 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximin Share Guarantees via Limited Cost-Sensitive Sharing
Feb 25, 2026We study the problem of fairly allocating indivisible goods when limited sharing is allowed, that is, each good may be allocated to up to $k$ agents, while incurring a cost for sharing. While classic maximin share (MMS) allocations may not exist in many instances, we demonstrate that allowing controlled sharing can restore fairness guarantees that are otherwise unattainable in certain scenarios. (1) Our first contribution shows that exact maximin share (MMS) allocations are guaranteed to exist whenever goods are allowed to be cost-sensitively shared among at least half of the agents and the number of agents is even; for odd numbers of agents, we obtain a slightly weaker MMS guarantee. (2) We further design a Shared Bag-Filling Algorithm that guarantees a $(1 - C)(k - 1)$-approximate MMS allocation, where $C$ is the maximum cost of sharing a good. Notably, when $(1 - C)(k - 1) \geq 1$, our algorithm recovers an exact MMS allocation. (3) We additionally introduce the Sharing Maximin Share (SMMS) fairness notion, a natural extension of MMS to the $k$-sharing setting. (4) We show that SMMS allocations always exist under identical utilities and for instances with two agents. (5) We construct a counterexample to show the impossibility of the universal existence of an SMMS allocation. (6) Finally, we establish a connection between SMMS and constrained MMS (CMMS), yielding approximation guarantees for SMMS via existing CMMS results. These contributions provide deep theoretical insights for the problem of fair resource allocation when a limited sharing of resources are allowed in multi-agent environments.
AgroAskAI: A Multi-Agentic AI Framework for Supporting Smallholder Farmers' Enquiries Globally
Dec 16, 2025



Agricultural regions in rural areas face damage from climate-related risks, including droughts, heavy rainfall, and shifting weather patterns. Prior research calls for adaptive risk-management solutions and decision-making strategies. To this end, artificial intelligence (AI), particularly agentic AI, offers a promising path forward. Agentic AI systems consist of autonomous, specialized agents capable of solving complex, dynamic tasks. While past systems have relied on single-agent models or have used multi-agent frameworks only for static functions, there is a growing need for architectures that support dynamic collaborative reasoning and context-aware outputs. To bridge this gap, we present AgroAskAI, a multi-agent reasoning system for climate adaptation decision support in agriculture, with a focus on vulnerable rural communities. AgroAskAI features a modular, role-specialized architecture that uses a chain-of-responsibility approach to coordinate autonomous agents, integrating real-time tools and datasets. The system has built-in governance mechanisms that mitigate hallucination and enable internal feedback for coherent, locally relevant strategies. The system also supports multilingual interactions, making it accessible to non-English-speaking farmers. Experiments on common agricultural queries related to climate adaptation show that, with additional tools and prompt refinement, AgroAskAI delivers more actionable, grounded, and inclusive outputs. Our experimental results highlight the potential of agentic AI for sustainable and accountable decision support in climate adaptation for agriculture.
Fairness for Workers Who Pull the Arms: An Index Based Policy for Allocation of Restless Bandit Tasks
Mar 01, 2023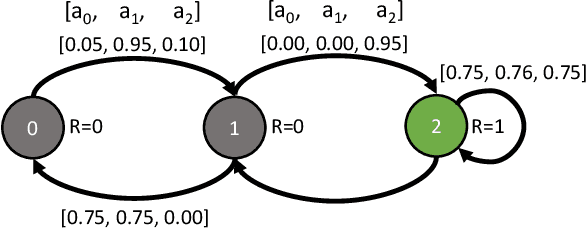
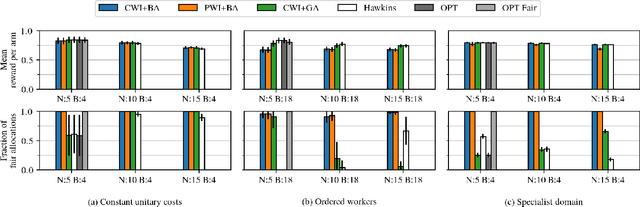
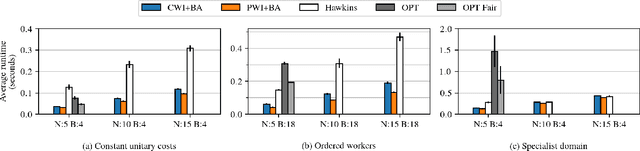
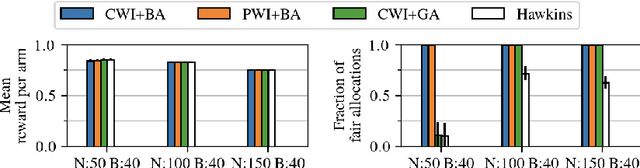
Motivated by applications such as machine repair, project monitoring, and anti-poaching patrol scheduling, we study intervention planning of stochastic processes under resource constraints. This planning problem has previously been modeled as restless multi-armed bandits (RMAB), where each arm is an intervention-dependent Markov Decision Process. However, the existing literature assumes all intervention resources belong to a single uniform pool, limiting their applicability to real-world settings where interventions are carried out by a set of workers, each with their own costs, budgets, and intervention effects. In this work, we consider a novel RMAB setting, called multi-worker restless bandits (MWRMAB) with heterogeneous workers. The goal is to plan an intervention schedule that maximizes the expected reward while satisfying budget constraints on each worker as well as fairness in terms of the load assigned to each worker. Our contributions are two-fold: (1) we provide a multi-worker extension of the Whittle index to tackle heterogeneous costs and per-worker budget and (2) we develop an index-based scheduling policy to achieve fairness. Further, we evaluate our method on various cost structures and show that our method significantly outperforms other baselines in terms of fairness without sacrificing much in reward accumulated.
Ranked Prioritization of Groups in Combinatorial Bandit Allocation
May 11, 2022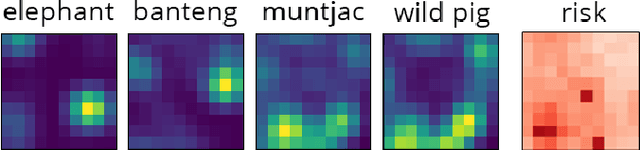
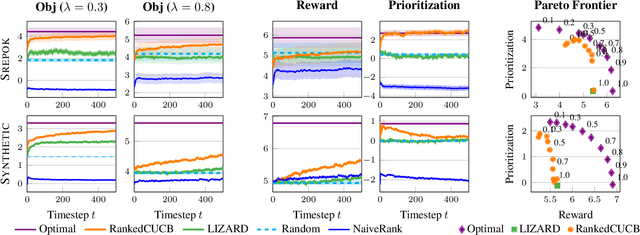
Preventing poaching through ranger patrols protects endangered wildlife, directly contributing to the UN Sustainable Development Goal 15 of life on land. Combinatorial bandits have been used to allocate limited patrol resources, but existing approaches overlook the fact that each location is home to multiple species in varying proportions, so a patrol benefits each species to differing degrees. When some species are more vulnerable, we ought to offer more protection to these animals; unfortunately, existing combinatorial bandit approaches do not offer a way to prioritize important species. To bridge this gap, (1) We propose a novel combinatorial bandit objective that trades off between reward maximization and also accounts for prioritization over species, which we call ranked prioritization. We show this objective can be expressed as a weighted linear sum of Lipschitz-continuous reward functions. (2) We provide RankedCUCB, an algorithm to select combinatorial actions that optimize our prioritization-based objective, and prove that it achieves asymptotic no-regret. (3) We demonstrate empirically that RankedCUCB leads to up to 38% improvement in outcomes for endangered species using real-world wildlife conservation data. Along with adapting to other challenges such as preventing illegal logging and overfishing, our no-regret algorithm addresses the general combinatorial bandit problem with a weighted linear objective.
Towards Fair Recommendation in Two-Sided Platforms
Dec 26, 2021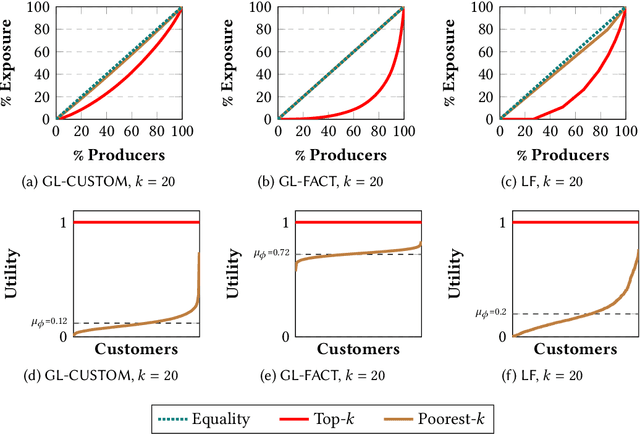
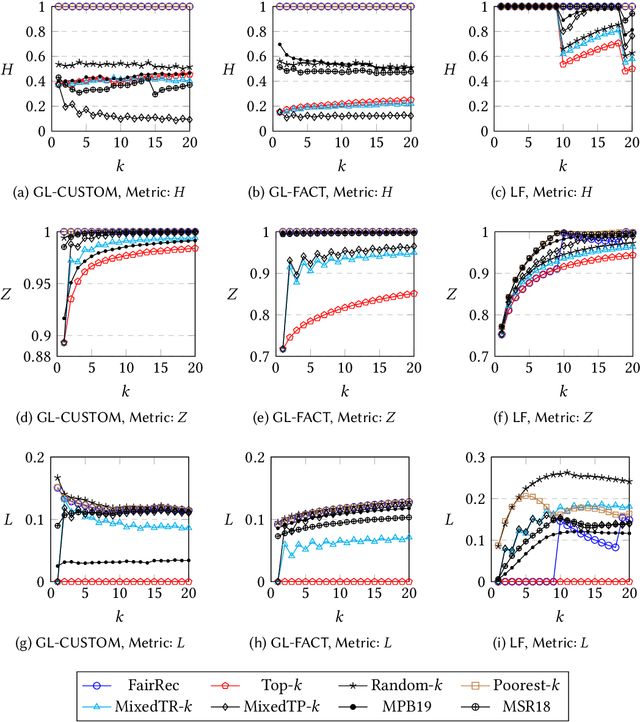
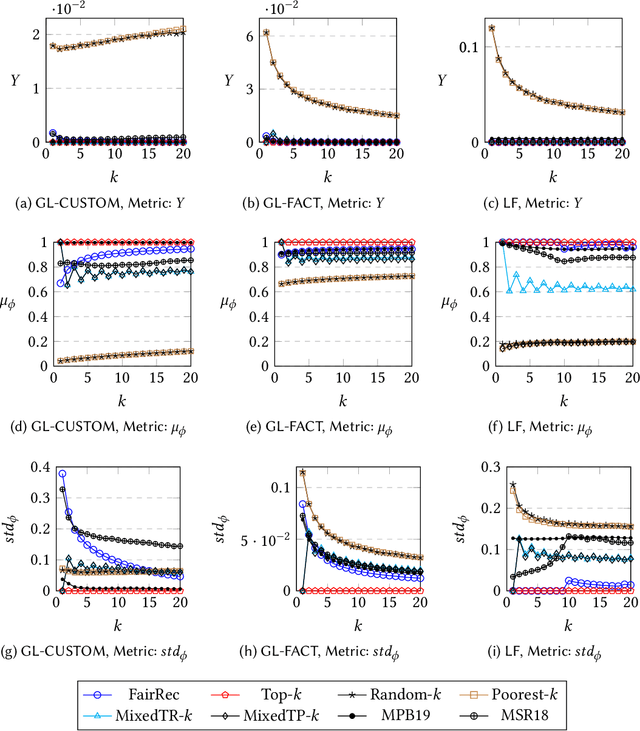
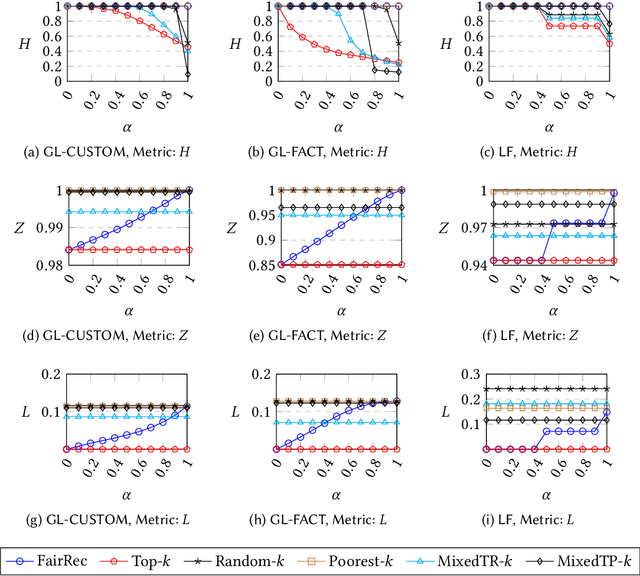
Many online platforms today (such as Amazon, Netflix, Spotify, LinkedIn, and AirBnB) can be thought of as two-sided markets with producers and customers of goods and services. Traditionally, recommendation services in these platforms have focused on maximizing customer satisfaction by tailoring the results according to the personalized preferences of individual customers. However, our investigation reinforces the fact that such customer-centric design of these services may lead to unfair distribution of exposure to the producers, which may adversely impact their well-being. On the other hand, a pure producer-centric design might become unfair to the customers. As more and more people are depending on such platforms to earn a living, it is important to ensure fairness to both producers and customers. In this work, by mapping a fair personalized recommendation problem to a constrained version of the problem of fairly allocating indivisible goods, we propose to provide fairness guarantees for both sides. Formally, our proposed {\em FairRec} algorithm guarantees Maxi-Min Share ($\alpha$-MMS) of exposure for the producers, and Envy-Free up to One Item (EF1) fairness for the customers. Extensive evaluations over multiple real-world datasets show the effectiveness of {\em FairRec} in ensuring two-sided fairness while incurring a marginal loss in overall recommendation quality. Finally, we present a modification of FairRec (named as FairRecPlus) that at the cost of additional computation time, improves the recommendation performance for the customers, while maintaining the same fairness guarantees.
Robust Restless Bandits: Tackling Interval Uncertainty with Deep Reinforcement Learning
Jul 04, 2021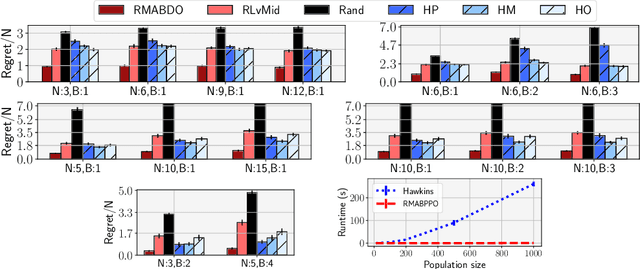
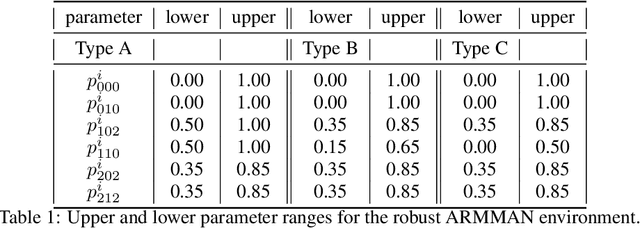
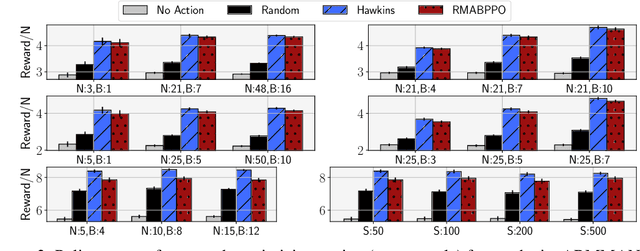

We introduce Robust Restless Bandits, a challenging generalization of restless multi-arm bandits (RMAB). RMABs have been widely studied for intervention planning with limited resources. However, most works make the unrealistic assumption that the transition dynamics are known perfectly, restricting the applicability of existing methods to real-world scenarios. To make RMABs more useful in settings with uncertain dynamics: (i) We introduce the Robust RMAB problem and develop solutions for a minimax regret objective when transitions are given by interval uncertainties; (ii) We develop a double oracle algorithm for solving Robust RMABs and demonstrate its effectiveness on three experimental domains; (iii) To enable our double oracle approach, we introduce RMABPPO, a novel deep reinforcement learning algorithm for solving RMABs. RMABPPO hinges on learning an auxiliary "$\lambda$-network" that allows each arm's learning to decouple, greatly reducing sample complexity required for training; (iv) Under minimax regret, the adversary in the double oracle approach is notoriously difficult to implement due to non-stationarity. To address this, we formulate the adversary oracle as a multi-agent reinforcement learning problem and solve it with a multi-agent extension of RMABPPO, which may be of independent interest as the first known algorithm for this setting. Code is available at https://github.com/killian-34/RobustRMAB.
Q-Learning Lagrange Policies for Multi-Action Restless Bandits
Jun 22, 2021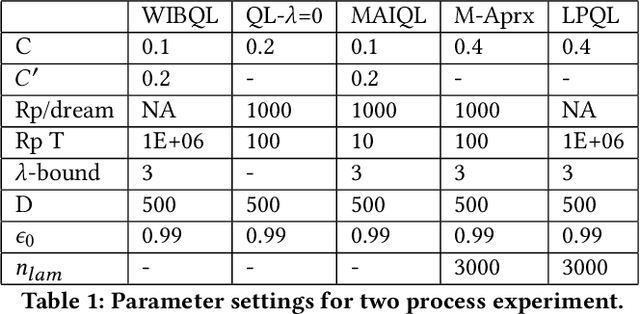
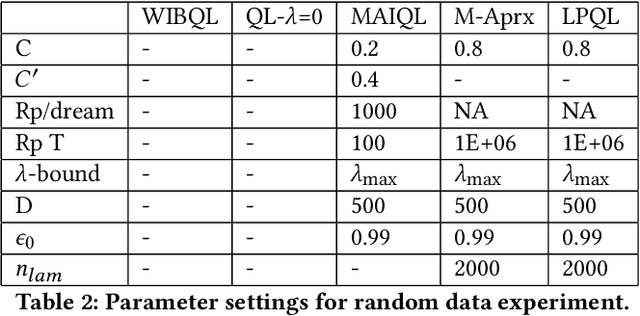
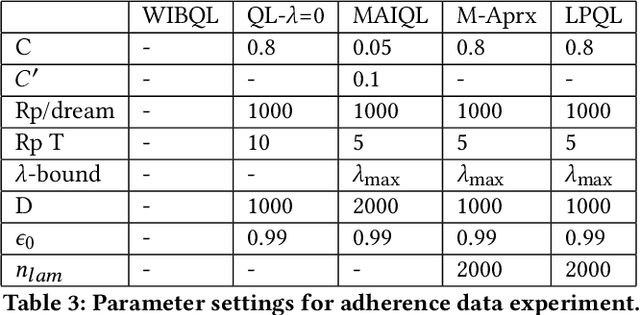
Multi-action restless multi-armed bandits (RMABs) are a powerful framework for constrained resource allocation in which $N$ independent processes are managed. However, previous work only study the offline setting where problem dynamics are known. We address this restrictive assumption, designing the first algorithms for learning good policies for Multi-action RMABs online using combinations of Lagrangian relaxation and Q-learning. Our first approach, MAIQL, extends a method for Q-learning the Whittle index in binary-action RMABs to the multi-action setting. We derive a generalized update rule and convergence proof and establish that, under standard assumptions, MAIQL converges to the asymptotically optimal multi-action RMAB policy as $t\rightarrow{}\infty$. However, MAIQL relies on learning Q-functions and indexes on two timescales which leads to slow convergence and requires problem structure to perform well. Thus, we design a second algorithm, LPQL, which learns the well-performing and more general Lagrange policy for multi-action RMABs by learning to minimize the Lagrange bound through a variant of Q-learning. To ensure fast convergence, we take an approximation strategy that enables learning on a single timescale, then give a guarantee relating the approximation's precision to an upper bound of LPQL's return as $t\rightarrow{}\infty$. Finally, we show that our approaches always outperform baselines across multiple settings, including one derived from real-world medication adherence data.
Learn to Intervene: An Adaptive Learning Policy for Restless Bandits in Application to Preventive Healthcare
May 17, 2021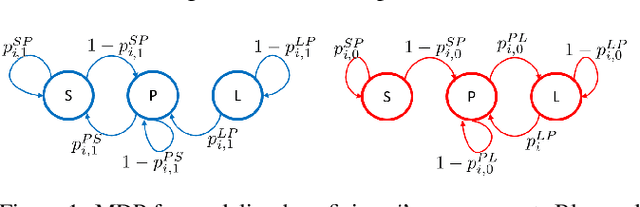
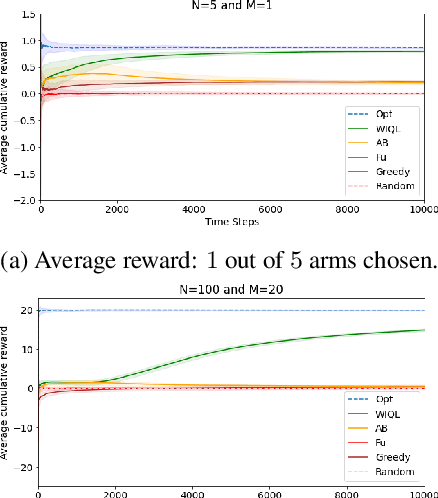
In many public health settings, it is important for patients to adhere to health programs, such as taking medications and periodic health checks. Unfortunately, beneficiaries may gradually disengage from such programs, which is detrimental to their health. A concrete example of gradual disengagement has been observed by an organization that carries out a free automated call-based program for spreading preventive care information among pregnant women. Many women stop picking up calls after being enrolled for a few months. To avoid such disengagements, it is important to provide timely interventions. Such interventions are often expensive and can be provided to only a small fraction of the beneficiaries. We model this scenario as a restless multi-armed bandit (RMAB) problem, where each beneficiary is assumed to transition from one state to another depending on the intervention. Moreover, since the transition probabilities are unknown a priori, we propose a Whittle index based Q-Learning mechanism and show that it converges to the optimal solution. Our method improves over existing learning-based methods for RMABs on multiple benchmarks from literature and also on the maternal healthcare dataset.
Efficient Algorithms for Finite Horizon and Streaming Restless Multi-Armed Bandit Problems
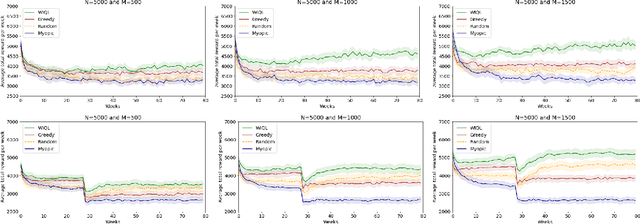
Mar 08, 2021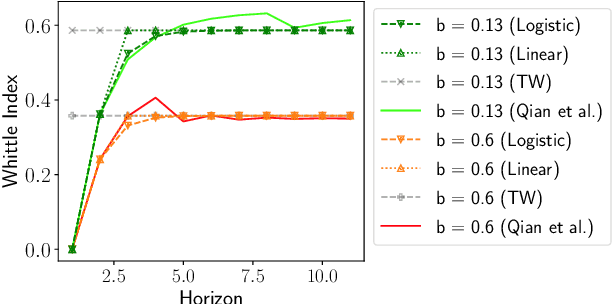
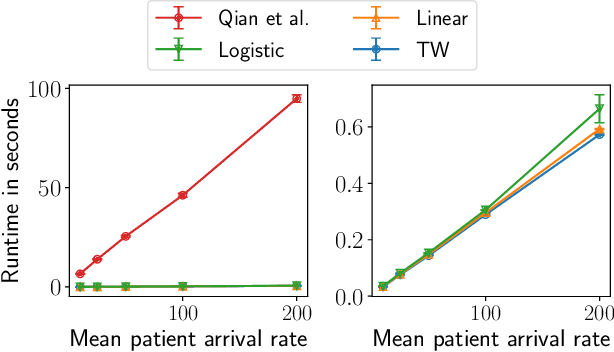
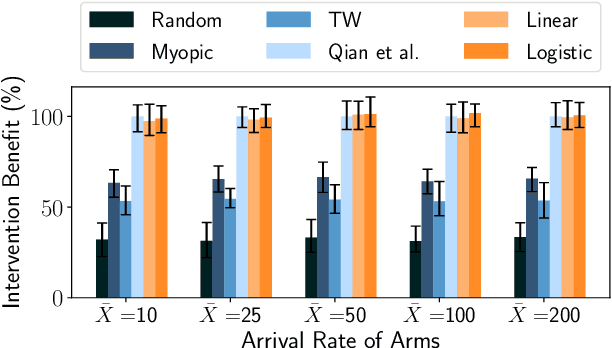
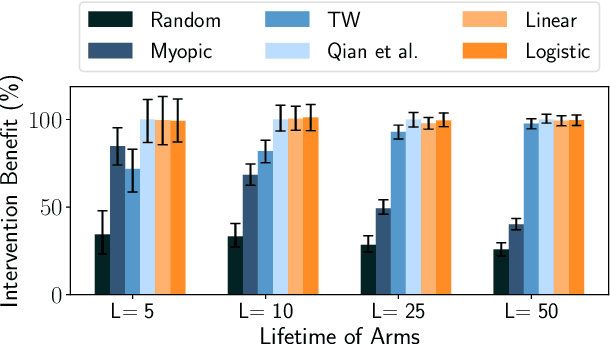
Restless Multi-Armed Bandits (RMABs) have been popularly used to model limited resource allocation problems. Recently, these have been employed for health monitoring and intervention planning problems. However, the existing approaches fail to account for the arrival of new patients and the departure of enrolled patients from a treatment program. To address this challenge, we formulate a streaming bandit (S-RMAB) framework, a generalization of RMABs where heterogeneous arms arrive and leave under possibly random streams. We propose a new and scalable approach to computing index-based solutions. We start by proving that index values decrease for short residual lifetimes, a phenomenon that we call index decay. We then provide algorithms designed to capture index decay without having to solve the costly finite horizon problem, thereby lowering the computational complexity compared to existing methods.We evaluate our approach via simulations run on real-world data obtained from a tuberculosis intervention planning task as well as multiple other synthetic domains. Our algorithms achieve an over 150x speed-up over existing methods in these tasks without loss in performance. These findings are robust across multiple domains.
Ensuring Fairness under Prior Probability Shifts
May 06, 2020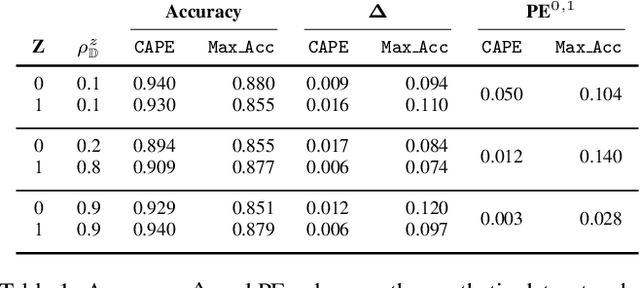
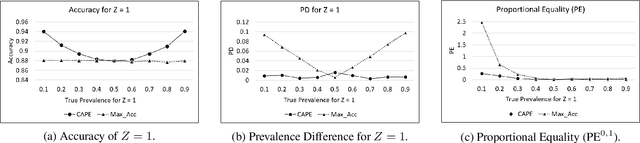
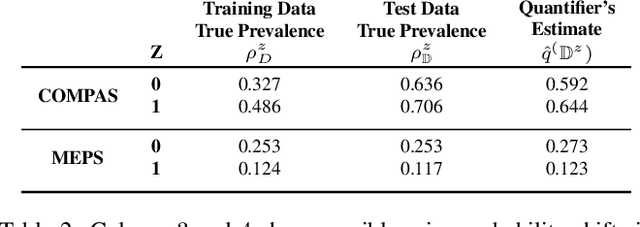
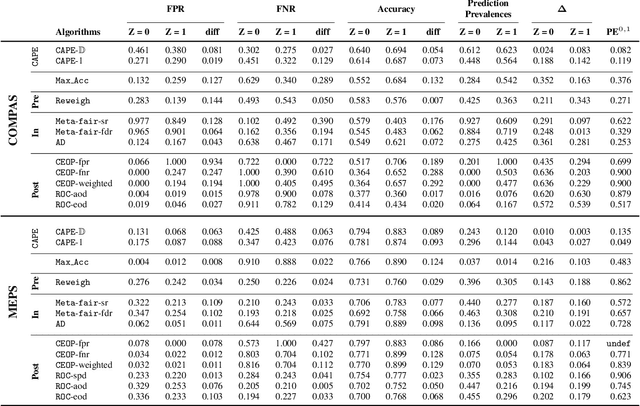
In this paper, we study the problem of fair classification in the presence of prior probability shifts, where the training set distribution differs from the test set. This phenomenon can be observed in the yearly records of several real-world datasets, such as recidivism records and medical expenditure surveys. If unaccounted for, such shifts can cause the predictions of a classifier to become unfair towards specific population subgroups. While the fairness notion called Proportional Equality (PE) accounts for such shifts, a procedure to ensure PE-fairness was unknown. In this work, we propose a method, called CAPE, which provides a comprehensive solution to the aforementioned problem. CAPE makes novel use of prevalence estimation techniques, sampling and an ensemble of classifiers to ensure fair predictions under prior probability shifts. We introduce a metric, called prevalence difference (PD), which CAPE attempts to minimize in order to ensure PE-fairness. We theoretically establish that this metric exhibits several desirable properties. We evaluate the efficacy of CAPE via a thorough empirical evaluation on synthetic datasets. We also compare the performance of CAPE with several popular fair classifiers on real-world datasets like COMPAS (criminal risk assessment) and MEPS (medical expenditure panel survey). The results indicate that CAPE ensures PE-fair predictions, while performing well on other performance metrics.