final conversation outcome. We also investigate the role of different resisting strategies on the conversation outcome and glean insights that corroborate with past findings. We also make the code and the dataset of this work publicly available at https://github.com/americast/resper.
Keeping Up Appearances: Computational Modeling of Face Acts in Persuasion Oriented Discussions
Sep 24, 2020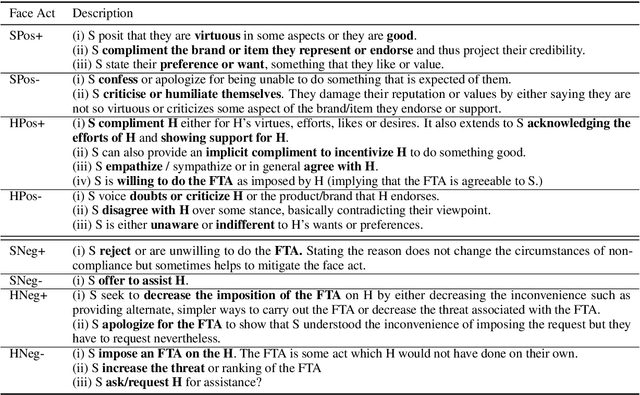
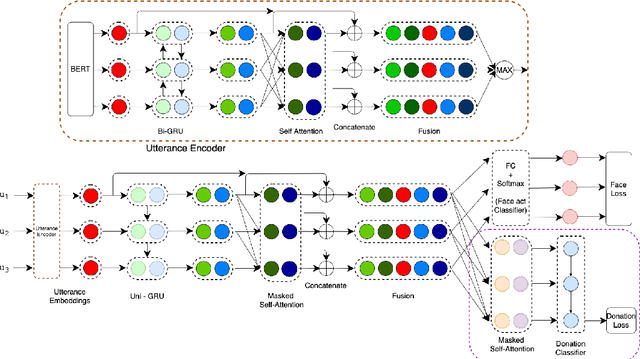
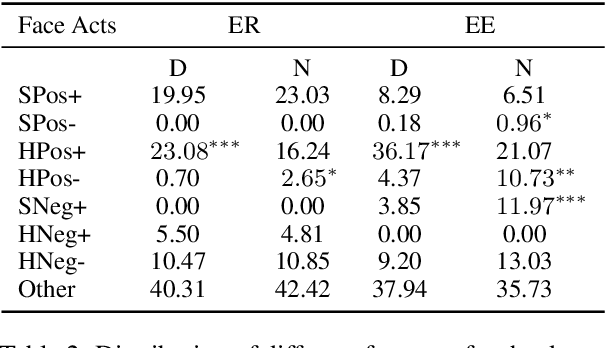
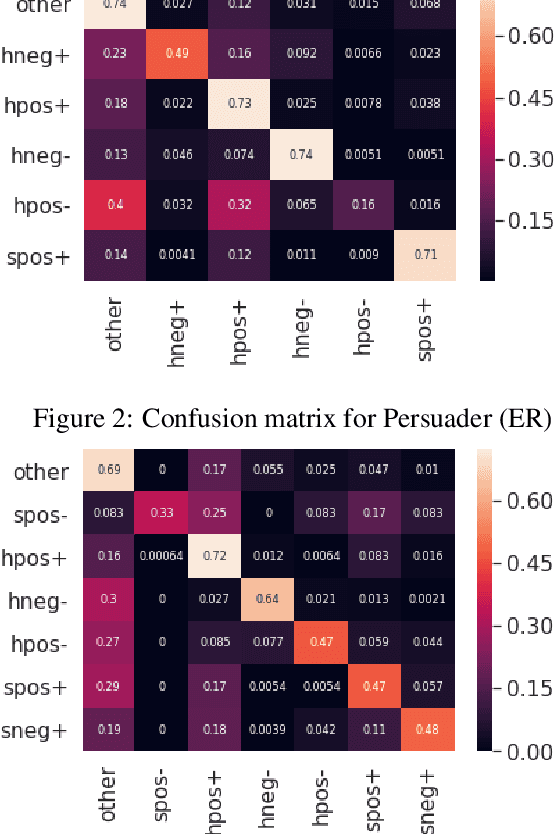
The notion of face refers to the public self-image of an individual that emerges both from the individual's own actions as well as from the interaction with others. Modeling face and understanding its state changes throughout a conversation is critical to the study of maintenance of basic human needs in and through interaction. Grounded in the politeness theory of Brown and Levinson (1978), we propose a generalized framework for modeling face acts in persuasion conversations, resulting in a reliable coding manual, an annotated corpus, and computational models. The framework reveals insights about differences in face act utilization between asymmetric roles in persuasion conversations. Using computational models, we are able to successfully identify face acts as well as predict a key conversational outcome (e.g. donation success). Finally, we model a latent representation of the conversational state to analyze the impact of predicted face acts on the probability of a positive conversational outcome and observe several correlations that corroborate previous findings.
LTIatCMU at SemEval-2020 Task 11: Incorporating Multi-Level Features for Multi-Granular Propaganda Span Identification
Aug 20, 2020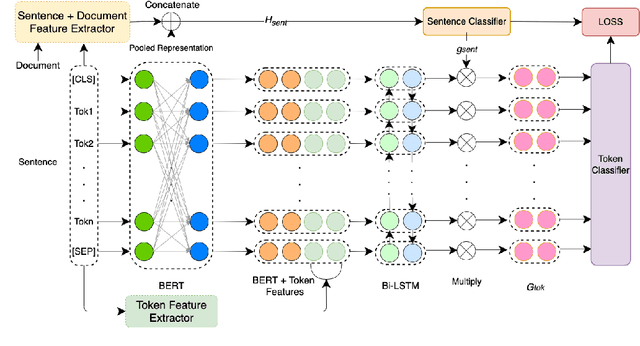

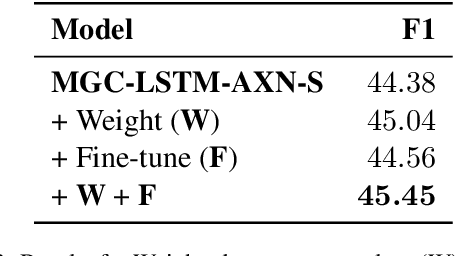
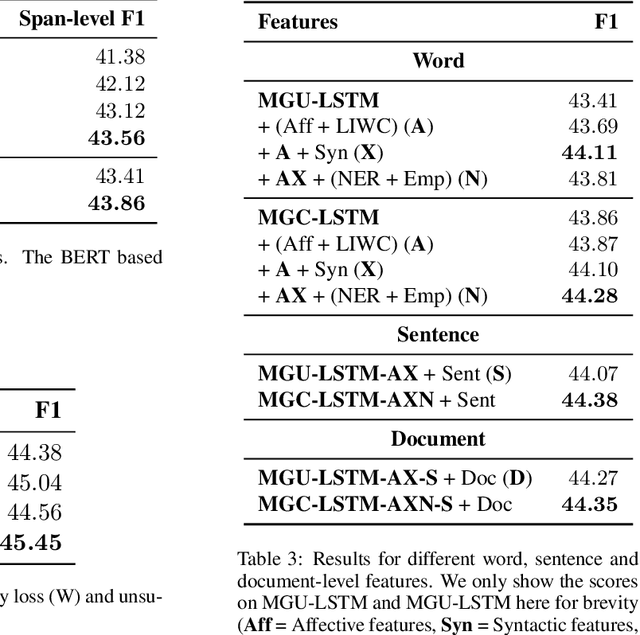
In this paper we describe our submission for the task of Propaganda Span Identification in news articles. We introduce a BERT-BiLSTM based span-level propaganda classification model that identifies which token spans within the sentence are indicative of propaganda. The "multi-granular" model incorporates linguistic knowledge at various levels of text granularity, including word, sentence and document level syntactic, semantic and pragmatic affect features, which significantly improve model performance, compared to its language-agnostic variant. To facilitate better representation learning, we also collect a corpus of 10k news articles, and use it for fine-tuning the model. The final model is a majority-voting ensemble which learns different propaganda class boundaries by leveraging different subsets of incorporated knowledge and attains $4^{th}$ position on the test leaderboard. Our final model and code is released at https://github.com/sopu/PropagandaSemEval2020.
MedType: Improving Medical Entity Linking with Semantic Type Prediction
May 01, 2020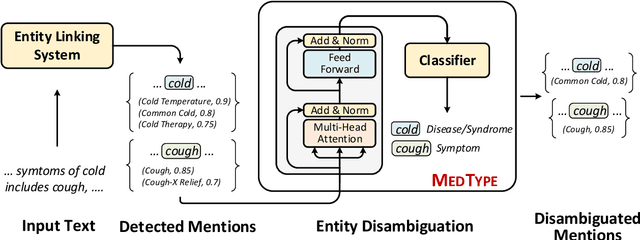
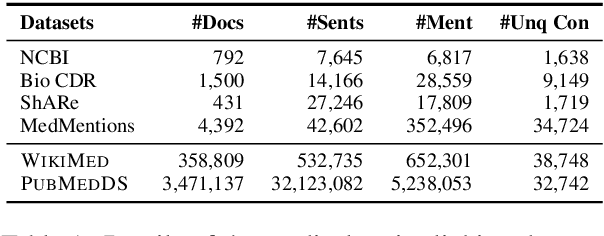
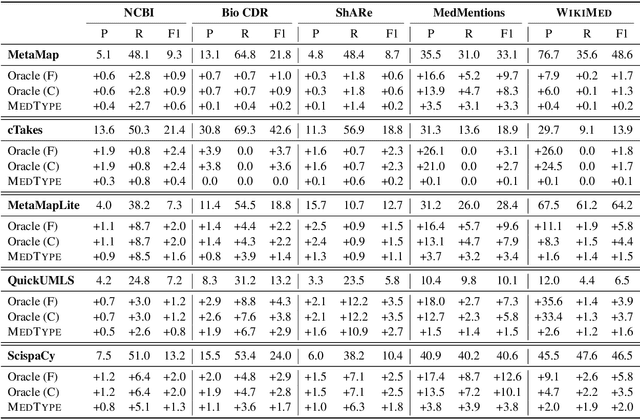
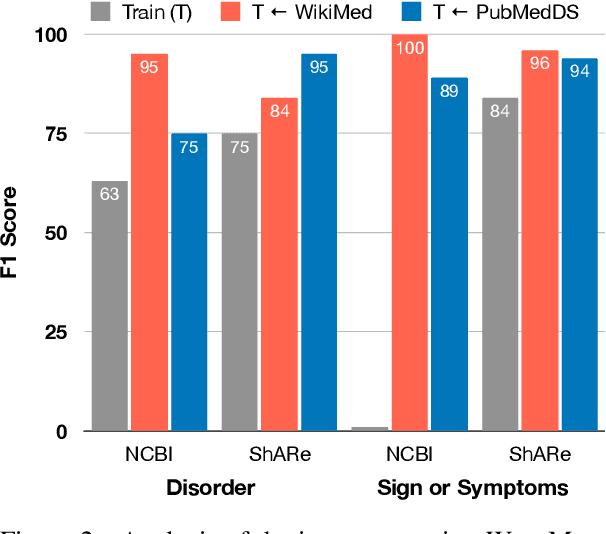
Medical entity linking is the task of identifying and standardizing concepts referred in a scientific article or clinical record. Existing methods adopt a two-step approach of detecting mentions and identifying a list of candidate concepts for them. In this paper, we probe the impact of incorporating an entity disambiguation step in existing entity linkers. For this, we present MedType, a novel method that leverages the surrounding context to identify the semantic type of a mention and uses it for filtering out candidate concepts of the wrong types. We further present two novel largescale, automatically-created datasets of medical entity mentions: WIKIMED, a Wikipediabased dataset for cross-domain transfer learning, and PUBMEDDS, a distantly-supervised dataset of medical entity mentions in biomedical abstracts. Through extensive experiments across several datasets and methods, we demonstrate that MedType pre-trained on our proposed datasets substantially improve medical entity linking and gives state-of-the-art performance. We make our source code and datasets publicly available for medical entity linking research.