 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditing LLMs for Algorithmic Fairness in Casenote-Augmented Tabular Prediction
Apr 21, 2026LLMs are increasingly being considered for prediction tasks in high-stakes social service settings, but their algorithmic fairness properties in this context are poorly understood. In this short technical report, we audit the algorithmic fairness of LLM-based tabular classification on a real housing placement prediction task, augmented with street outreach casenotes from a nonprofit partner. We audit multi-class classification error disparities. We find that a fine-tuned model augmented with casenote summaries can improve accuracy while reducing algorithmic fairness disparities. We experiment with variable importance improvements to zero-shot tabular classification and find mixed results on resulting algorithmic fairness. Overall, given historical inequities in housing placement, it is crucial to audit LLM use. We find that leveraging LLMs to augment tabular classification with casenote summaries can safely leverage additional text information at low implementation burden. The outreach casenotes are fairly short and heavily redacted. Our assessment is that LLM zero-shot classification does not introduce additional textual biases beyond algorithmic biases in tabular classification. Combining fine-tuning and leveraging casenote summaries can improve accuracy and algorithmic fairness.
Reduced-Rank Multi-objective Policy Learning and Optimization
Apr 29, 2024



Evaluating the causal impacts of possible interventions is crucial for informing decision-making, especially towards improving access to opportunity. However, if causal effects are heterogeneous and predictable from covariates, personalized treatment decisions can improve individual outcomes and contribute to both efficiency and equity. In practice, however, causal researchers do not have a single outcome in mind a priori and often collect multiple outcomes of interest that are noisy estimates of the true target of interest. For example, in government-assisted social benefit programs, policymakers collect many outcomes to understand the multidimensional nature of poverty. The ultimate goal is to learn an optimal treatment policy that in some sense maximizes multiple outcomes simultaneously. To address such issues, we present a data-driven dimensionality-reduction methodology for multiple outcomes in the context of optimal policy learning with multiple objectives. We learn a low-dimensional representation of the true outcome from the observed outcomes using reduced rank regression. We develop a suite of estimates that use the model to denoise observed outcomes, including commonly-used index weightings. These methods improve estimation error in policy evaluation and optimization, including on a case study of real-world cash transfer and social intervention data. Reducing the variance of noisy social outcomes can improve the performance of algorithmic allocations.
A resource-constrained stochastic scheduling algorithm for homeless street outreach and gleaning edible food
Mar 15, 2024


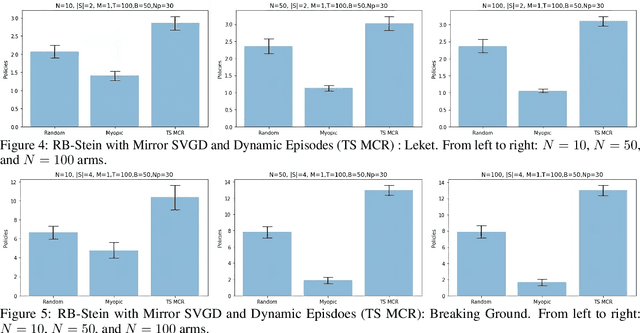
We developed a common algorithmic solution addressing the problem of resource-constrained outreach encountered by social change organizations with different missions and operations: Breaking Ground -- an organization that helps individuals experiencing homelessness in New York transition to permanent housing and Leket -- the national food bank of Israel that rescues food from farms and elsewhere to feed the hungry. Specifically, we developed an estimation and optimization approach for partially-observed episodic restless bandits under $k$-step transitions. The results show that our Thompson sampling with Markov chain recovery (via Stein variational gradient descent) algorithm significantly outperforms baselines for the problems of both organizations. We carried out this work in a prospective manner with the express goal of devising a flexible-enough but also useful-enough solution that can help overcome a lack of sustainable impact in data science for social good.