 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA resource-constrained stochastic scheduling algorithm for homeless street outreach and gleaning edible food
Mar 15, 2024


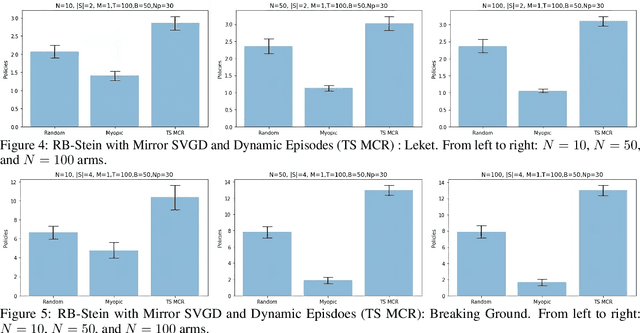
We developed a common algorithmic solution addressing the problem of resource-constrained outreach encountered by social change organizations with different missions and operations: Breaking Ground -- an organization that helps individuals experiencing homelessness in New York transition to permanent housing and Leket -- the national food bank of Israel that rescues food from farms and elsewhere to feed the hungry. Specifically, we developed an estimation and optimization approach for partially-observed episodic restless bandits under $k$-step transitions. The results show that our Thompson sampling with Markov chain recovery (via Stein variational gradient descent) algorithm significantly outperforms baselines for the problems of both organizations. We carried out this work in a prospective manner with the express goal of devising a flexible-enough but also useful-enough solution that can help overcome a lack of sustainable impact in data science for social good.
Improved Policy Evaluation for Randomized Trials of Algorithmic Resource Allocation
Feb 06, 2023We consider the task of evaluating policies of algorithmic resource allocation through randomized controlled trials (RCTs). Such policies are tasked with optimizing the utilization of limited intervention resources, with the goal of maximizing the benefits derived. Evaluation of such allocation policies through RCTs proves difficult, notwithstanding the scale of the trial, because the individuals' outcomes are inextricably interlinked through resource constraints controlling the policy decisions. Our key contribution is to present a new estimator leveraging our proposed novel concept, that involves retrospective reshuffling of participants across experimental arms at the end of an RCT. We identify conditions under which such reassignments are permissible and can be leveraged to construct counterfactual trials, whose outcomes can be accurately ascertained, for free. We prove theoretically that such an estimator is more accurate than common estimators based on sample means -- we show that it returns an unbiased estimate and simultaneously reduces variance. We demonstrate the value of our approach through empirical experiments on synthetic, semi-synthetic as well as real case study data and show improved estimation accuracy across the board.
Decision-Focused Evaluation: Analyzing Performance of Deployed Restless Multi-Arm Bandits
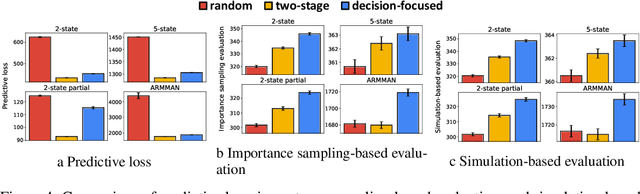
Jan 19, 2023Restless multi-arm bandits (RMABs) is a popular decision-theoretic framework that has been used to model real-world sequential decision making problems in public health, wildlife conservation, communication systems, and beyond. Deployed RMAB systems typically operate in two stages: the first predicts the unknown parameters defining the RMAB instance, and the second employs an optimization algorithm to solve the constructed RMAB instance. In this work we provide and analyze the results from a first-of-its-kind deployment of an RMAB system in public health domain, aimed at improving maternal and child health. Our analysis is focused towards understanding the relationship between prediction accuracy and overall performance of deployed RMAB systems. This is crucial for determining the value of investing in improving predictive accuracy towards improving the final system performance, and is useful for diagnosing, monitoring deployed RMAB systems. Using real-world data from our deployed RMAB system, we demonstrate that an improvement in overall prediction accuracy may even be accompanied by a degradation in the performance of RMAB system -- a broad investment of resources to improve overall prediction accuracy may not yield expected results. Following this, we develop decision-focused evaluation metrics to evaluate the predictive component and show that it is better at explaining (both empirically and theoretically) the overall performance of a deployed RMAB system.
Decision-Focused Learning in Restless Multi-Armed Bandits with Application to Maternal and Child Care Domain
Feb 02, 2022
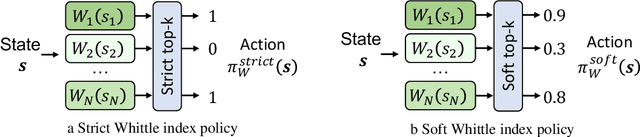

This paper studies restless multi-armed bandit (RMAB) problems with unknown arm transition dynamics but with known correlated arm features. The goal is to learn a model to predict transition dynamics given features, where the Whittle index policy solves the RMAB problems using predicted transitions. However, prior works often learn the model by maximizing the predictive accuracy instead of final RMAB solution quality, causing a mismatch between training and evaluation objectives. To address this shortcoming we propose a novel approach for decision-focused learning in RMAB that directly trains the predictive model to maximize the Whittle index solution quality. We present three key contributions: (i) we establish the differentiability of the Whittle index policy to support decision-focused learning; (ii) we significantly improve the scalability of previous decision-focused learning approaches in sequential problems; (iii) we apply our algorithm to the service call scheduling problem on a real-world maternal and child health domain. Our algorithm is the first for decision-focused learning in RMAB that scales to large-scale real-world problems. \end{abstract}
Field Study in Deploying Restless Multi-Armed Bandits: Assisting Non-Profits in Improving Maternal and Child Health
Sep 16, 2021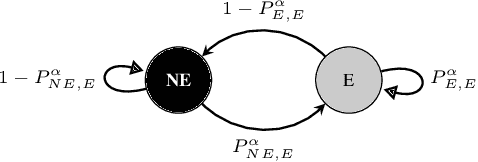
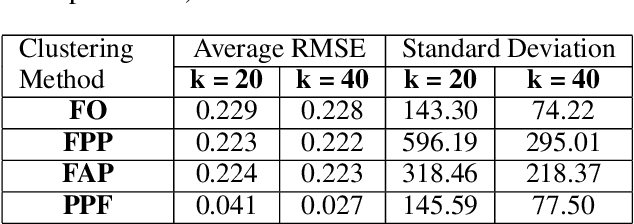
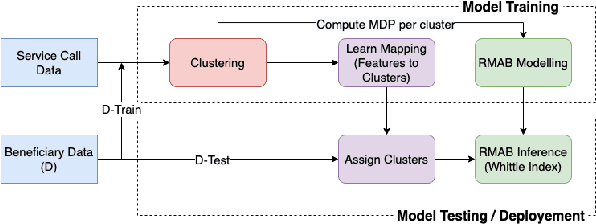
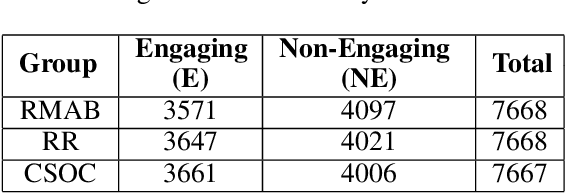
The widespread availability of cell phones has enabled non-profits to deliver critical health information to their beneficiaries in a timely manner. This paper describes our work to assist non-profits that employ automated messaging programs to deliver timely preventive care information to beneficiaries (new and expecting mothers) during pregnancy and after delivery. Unfortunately, a key challenge in such information delivery programs is that a significant fraction of beneficiaries drop out of the program. Yet, non-profits often have limited health-worker resources (time) to place crucial service calls for live interaction with beneficiaries to prevent such engagement drops. To assist non-profits in optimizing this limited resource, we developed a Restless Multi-Armed Bandits (RMABs) system. One key technical contribution in this system is a novel clustering method of offline historical data to infer unknown RMAB parameters. Our second major contribution is evaluation of our RMAB system in collaboration with an NGO, via a real-world service quality improvement study. The study compared strategies for optimizing service calls to 23003 participants over a period of 7 weeks to reduce engagement drops. We show that the RMAB group provides statistically significant improvement over other comparison groups, reducing ~ 30% engagement drops. To the best of our knowledge, this is the first study demonstrating the utility of RMABs in real world public health settings. We are transitioning our RMAB system to the NGO for real-world use.
Selective Intervention Planning using Restless Multi-Armed Bandits to Improve Maternal and Child Health Outcomes
Apr 05, 2021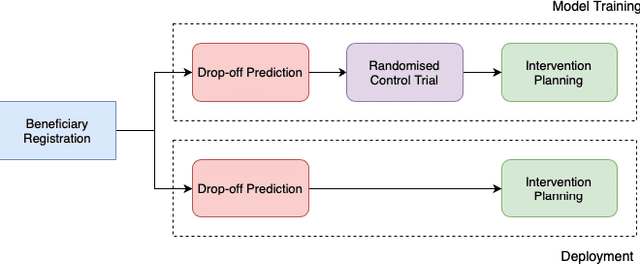
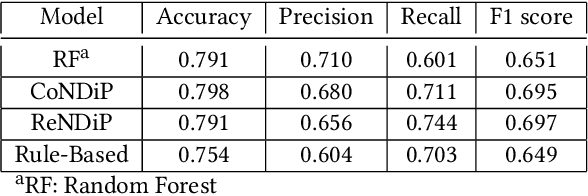
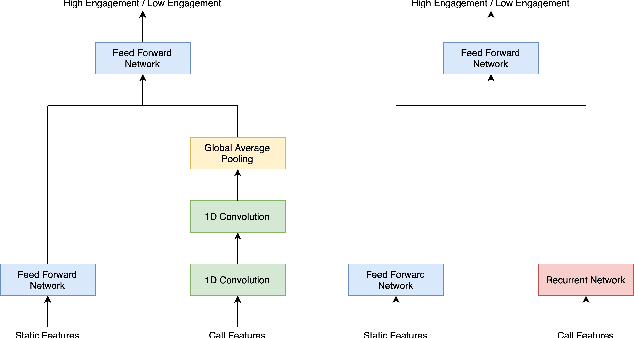
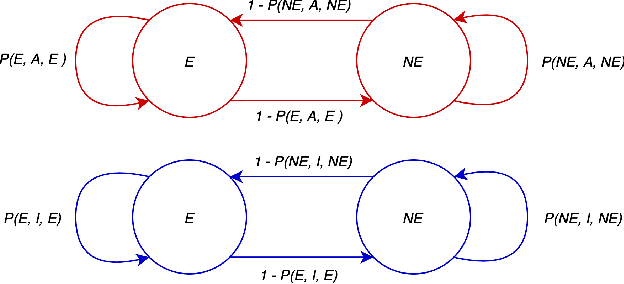
India has a maternal mortality ratio of 113 and child mortality ratio of 2830 per 100,000 live births. Lack of access to preventive care information is a major contributing factor for these deaths, especially in low resource households. We partner with ARMMAN, a non-profit based in India employing a call-based information program to disseminate health-related information to pregnant women and women with recent child deliveries. We analyze call records of over 300,000 women registered in the program created by ARMMAN and try to identify women who might not engage with these call programs that are proven to result in positive health outcomes. We built machine learning based models to predict the long term engagement pattern from call logs and beneficiaries' demographic information, and discuss the applicability of this method in the real world through a pilot validation. Through a randomized controlled trial, we show that using our model's predictions to make interventions boosts engagement metrics by 61.37%. We then formulate the intervention planning problem as restless multi-armed bandits (RMABs), and present preliminary results using this approach.
Efficient Algorithms for Finite Horizon and Streaming Restless Multi-Armed Bandit Problems
Mar 08, 2021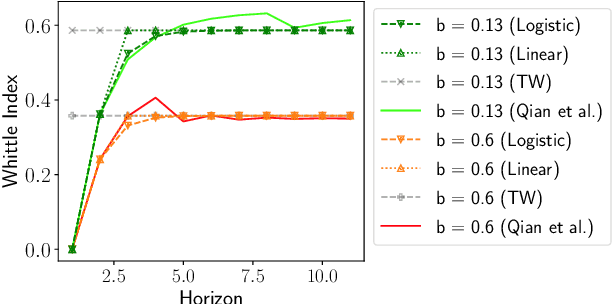
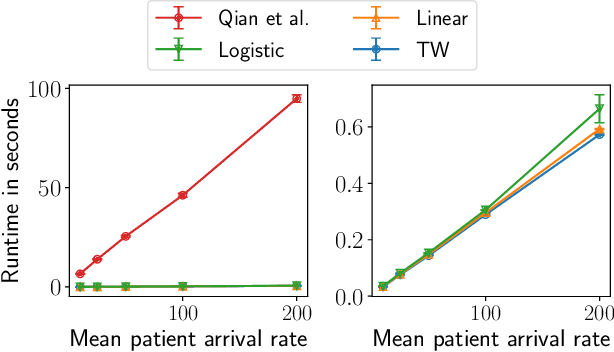
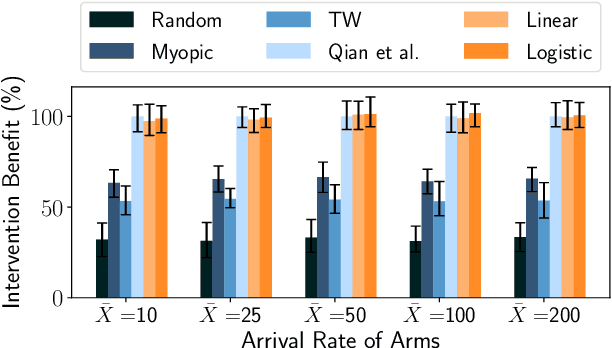
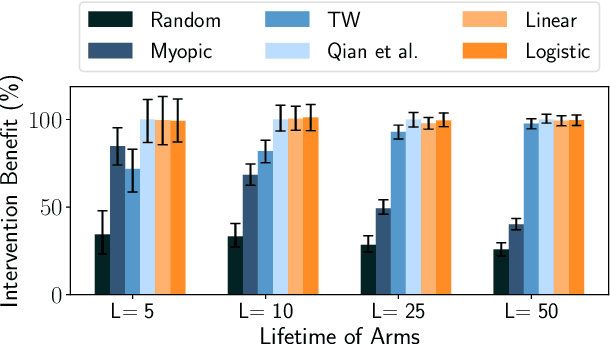
Restless Multi-Armed Bandits (RMABs) have been popularly used to model limited resource allocation problems. Recently, these have been employed for health monitoring and intervention planning problems. However, the existing approaches fail to account for the arrival of new patients and the departure of enrolled patients from a treatment program. To address this challenge, we formulate a streaming bandit (S-RMAB) framework, a generalization of RMABs where heterogeneous arms arrive and leave under possibly random streams. We propose a new and scalable approach to computing index-based solutions. We start by proving that index values decrease for short residual lifetimes, a phenomenon that we call index decay. We then provide algorithms designed to capture index decay without having to solve the costly finite horizon problem, thereby lowering the computational complexity compared to existing methods.We evaluate our approach via simulations run on real-world data obtained from a tuberculosis intervention planning task as well as multiple other synthetic domains. Our algorithms achieve an over 150x speed-up over existing methods in these tasks without loss in performance. These findings are robust across multiple domains.
Collapsing Bandits and Their Application to Public Health Interventions
Jul 05, 2020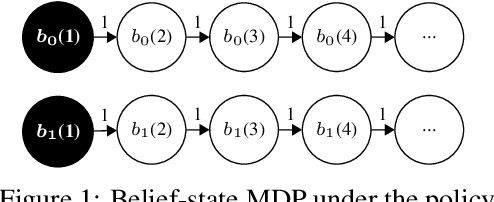
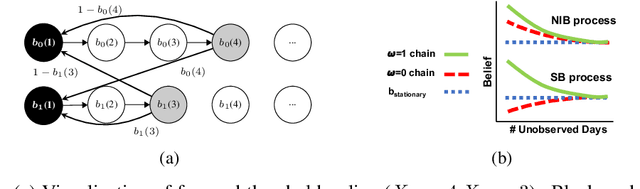
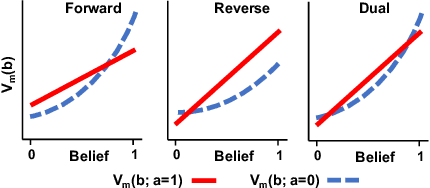
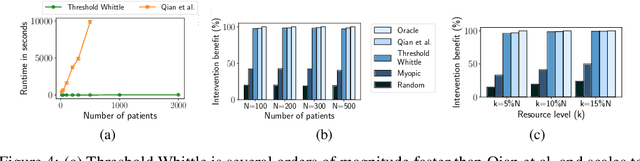
We propose and study Collpasing Bandits, a new restless multi-armed bandit (RMAB) setting in which each arm follows a binary-state Markovian process with a special structure: when an arm is played, the state is fully observed, thus "collapsing" any uncertainty, but when an arm is passive, no observation is made, thus allowing uncertainty to evolve. The goal is to keep as many arms in the "good" state as possible by planning a limited budget of actions per round. Such Collapsing Bandits are natural models for many healthcare domains in which workers must simultaneously monitor patients and deliver interventions in a way that maximizes the health of their patient cohort. Our main contributions are as follows: (i) Building on the Whittle index technique for RMABs, we derive conditions under which the Collapsing Bandits problem is indexable. Our derivation hinges on novel conditions that characterize when the optimal policies may take the form of either "forward" or "reverse" threshold policies. (ii) We exploit the optimality of threshold policies to build fast algorithms for computing the Whittle index, including a closed-form. (iii) We evaluate our algorithm on several data distributions including data from a real-world healthcare task in which a worker must monitor and deliver interventions to maximize their patients' adherence to tuberculosis medication. Our algorithm achieves a 3-order-of-magnitude speedup compared to state-of-the-art RMAB techniques while achieving similar performance.
Decision-Focused Learning of Adversary Behavior in Security Games
Mar 03, 2019
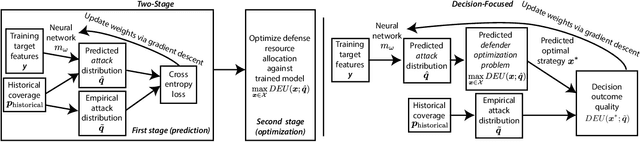
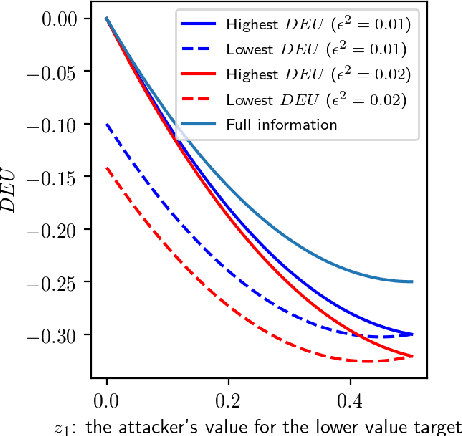
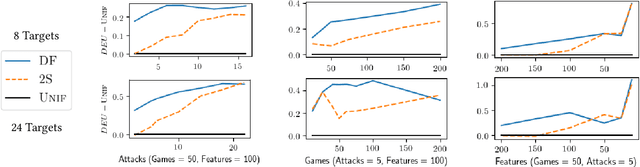
Stackelberg security games are a critical tool for maximizing the utility of limited defense resources to protect important targets from an intelligent adversary. Motivated by green security, where the defender may only observe an adversary's response to defense on a limited set of targets, we study the problem of defending against the same adversary on a larger set of targets from the same distribution. We give a theoretical justification for why standard two-stage learning approaches, where a model of the adversary is trained for predictive accuracy and then optimized against, may fail to maximize the defender's expected utility in this setting. We develop a decision-focused learning approach, where the adversary behavior model is optimized for decision quality, and show empirically that it achieves higher defender expected utility than the two-stage approach when there is limited training data and a large number of target features.