 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWafer Defect Root Cause Analysis with Partial Trajectory Regression
Jul 27, 2025



Identifying upstream processes responsible for wafer defects is challenging due to the combinatorial nature of process flows and the inherent variability in processing routes, which arises from factors such as rework operations and random process waiting times. This paper presents a novel framework for wafer defect root cause analysis, called Partial Trajectory Regression (PTR). The proposed framework is carefully designed to address the limitations of conventional vector-based regression models, particularly in handling variable-length processing routes that span a large number of heterogeneous physical processes. To compute the attribution score of each process given a detected high defect density on a specific wafer, we propose a new algorithm that compares two counterfactual outcomes derived from partial process trajectories. This is enabled by new representation learning methods, proc2vec and route2vec. We demonstrate the effectiveness of the proposed framework using real wafer history data from the NY CREATES fab in Albany.
Sequence-Aware Inline Measurement Attribution for Good-Bad Wafer Diagnosis
Jul 27, 2025How can we identify problematic upstream processes when a certain type of wafer defect starts appearing at a quality checkpoint? Given the complexity of modern semiconductor manufacturing, which involves thousands of process steps, cross-process root cause analysis for wafer defects has been considered highly challenging. This paper proposes a novel framework called Trajectory Shapley Attribution (TSA), an extension of Shapley values (SV), a widely used attribution algorithm in explainable artificial intelligence research. TSA overcomes key limitations of standard SV, including its disregard for the sequential nature of manufacturing processes and its reliance on an arbitrarily chosen reference point. We applied TSA to a good-bad wafer diagnosis task in experimental front-end-of-line processes at the NY CREATES Albany NanoTech fab, aiming to identify measurement items (serving as proxies for process parameters) most relevant to abnormal defect occurrence.
Improving Transformers using Faithful Positional Encoding
May 16, 2024We propose a new positional encoding method for a neural network architecture called the Transformer. Unlike the standard sinusoidal positional encoding, our approach is based on solid mathematical grounds and has a guarantee of not losing information about the positional order of the input sequence. We show that the new encoding approach systematically improves the prediction performance in the time-series classification task.
Decentralized Collaborative Learning Framework with External Privacy Leakage Analysis
Apr 01, 2024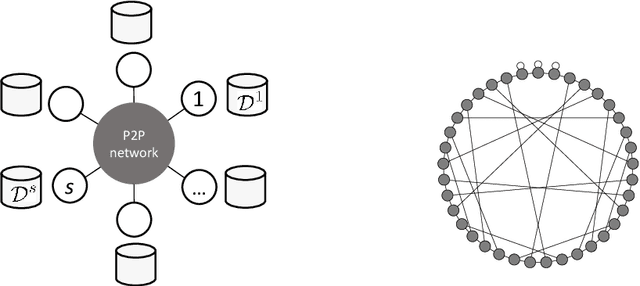
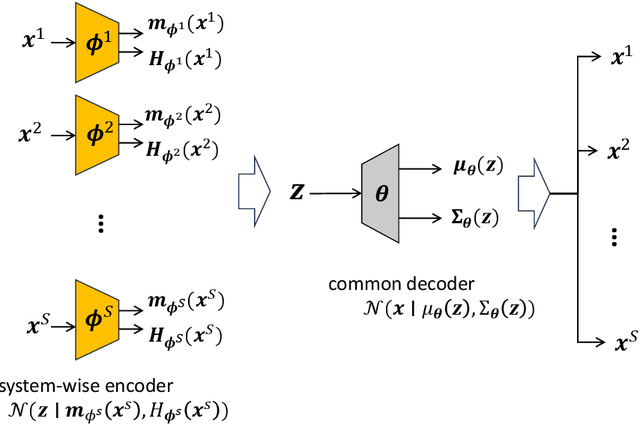
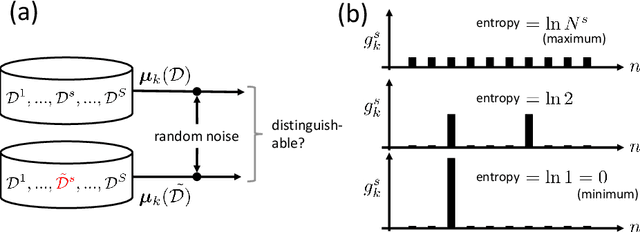
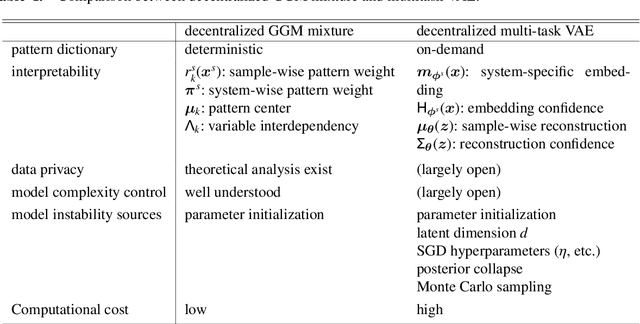
This paper presents two methodological advancements in decentralized multi-task learning under privacy constraints, aiming to pave the way for future developments in next-generation Blockchain platforms. First, we expand the existing framework for collaborative dictionary learning (CollabDict), which has previously been limited to Gaussian mixture models, by incorporating deep variational autoencoders (VAEs) into the framework, with a particular focus on anomaly detection. We demonstrate that the VAE-based anomaly score function shares the same mathematical structure as the non-deep model, and provide comprehensive qualitative comparison. Second, considering the widespread use of "pre-trained models," we provide a mathematical analysis on data privacy leakage when models trained with CollabDict are shared externally. We show that the CollabDict approach, when applied to Gaussian mixtures, adheres to a Renyi differential privacy criterion. Additionally, we propose a practical metric for monitoring internal privacy breaches during the learning process.
A resource-constrained stochastic scheduling algorithm for homeless street outreach and gleaning edible food
Mar 15, 2024


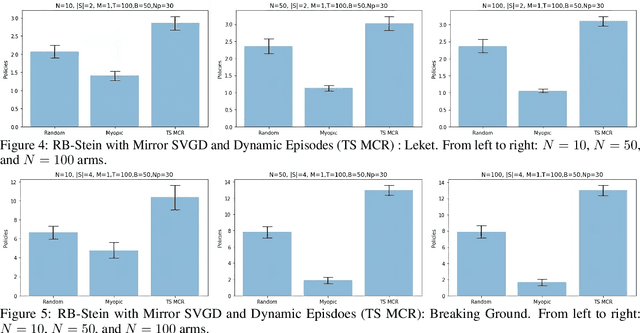
We developed a common algorithmic solution addressing the problem of resource-constrained outreach encountered by social change organizations with different missions and operations: Breaking Ground -- an organization that helps individuals experiencing homelessness in New York transition to permanent housing and Leket -- the national food bank of Israel that rescues food from farms and elsewhere to feed the hungry. Specifically, we developed an estimation and optimization approach for partially-observed episodic restless bandits under $k$-step transitions. The results show that our Thompson sampling with Markov chain recovery (via Stein variational gradient descent) algorithm significantly outperforms baselines for the problems of both organizations. We carried out this work in a prospective manner with the express goal of devising a flexible-enough but also useful-enough solution that can help overcome a lack of sustainable impact in data science for social good.
Learning Granger Causality from Instance-wise Self-attentive Hawkes Processes
Feb 06, 2024We address the problem of learning Granger causality from asynchronous, interdependent, multi-type event sequences. In particular, we are interested in discovering instance-level causal structures in an unsupervised manner. Instance-level causality identifies causal relationships among individual events, providing more fine-grained information for decision-making. Existing work in the literature either requires strong assumptions, such as linearity in the intensity function, or heuristically defined model parameters that do not necessarily meet the requirements of Granger causality. We propose Instance-wise Self-Attentive Hawkes Processes (ISAHP), a novel deep learning framework that can directly infer the Granger causality at the event instance level. ISAHP is the first neural point process model that meets the requirements of Granger causality. It leverages the self-attention mechanism of the transformer to align with the principles of Granger causality. We empirically demonstrate that ISAHP is capable of discovering complex instance-level causal structures that cannot be handled by classical models. We also show that ISAHP achieves state-of-the-art performance in proxy tasks involving type-level causal discovery and instance-level event type prediction.
Generative Perturbation Analysis for Probabilistic Black-Box Anomaly Attribution
Aug 09, 2023We address the task of probabilistic anomaly attribution in the black-box regression setting, where the goal is to compute the probability distribution of the attribution score of each input variable, given an observed anomaly. The training dataset is assumed to be unavailable. This task differs from the standard XAI (explainable AI) scenario, since we wish to explain the anomalous deviation from a black-box prediction rather than the black-box model itself. We begin by showing that mainstream model-agnostic explanation methods, such as the Shapley values, are not suitable for this task because of their ``deviation-agnostic property.'' We then propose a novel framework for probabilistic anomaly attribution that allows us to not only compute attribution scores as the predictive mean but also quantify the uncertainty of those scores. This is done by considering a generative process for perturbations that counter-factually bring the observed anomalous observation back to normalcy. We introduce a variational Bayes algorithm for deriving the distributions of per variable attribution scores. To the best of our knowledge, this is the first probabilistic anomaly attribution framework that is free from being deviation-agnostic.
Black-Box Anomaly Attribution
May 29, 2023When the prediction of a black-box machine learning model deviates from the true observation, what can be said about the reason behind that deviation? This is a fundamental and ubiquitous question that the end user in a business or industrial AI application often asks. The deviation may be due to a sub-optimal black-box model, or it may be simply because the sample in question is an outlier. In either case, one would ideally wish to obtain some form of attribution score -- a value indicative of the extent to which an input variable is responsible for the anomaly. In the present paper we address this task of ``anomaly attribution,'' particularly in the setting in which the model is black-box and the training data are not available. Specifically, we propose a novel likelihood-based attribution framework we call the ``likelihood compensation (LC),'' in which the responsibility score is equated with the correction on each input variable needed to attain the highest possible likelihood. We begin by showing formally why mainstream model-agnostic explanation methods, such as the local linear surrogate modeling and Shapley values, are not designed to explain anomalies. In particular, we show that they are ``deviation-agnostic,'' namely, that their explanations are blind to the fact that there is a deviation in the model prediction for the sample of interest. We do this by positioning these existing methods under the unified umbrella of a function family we call the ``integrated gradient family.'' We validate the effectiveness of the proposed LC approach using publicly available data sets. We also conduct a case study with a real-world building energy prediction task and confirm its usefulness in practice based on expert feedback.
Diagnostic Spatio-temporal Transformer with Faithful Encoding
May 26, 2023This paper addresses the task of anomaly diagnosis when the underlying data generation process has a complex spatio-temporal (ST) dependency. The key technical challenge is to extract actionable insights from the dependency tensor characterizing high-order interactions among temporal and spatial indices. We formalize the problem as supervised dependency discovery, where the ST dependency is learned as a side product of multivariate time-series classification. We show that temporal positional encoding used in existing ST transformer works has a serious limitation in capturing higher frequencies (short time scales). We propose a new positional encoding with a theoretical guarantee, based on discrete Fourier transform. We also propose a new ST dependency discovery framework, which can provide readily consumable diagnostic information in both spatial and temporal directions. Finally, we demonstrate the utility of the proposed model, DFStrans (Diagnostic Fourier-based Spatio-temporal Transformer), in a real industrial application of building elevator control.
Targeted Advertising on Social Networks Using Online Variational Tensor Regression
Aug 25, 2022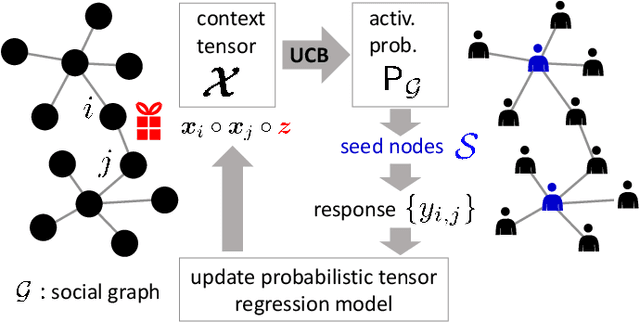

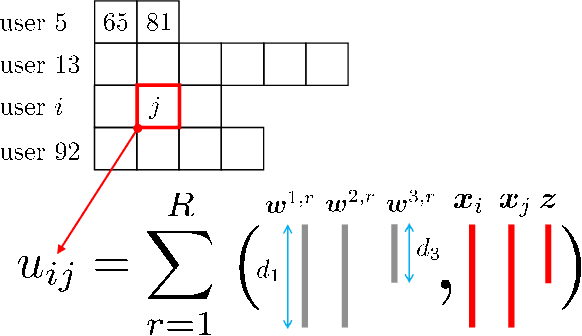
This paper is concerned with online targeted advertising on social networks. The main technical task we address is to estimate the activation probability for user pairs, which quantifies the influence one user may have on another towards purchasing decisions. This is a challenging task because one marketing episode typically involves a multitude of marketing campaigns/strategies of different products for highly diverse customers. In this paper, we propose what we believe is the first tensor-based contextual bandit framework for online targeted advertising. The proposed framework is designed to accommodate any number of feature vectors in the form of multi-mode tensor, thereby enabling to capture the heterogeneity that may exist over user preferences, products, and campaign strategies in a unified manner. To handle inter-dependency of tensor modes, we introduce an online variational algorithm with a mean-field approximation. We empirically confirm that the proposed TensorUCB algorithm achieves a significant improvement in influence maximization tasks over the benchmarks, which is attributable to its capability of capturing the user-product heterogeneity.