 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResponsible AI for General-Purpose Systems: Overview, Challenges, and A Path Forward
Jan 19, 2026Modern general-purpose AI systems made using large language and vision models, are capable of performing a range of tasks like writing text articles, generating and debugging codes, querying databases, and translating from one language to another, which has made them quite popular across industries. However, there are risks like hallucinations, toxicity, and stereotypes in their output that make them untrustworthy. We review various risks and vulnerabilities of modern general-purpose AI along eight widely accepted responsible AI (RAI) principles (fairness, privacy, explainability, robustness, safety, truthfulness, governance, and sustainability) and compare how they are non-existent or less severe and easily mitigable in traditional task-specific counterparts. We argue that this is due to the non-deterministically high Degree of Freedom in output (DoFo) of general-purpose AI (unlike the deterministically constant or low DoFo of traditional task-specific AI systems), and there is a need to rethink our approach to RAI for general-purpose AI. Following this, we derive C2V2 (Control, Consistency, Value, Veracity) desiderata to meet the RAI requirements for future general-purpose AI systems, and discuss how recent efforts in AI alignment, retrieval-augmented generation, reasoning enhancements, etc. fare along one or more of the desiderata. We believe that the goal of developing responsible general-purpose AI can be achieved by formally modeling application- or domain-dependent RAI requirements along C2V2 dimensions, and taking a system design approach to suitably combine various techniques to meet the desiderata.
Fair ranking: a critical review, challenges, and future directions
Jan 29, 2022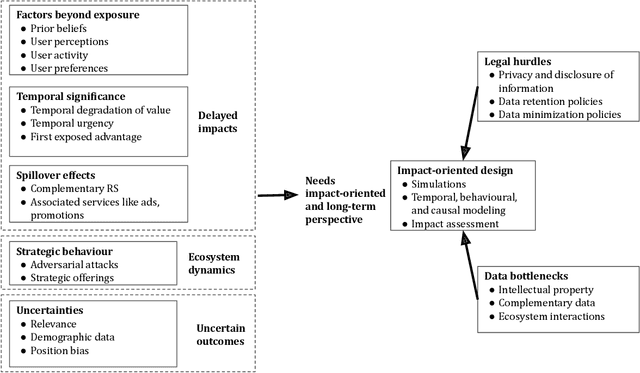



Ranking, recommendation, and retrieval systems are widely used in online platforms and other societal systems, including e-commerce, media-streaming, admissions, gig platforms, and hiring. In the recent past, a large "fair ranking" research literature has been developed around making these systems fair to the individuals, providers, or content that are being ranked. Most of this literature defines fairness for a single instance of retrieval, or as a simple additive notion for multiple instances of retrievals over time. This work provides a critical overview of this literature, detailing the often context-specific concerns that such an approach misses: the gap between high ranking placements and true provider utility, spillovers and compounding effects over time, induced strategic incentives, and the effect of statistical uncertainty. We then provide a path forward for a more holistic and impact-oriented fair ranking research agenda, including methodological lessons from other fields and the role of the broader stakeholder community in overcoming data bottlenecks and designing effective regulatory environments.
Fairness implications of encoding protected categorical attributes
Jan 27, 2022



Protected attributes are often presented as categorical features that need to be encoded before feeding them into a machine learning algorithm. Encoding these attributes is paramount as they determine the way the algorithm will learn from the data. Categorical feature encoding has a direct impact on the model performance and fairness. In this work, we compare the accuracy and fairness implications of the two most well-known encoders: one-hot encoding and target encoding. We distinguish between two types of induced bias that can arise while using these encodings and can lead to unfair models. The first type, irreducible bias, is due to direct group category discrimination and a second type, reducible bias, is due to large variance in less statistically represented groups. We take a deeper look into how regularization methods for target encoding can improve the induced bias while encoding categorical features. Furthermore, we tackle the problem of intersectional fairness that arises when mixing two protected categorical features leading to higher cardinality. This practice is a powerful feature engineering technique used for boosting model performance. We study its implications on fairness as it can increase both types of induced bias
Towards Fair Recommendation in Two-Sided Platforms
Dec 26, 2021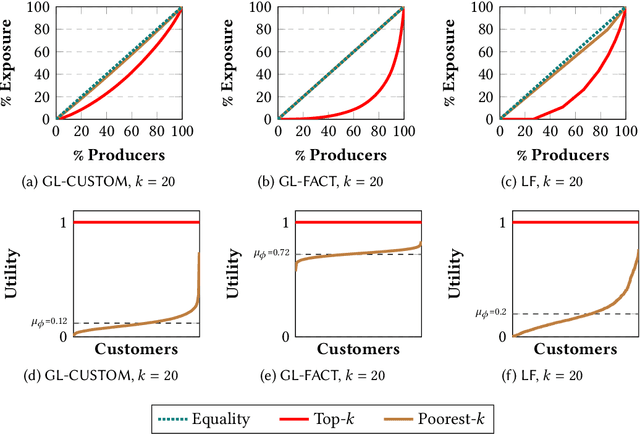
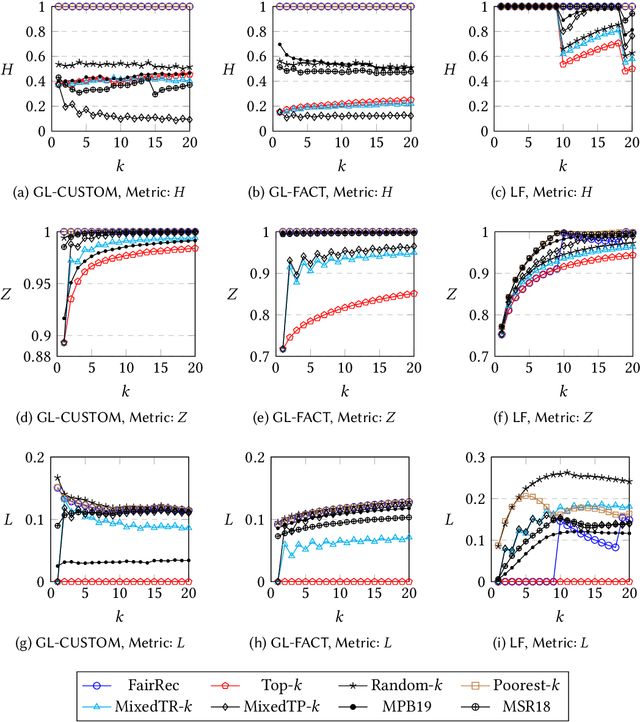
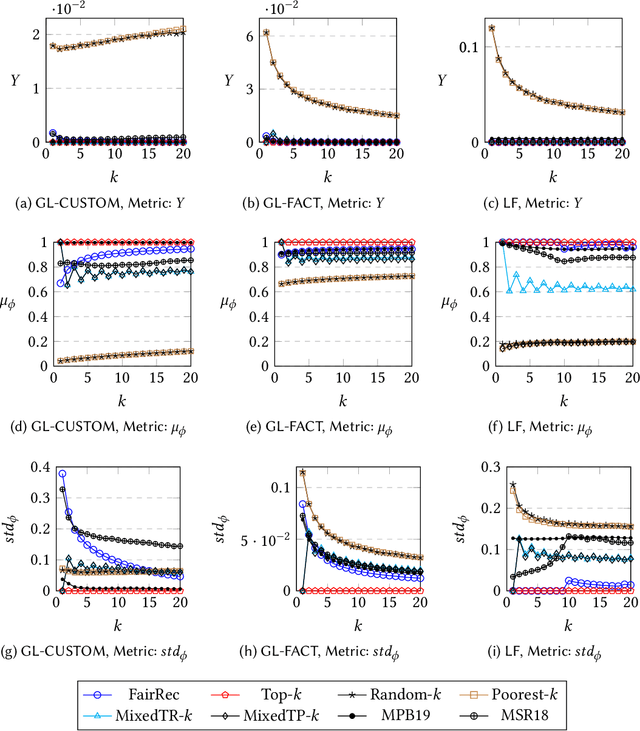
Many online platforms today (such as Amazon, Netflix, Spotify, LinkedIn, and AirBnB) can be thought of as two-sided markets with producers and customers of goods and services. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reinforces the fact that such customer-centric design of these services may lead to unfair distribution of exposure to the producers, which may adversely impact their well-being. On the other hand, a pure producer-centric design might become unfair to the customers. As more and more people are depending on such platforms to earn a living, it is important to ensure fairness to both producers and customers. In this work, by mapping a fair personalized recommendation problem to a constrained version of the problem of fairly allocating indivisible goods, we propose to provide fairness guarantees for both sides. Formally, our proposed {\em FairRec} algorithm guarantees Maxi-Min Share ($\alpha$-MMS) of exposure for the producers, and Envy-Free up to One Item (EF1) fairness for the customers. Extensive evaluations over multiple real-world datasets show the effectiveness of {\em FairRec} in ensuring two-sided fairness while incurring a marginal loss in overall recommendation quality. Finally, we present a modification of FairRec (named as FairRecPlus) that at the cost of additional computation time, improves the recommendation performance for the customers, while maintaining the same fairness guarantees.
Two-Sided Fairness in Non-Personalised Recommendations
Nov 10, 2020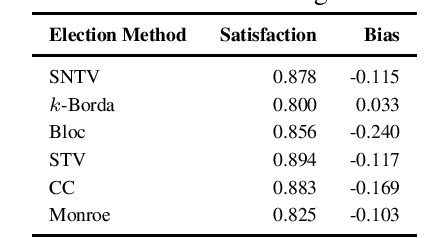
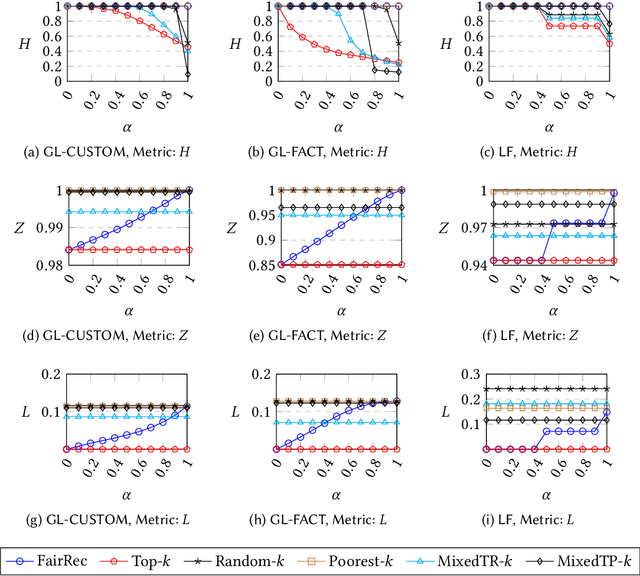
Recommender systems are one of the most widely used services on several online platforms to suggest potential items to the end-users. These services often use different machine learning techniques for which fairness is a concerning factor, especially when the downstream services have the ability to cause social ramifications. Thus, focusing on the non-personalised (global) recommendations in news media platforms (e.g., top-k trending topics on Twitter, top-k news on a news platform, etc.), we discuss on two specific fairness concerns together (traditionally studied separately)---user fairness and organisational fairness. While user fairness captures the idea of representing the choices of all the individual users in the case of global recommendations, organisational fairness tries to ensure politically/ideologically balanced recommendation sets. This makes user fairness a user-side requirement and organisational fairness a platform-side requirement. For user fairness, we test with methods from social choice theory, i.e., various voting rules known to better represent user choices in their results. Even in our application of voting rules to the recommendation setup, we observe high user satisfaction scores. Now for organisational fairness, we propose a bias metric which measures the aggregate ideological bias of a recommended set of items (articles). Analysing the results obtained from voting rule-based recommendation, we find that while the well-known voting rules are better from the user side, they show high bias values and clearly not suitable for organisational requirements of the platforms. Thus, there is a need to build an encompassing mechanism by cohesively bridging ideas of user fairness and organisational fairness. In this abstract paper, we intend to frame the elementary ideas along with the clear motivation behind the requirement of such a mechanism.
On Fair Virtual Conference Scheduling: Achieving Equitable Participant and Speaker Satisfaction
Oct 24, 2020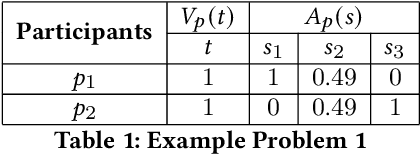
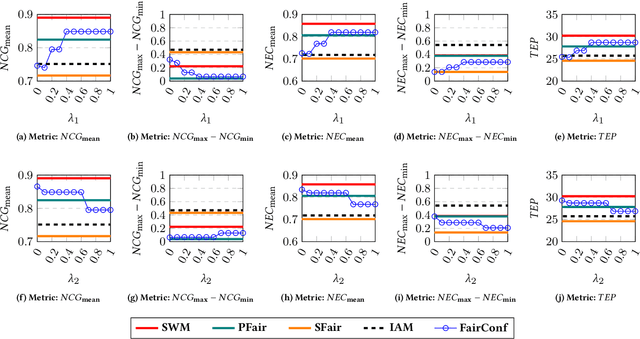


The (COVID-19) pandemic-induced restrictions on travel and social gatherings have prompted most conference organizers to move their events online. However, in contrast to physical conferences, virtual conferences face a challenge in efficiently scheduling talks, accounting for the availability of participants from different time-zones as well as their interests in attending different talks. In such settings, a natural objective for the conference organizers would be to maximize some global welfare measure, such as the total expected audience participation across all talks. However, we show that optimizing for global welfare could result in a schedule that is unfair to the stakeholders, i.e., the individual utilities for participants and speakers can be highly unequal. To address the fairness concerns, we formally define fairness notions for participants and speakers, and subsequently derive suitable fairness objectives for them. We show that the welfare and fairness objectives can be in conflict with each other, and there is a need to maintain a balance between these objective while caring for them simultaneously. Thus, we propose a joint optimization framework that allows conference organizers to design talk schedules that balance (i.e., allow trade-offs) between global welfare, participant fairness and the speaker fairness objectives. We show that the optimization problem can be solved using integer linear programming, and empirically evaluate the necessity and benefits of such joint optimization approach in virtual conference scheduling.
Bridging Machine Learning and Mechanism Design towards Algorithmic Fairness
Oct 12, 2020Decision-making systems increasingly orchestrate our world: how to intervene on the algorithmic components to build fair and equitable systems is therefore a question of utmost importance; one that is substantially complicated by the context-dependent nature of fairness and discrimination. Modern systems incorporate machine-learned predictions in broader decision-making pipelines, implicating concerns like constrained allocation and strategic behavior that are typically thought of as mechanism design problems. Although both machine learning and mechanism design have individually developed frameworks for addressing issues of fairness and equity, in some complex decision-making systems, neither framework is individually sufficient. In this paper, we develop the position that building fair decision-making systems requires overcoming these limitations which, we argue, are inherent to the individual frameworks of machine learning and mechanism design. Our ultimate objective is to build an encompassing framework that cohesively bridges the individual frameworks. We begin to lay the ground work towards achieving this goal by comparing the perspective each individual discipline takes on fair decision-making, teasing out the lessons each field has taught and can teach the other, and highlighting application domains that require a strong collaboration between these disciplines.