 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMD-CSDNetwork: Multi-Domain Cross Stitched Network for Deepfake Detection
Sep 15, 2021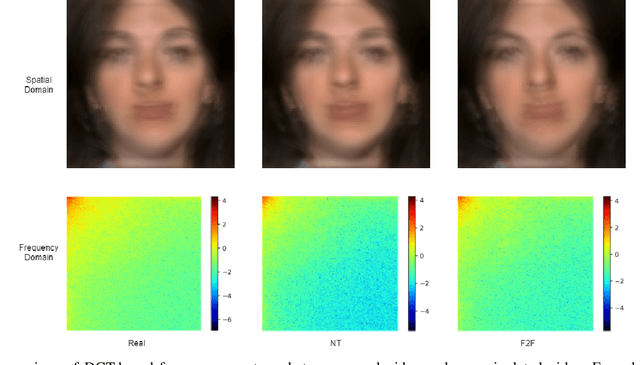
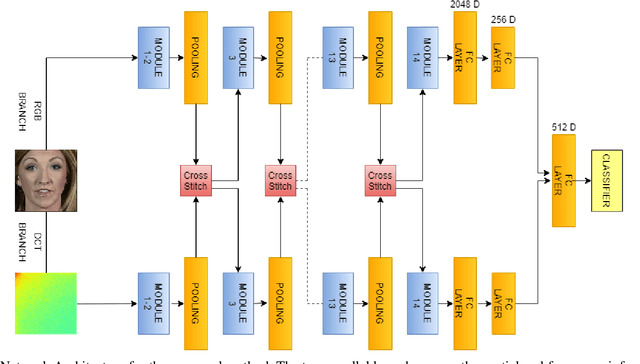
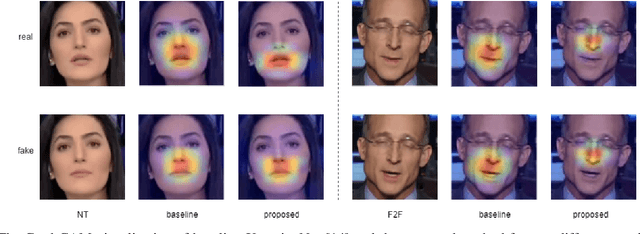
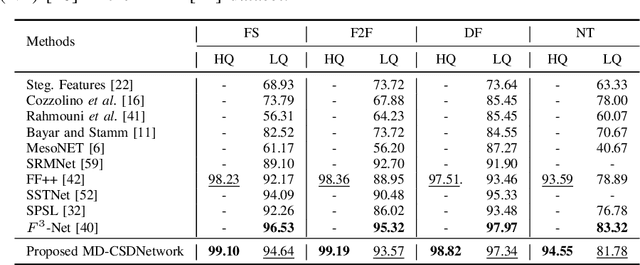
The rapid progress in the ease of creating and spreading ultra-realistic media over social platforms calls for an urgent need to develop a generalizable deepfake detection technique. It has been observed that current deepfake generation methods leave discriminative artifacts in the frequency spectrum of fake images and videos. Inspired by this observation, in this paper, we present a novel approach, termed as MD-CSDNetwork, for combining the features in the spatial and frequency domains to mine a shared discriminative representation for classifying \textit{deepfakes}. MD-CSDNetwork is a novel cross-stitched network with two parallel branches carrying the spatial and frequency information, respectively. We hypothesize that these multi-domain input data streams can be considered as related supervisory signals. The supervision from both branches ensures better performance and generalization. Further, the concept of cross-stitch connections is utilized where they are inserted between the two branches to learn an optimal combination of domain-specific and shared representations from other domains automatically. Extensive experiments are conducted on the popular benchmark dataset namely FaceForeniscs++ for forgery classification. We report improvements over all the manipulation types in FaceForensics++ dataset and comparable results with state-of-the-art methods for cross-database evaluation on the Celeb-DF dataset and the Deepfake Detection Dataset.
Co-designing Intelligent Control of Building HVACs and Microgrids
Jul 18, 2021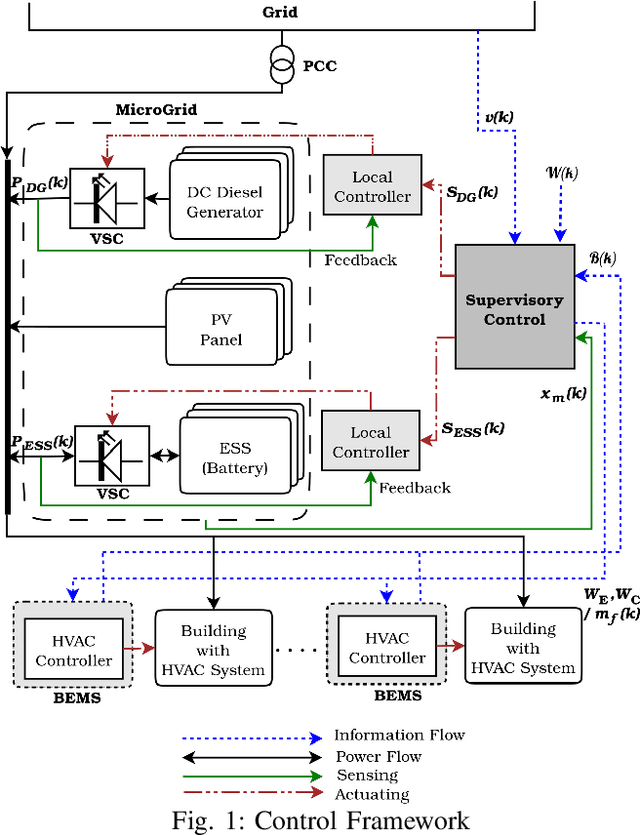

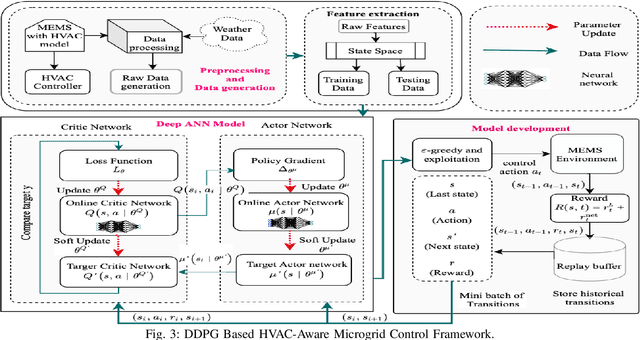
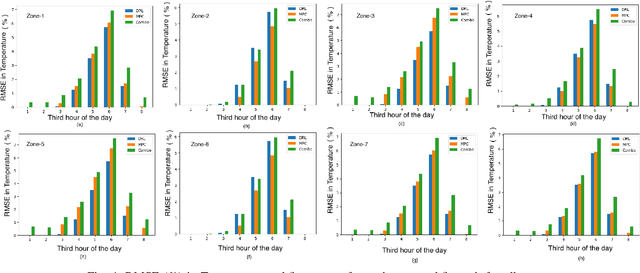
Building loads consume roughly 40% of the energy produced in developed countries, a significant part of which is invested towards building temperature-control infrastructure. Therein, renewable resource-based microgrids offer a greener and cheaper alternative. This communication explores the possible co-design of microgrid power dispatch and building HVAC (heating, ventilation and air conditioning system) actuations with the objective of effective temperature control under minimised operating cost. For this, we attempt control designs with various levels of abstractions based on information available about microgrid and HVAC system models using the Deep Reinforcement Learning (DRL) technique. We provide control architectures that consider model information ranging from completely determined system models to systems with fully unknown parameter settings and illustrate the advantages of DRL for the design prescriptions.
RESPER: Computationally Modelling Resisting Strategies in Persuasive Conversations
Jan 26, 2021
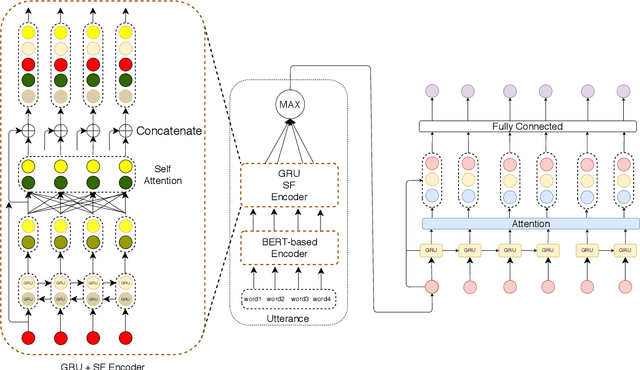

Modelling persuasion strategies as predictors of task outcome has several real-world applications and has received considerable attention from the computational linguistics community. However, previous research has failed to account for the resisting strategies employed by an individual to foil such persuasion attempts. Grounded in prior literature in cognitive and social psychology, we propose a generalised framework for identifying resisting strategies in persuasive conversations. We instantiate our framework on two distinct datasets comprising persuasion and negotiation conversations. We also leverage a hierarchical sequence-labelling neural architecture to infer the aforementioned resisting strategies automatically. Our experiments reveal the asymmetry of power roles in non-collaborative goal-directed conversations and the benefits accrued from incorporating resisting strategies on the final conversation outcome. We also investigate the role of different resisting strategies on the conversation outcome and glean insights that corroborate with past findings. We also make the code and the dataset of this work publicly available at https://github.com/americast/resper.
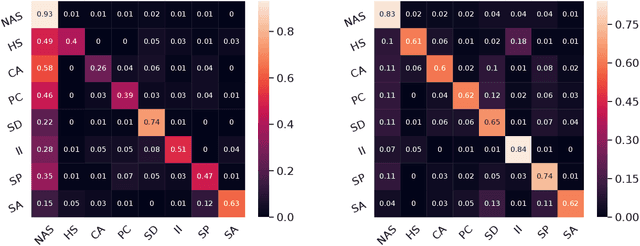
Two-Sided Fairness in Non-Personalised Recommendations
Nov 10, 2020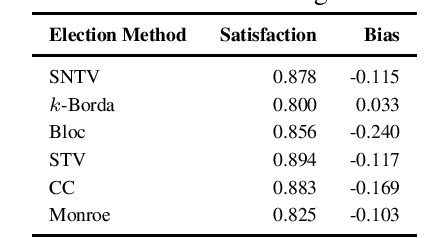
Recommender systems are one of the most widely used services on several online platforms to suggest potential items to the end-users. These services often use different machine learning techniques for which fairness is a concerning factor, especially when the downstream services have the ability to cause social ramifications. Thus, focusing on the non-personalised (global) recommendations in news media platforms (e.g., top-k trending topics on Twitter, top-k news on a news platform, etc.), we discuss on two specific fairness concerns together (traditionally studied separately)---user fairness and organisational fairness. While user fairness captures the idea of representing the choices of all the individual users in the case of global recommendations, organisational fairness tries to ensure politically/ideologically balanced recommendation sets. This makes user fairness a user-side requirement and organisational fairness a platform-side requirement. For user fairness, we test with methods from social choice theory, i.e., various voting rules known to better represent user choices in their results. Even in our application of voting rules to the recommendation setup, we observe high user satisfaction scores. Now for organisational fairness, we propose a bias metric which measures the aggregate ideological bias of a recommended set of items (articles). Analysing the results obtained from voting rule-based recommendation, we find that while the well-known voting rules are better from the user side, they show high bias values and clearly not suitable for organisational requirements of the platforms. Thus, there is a need to build an encompassing mechanism by cohesively bridging ideas of user fairness and organisational fairness. In this abstract paper, we intend to frame the elementary ideas along with the clear motivation behind the requirement of such a mechanism.
Analysing the Extent of Misinformation in Cancer Related Tweets
Apr 02, 2020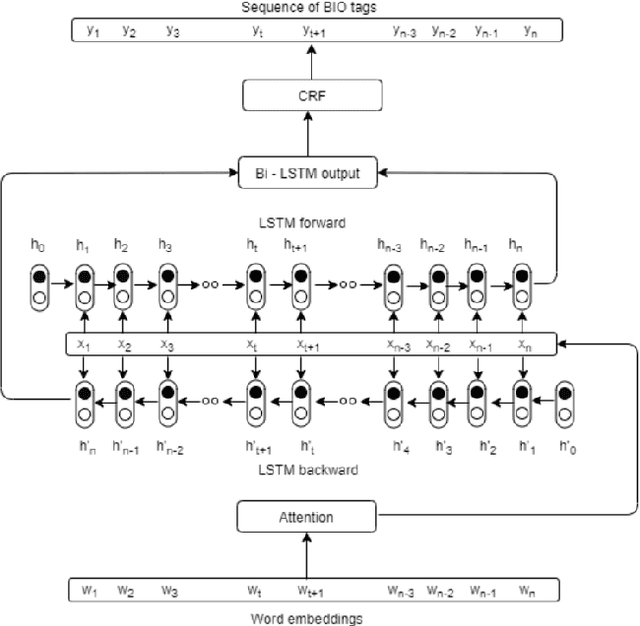

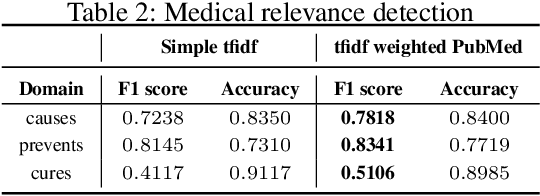
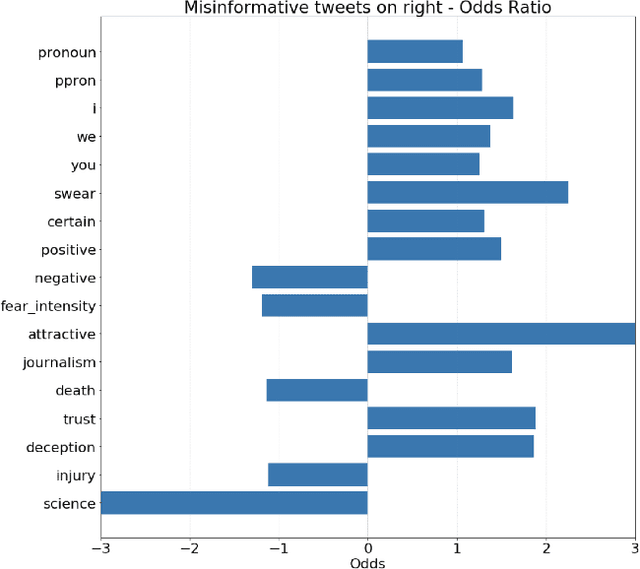
Twitter has become one of the most sought after places to discuss a wide variety of topics, including medically relevant issues such as cancer. This helps spread awareness regarding the various causes, cures and prevention methods of cancer. However, no proper analysis has been performed, which discusses the validity of such claims. In this work, we aim to tackle the misinformation spread in such platforms. We collect and present a dataset regarding tweets which talk specifically about cancer and propose an attention-based deep learning model for automated detection of misinformation along with its spread. We then do a comparative analysis of the linguistic variation in the text corresponding to misinformation and truth. This analysis helps us gather relevant insights on various social aspects related to misinformed tweets.
Modelling Bahdanau Attention using Election methods aided by Q-Learning
Dec 09, 2019
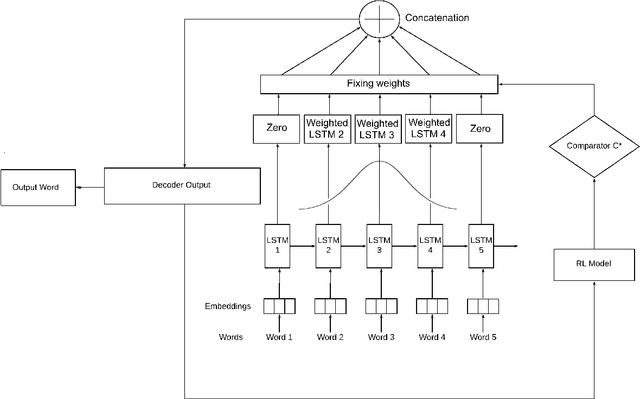


Neural Machine Translation has lately gained a lot of "attention" with the advent of more and more sophisticated but drastically improved models. Attention mechanism has proved to be a boon in this direction by providing weights to the input words, making it easy for the decoder to identify words representing the present context. But by and by, as newer attention models with more complexity came into development, they involved large computation, making inference slow. In this paper, we have modelled the attention network using techniques resonating with social choice theory. Along with that, the attention mechanism, being a Markov Decision Process, has been represented by reinforcement learning techniques. Thus, we propose to use an election method ($k$-Borda), fine-tuned using Q-learning, as a replacement for attention networks. The inference time for this network is less than a standard Bahdanau translator, and the results of the translation are comparable. This not only experimentally verifies the claims stated above but also helped provide a faster inference.