 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGraphDTA: Improving Drug Target Interaction Prediction using Protein Language Models and Contact Maps
Oct 06, 2023Developing and discovering new drugs is a complex and resource-intensive endeavor that often involves substantial costs, time investment, and safety concerns. A key aspect of drug discovery involves identifying novel drug-target (DT) interactions. Existing computational methods for predicting DT interactions have primarily focused on binary classification tasks, aiming to determine whether a DT pair interacts or not. However, protein-ligand interactions exhibit a continuum of binding strengths, known as binding affinity, presenting a persistent challenge for accurate prediction. In this study, we investigate various techniques employed in Drug Target Interaction (DTI) prediction and propose novel enhancements to enhance their performance. Our approaches include the integration of Protein Language Models (PLMs) and the incorporation of Contact Map information as an inductive bias within current models. Through extensive experimentation, we demonstrate that our proposed approaches outperform the baseline models considered in this study, presenting a compelling case for further development in this direction. We anticipate that the insights gained from this work will significantly narrow the search space for potential drugs targeting specific proteins, thereby accelerating drug discovery. Code and data for PGraphDTA are available at https://anonymous.4open.science/r/PGraphDTA.
Two-Sided Fairness in Non-Personalised Recommendations
Nov 10, 2020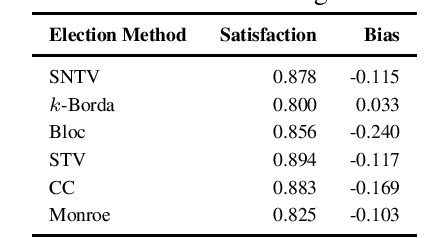
Recommender systems are one of the most widely used services on several online platforms to suggest potential items to the end-users. These services often use different machine learning techniques for which fairness is a concerning factor, especially when the downstream services have the ability to cause social ramifications. Thus, focusing on the non-personalised (global) recommendations in news media platforms (e.g., top-k trending topics on Twitter, top-k news on a news platform, etc.), we discuss on two specific fairness concerns together (traditionally studied separately)---user fairness and organisational fairness. While user fairness captures the idea of representing the choices of all the individual users in the case of global recommendations, organisational fairness tries to ensure politically/ideologically balanced recommendation sets. This makes user fairness a user-side requirement and organisational fairness a platform-side requirement. For user fairness, we test with methods from social choice theory, i.e., various voting rules known to better represent user choices in their results. Even in our application of voting rules to the recommendation setup, we observe high user satisfaction scores. Now for organisational fairness, we propose a bias metric which measures the aggregate ideological bias of a recommended set of items (articles). Analysing the results obtained from voting rule-based recommendation, we find that while the well-known voting rules are better from the user side, they show high bias values and clearly not suitable for organisational requirements of the platforms. Thus, there is a need to build an encompassing mechanism by cohesively bridging ideas of user fairness and organisational fairness. In this abstract paper, we intend to frame the elementary ideas along with the clear motivation behind the requirement of such a mechanism.
Analysing the Extent of Misinformation in Cancer Related Tweets
Apr 02, 2020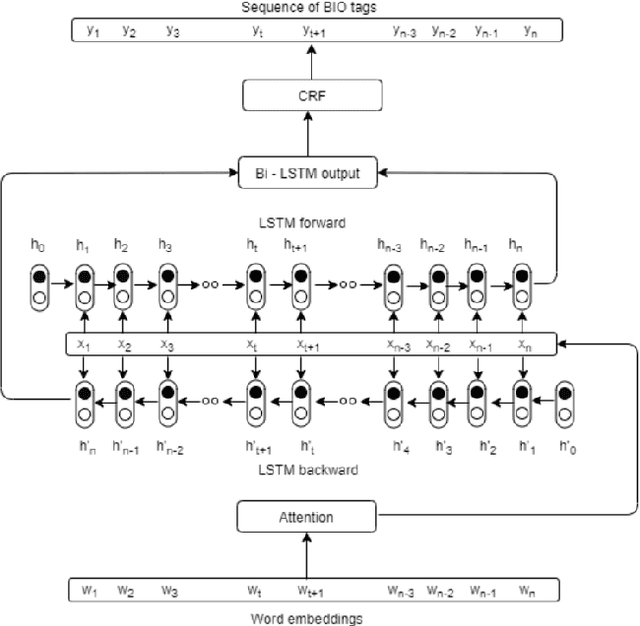

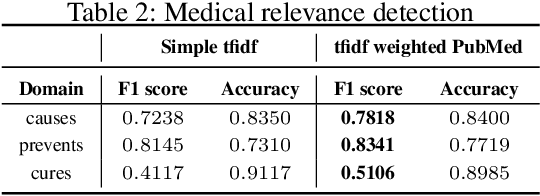
Twitter has become one of the most sought after places to discuss a wide variety of topics, including medically relevant issues such as cancer. This helps spread awareness regarding the various causes, cures and prevention methods of cancer. However, no proper analysis has been performed, which discusses the validity of such claims. In this work, we aim to tackle the misinformation spread in such platforms. We collect and present a dataset regarding tweets which talk specifically about cancer and propose an attention-based deep learning model for automated detection of misinformation along with its spread. We then do a comparative analysis of the linguistic variation in the text corresponding to misinformation and truth. This analysis helps us gather relevant insights on various social aspects related to misinformed tweets.
Modelling Bahdanau Attention using Election methods aided by Q-Learning
Dec 09, 2019
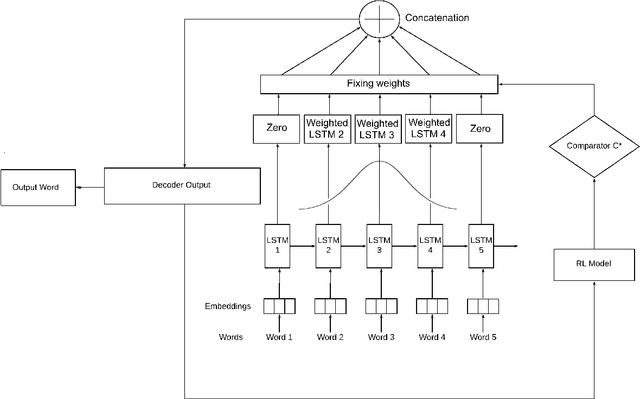


Neural Machine Translation has lately gained a lot of "attention" with the advent of more and more sophisticated but drastically improved models. Attention mechanism has proved to be a boon in this direction by providing weights to the input words, making it easy for the decoder to identify words representing the present context. But by and by, as newer attention models with more complexity came into development, they involved large computation, making inference slow. In this paper, we have modelled the attention network using techniques resonating with social choice theory. Along with that, the attention mechanism, being a Markov Decision Process, has been represented by reinforcement learning techniques. Thus, we propose to use an election method ($k$-Borda), fine-tuned using Q-learning, as a replacement for attention networks. The inference time for this network is less than a standard Bahdanau translator, and the results of the translation are comparable. This not only experimentally verifies the claims stated above but also helped provide a faster inference.