 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Collaborative Learning Framework with External Privacy Leakage Analysis
Apr 01, 2024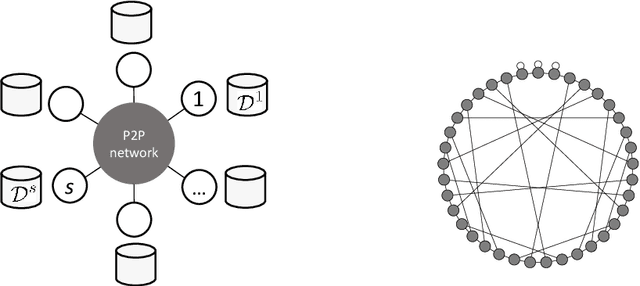
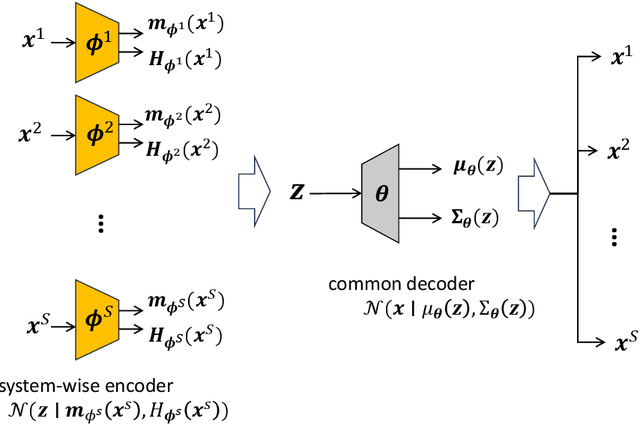
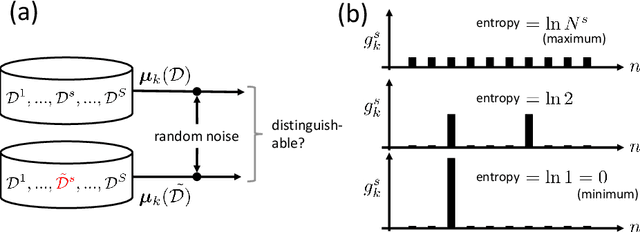
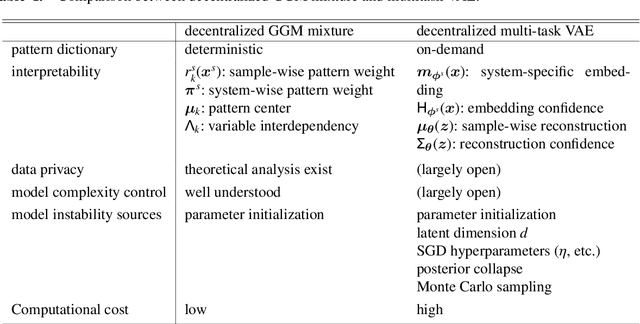
This paper presents two methodological advancements in decentralized multi-task learning under privacy constraints, aiming to pave the way for future developments in next-generation Blockchain platforms. First, we expand the existing framework for collaborative dictionary learning (CollabDict), which has previously been limited to Gaussian mixture models, by incorporating deep variational autoencoders (VAEs) into the framework, with a particular focus on anomaly detection. We demonstrate that the VAE-based anomaly score function shares the same mathematical structure as the non-deep model, and provide comprehensive qualitative comparison. Second, considering the widespread use of "pre-trained models," we provide a mathematical analysis on data privacy leakage when models trained with CollabDict are shared externally. We show that the CollabDict approach, when applied to Gaussian mixtures, adheres to a Renyi differential privacy criterion. Additionally, we propose a practical metric for monitoring internal privacy breaches during the learning process.
Cardinality-Regularized Hawkes-Granger Model
Aug 23, 2022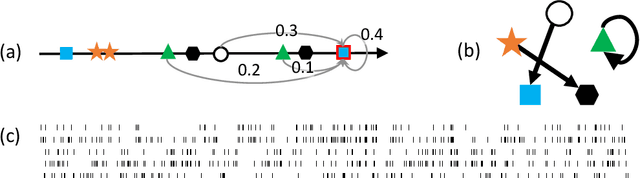
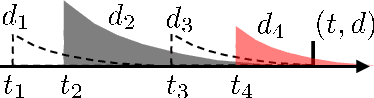

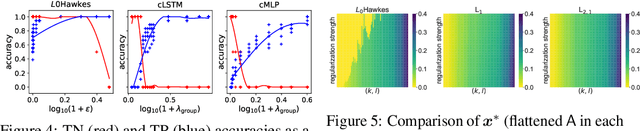
We propose a new sparse Granger-causal learning framework for temporal event data. We focus on a specific class of point processes called the Hawkes process. We begin by pointing out that most of the existing sparse causal learning algorithms for the Hawkes process suffer from a singularity in maximum likelihood estimation. As a result, their sparse solutions can appear only as numerical artifacts. In this paper, we propose a mathematically well-defined sparse causal learning framework based on a cardinality-regularized Hawkes process, which remedies the pathological issues of existing approaches. We leverage the proposed algorithm for the task of instance-wise causal event analysis, where sparsity plays a critical role. We validate the proposed framework with two real use-cases, one from the power grid and the other from the cloud data center management domain.
Ensembling Graph Predictions for AMR Parsing
Oct 18, 2021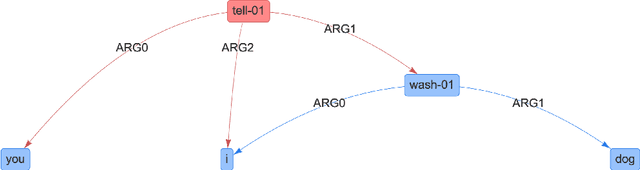
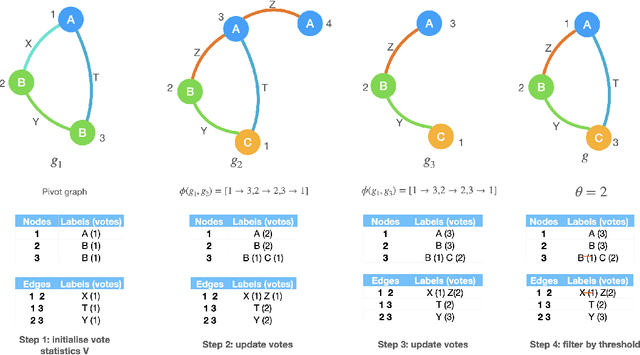
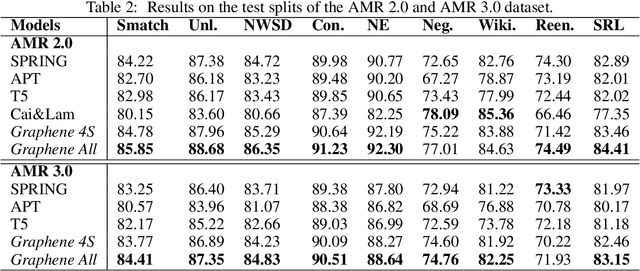
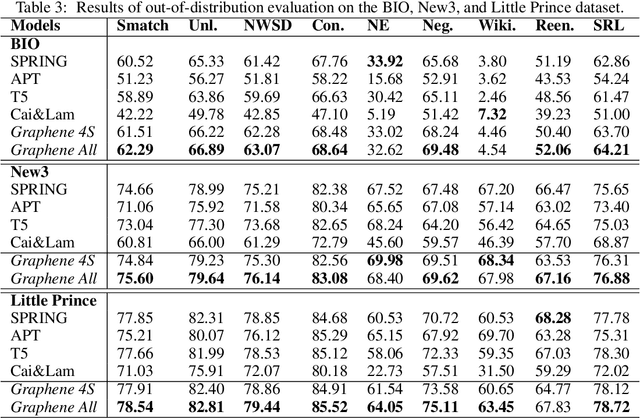
In many machine learning tasks, models are trained to predict structure data such as graphs. For example, in natural language processing, it is very common to parse texts into dependency trees or abstract meaning representation (AMR) graphs. On the other hand, ensemble methods combine predictions from multiple models to create a new one that is more robust and accurate than individual predictions. In the literature, there are many ensembling techniques proposed for classification or regression problems, however, ensemble graph prediction has not been studied thoroughly. In this work, we formalize this problem as mining the largest graph that is the most supported by a collection of graph predictions. As the problem is NP-Hard, we propose an efficient heuristic algorithm to approximate the optimal solution. To validate our approach, we carried out experiments in AMR parsing problems. The experimental results demonstrate that the proposed approach can combine the strength of state-of-the-art AMR parsers to create new predictions that are more accurate than any individual models in five standard benchmark datasets.
Federated Learning with Randomized Douglas-Rachford Splitting Methods
Mar 05, 2021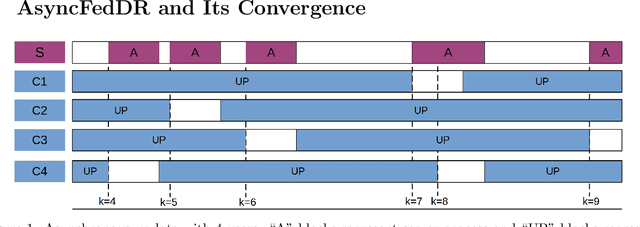
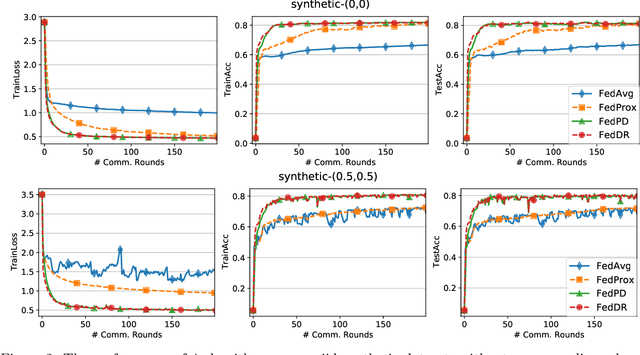
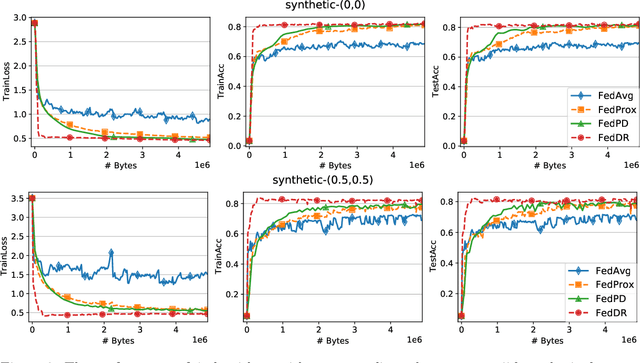
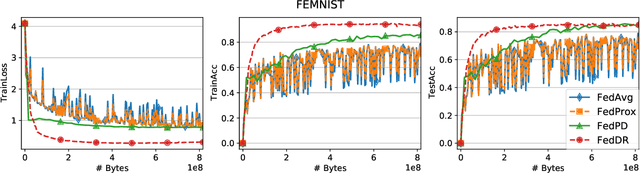
In this paper, we develop two new algorithms, called, \textbf{FedDR} and \textbf{asyncFedDR}, for solving a fundamental nonconvex optimization problem in federated learning. Our algorithms rely on a novel combination between a nonconvex Douglas-Rachford splitting method, randomized block-coordinate strategies, and asynchronous implementation. Unlike recent methods in the literature, e.g., FedSplit and FedPD, our algorithms update only a subset of users at each communication round, and possibly in an asynchronous mode, making them more practical. These new algorithms also achieve communication efficiency and more importantly can handle statistical and system heterogeneity, which are the two main challenges in federated learning. Our convergence analysis shows that the new algorithms match the communication complexity lower bound up to a constant factor under standard assumptions. Our numerical experiments illustrate the advantages of the proposed methods compared to existing ones using both synthetic and real datasets.
A Scalable MIP-based Method for Learning Optimal Multivariate Decision Trees
Nov 06, 2020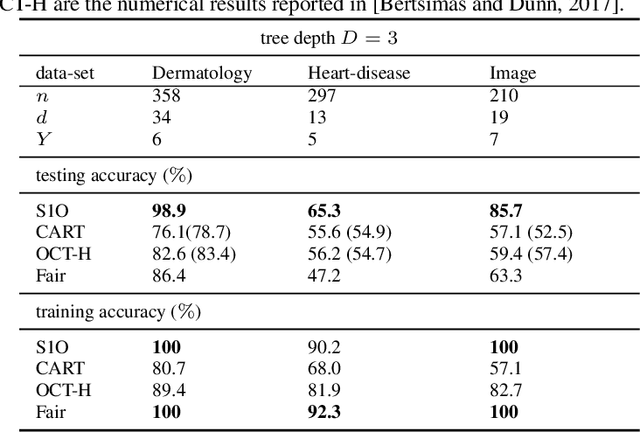
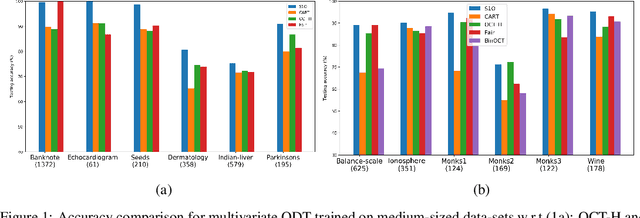
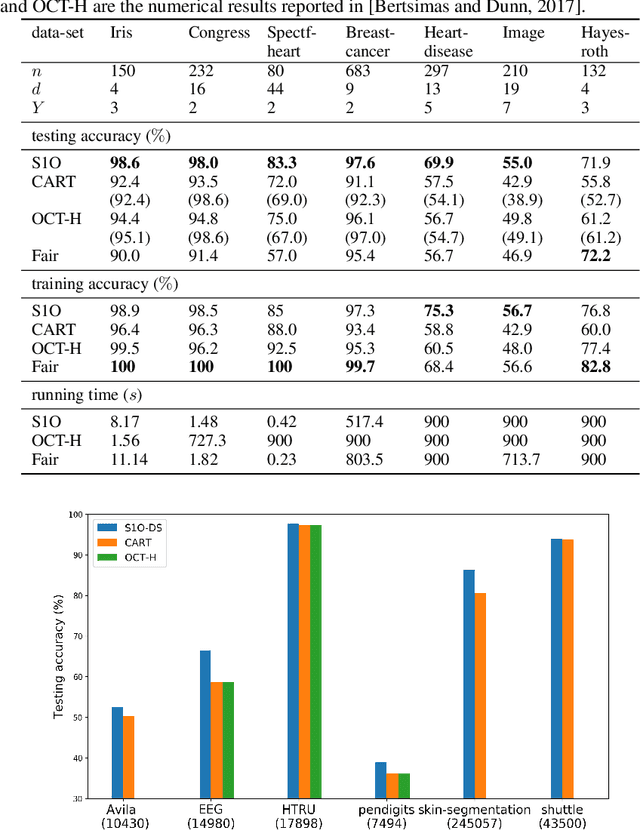
Several recent publications report advances in training optimal decision trees (ODT) using mixed-integer programs (MIP), due to algorithmic advances in integer programming and a growing interest in addressing the inherent suboptimality of heuristic approaches such as CART. In this paper, we propose a novel MIP formulation, based on a 1-norm support vector machine model, to train a multivariate ODT for classification problems. We provide cutting plane techniques that tighten the linear relaxation of the MIP formulation, in order to improve run times to reach optimality. Using 36 data-sets from the University of California Irvine Machine Learning Repository, we demonstrate that our formulation outperforms its counterparts in the literature by an average of about 10% in terms of mean out-of-sample testing accuracy across the data-sets. We provide a scalable framework to train multivariate ODT on large data-sets by introducing a novel linear programming (LP) based data selection method to choose a subset of the data for training. Our method is able to routinely handle large data-sets with more than 7,000 sample points and outperform heuristics methods and other MIP based techniques. We present results on data-sets containing up to 245,000 samples. Existing MIP-based methods do not scale well on training data-sets beyond 5,500 samples.
A Hybrid Stochastic Policy Gradient Algorithm for Reinforcement Learning
Mar 01, 2020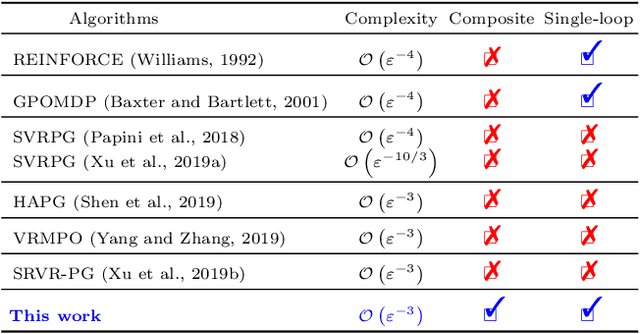
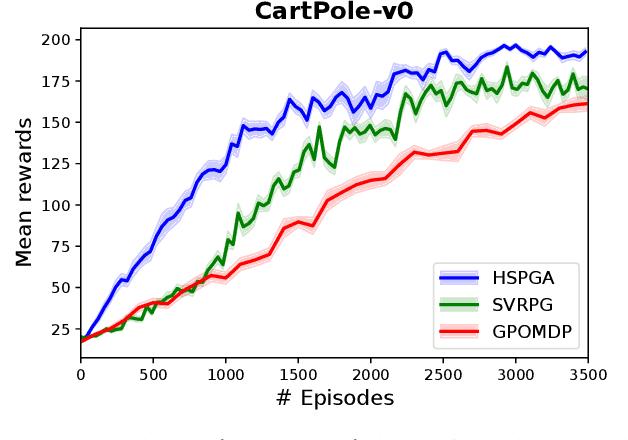
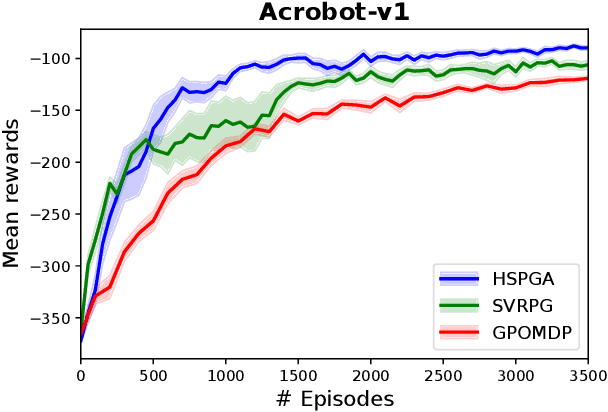
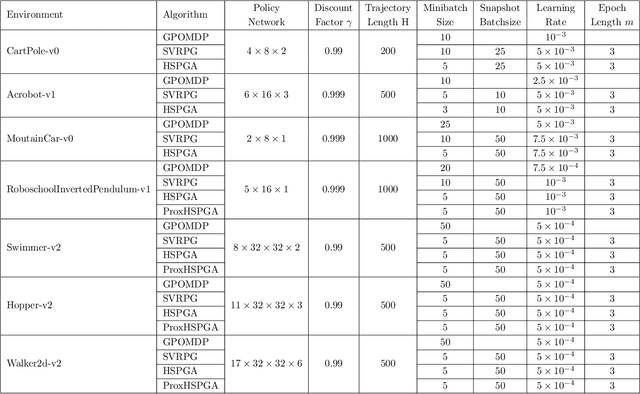
We propose a novel hybrid stochastic policy gradient estimator by combining an unbiased policy gradient estimator, the REINFORCE estimator, with another biased one, an adapted SARAH estimator for policy optimization. The hybrid policy gradient estimator is shown to be biased, but has variance reduced property. Using this estimator, we develop a new Proximal Hybrid Stochastic Policy Gradient Algorithm (ProxHSPGA) to solve a composite policy optimization problem that allows us to handle constraints or regularizers on the policy parameters. We first propose a single-looped algorithm then introduce a more practical restarting variant. We prove that both algorithms can achieve the best-known trajectory complexity $\mathcal{O}\left(\varepsilon^{-3}\right)$ to attain a first-order stationary point for the composite problem which is better than existing REINFORCE/GPOMDP $\mathcal{O}\left(\varepsilon^{-4}\right)$ and SVRPG $\mathcal{O}\left(\varepsilon^{-10/3}\right)$ in the non-composite setting. We evaluate the performance of our algorithm on several well-known examples in reinforcement learning. Numerical results show that our algorithm outperforms two existing methods on these examples. Moreover, the composite settings indeed have some advantages compared to the non-composite ones on certain problems.
A Unified Convergence Analysis for Shuffling-Type Gradient Methods
Feb 19, 2020
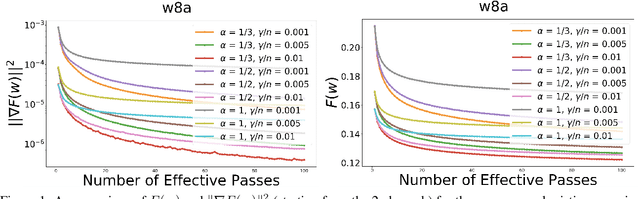
In this paper, we provide a unified convergence analysis for a class of shuffling-type gradient methods for solving a well-known finite-sum minimization problem commonly used in machine learning. This algorithm covers various variants such as randomized reshuffling, single shuffling, and cyclic/incremental gradient schemes. We consider two different settings: strongly convex and non-convex problems. Our main contribution consists of new non-asymptotic and asymptotic convergence rates for a general class of shuffling-type gradient methods to solve both non-convex and strongly convex problems. While our rate in the non-convex problem is new (i.e. not known yet under standard assumptions), the rate on the strongly convex case matches (up to a constant) the best-known results. However, unlike existing works in this direction, we only use standard assumptions such as smoothness and strong convexity. Finally, we empirically illustrate the effect of learning rates via a non-convex logistic regression and neural network examples.
A Hybrid Stochastic Optimization Framework for Stochastic Composite Nonconvex Optimization
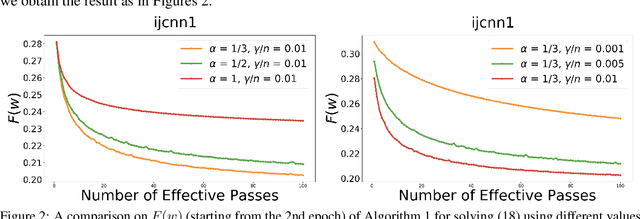
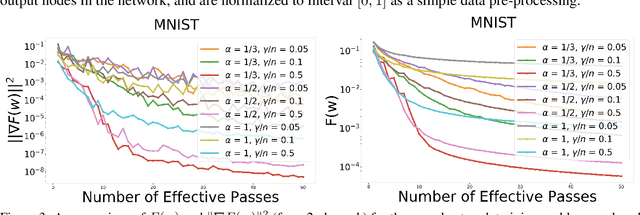
Jul 08, 2019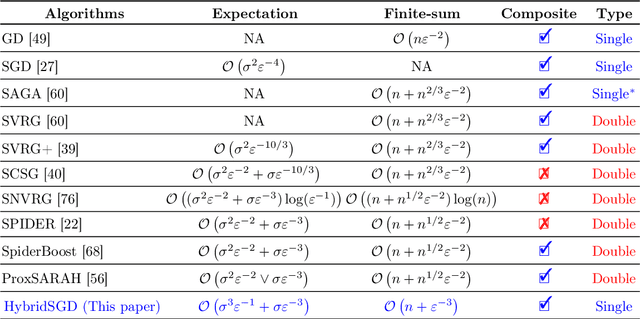
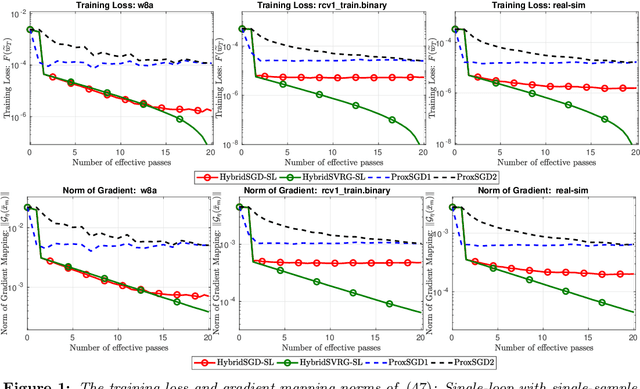
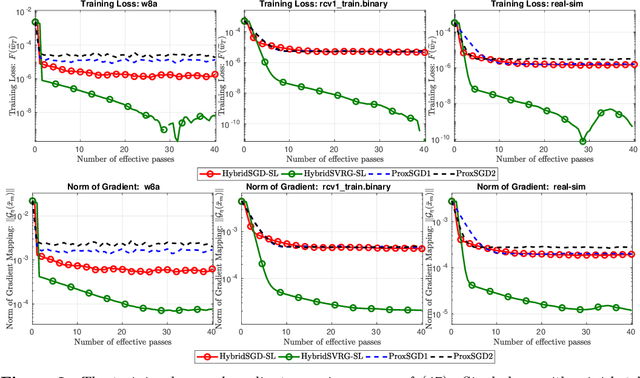
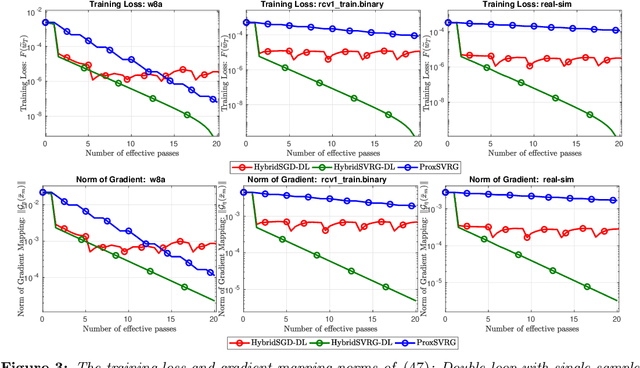
In this paper, we introduce a new approach to develop stochastic optimization algorithms for solving stochastic composite and possibly nonconvex optimization problems. The main idea is to combine two stochastic estimators to form a new hybrid one. We first introduce our hybrid estimator and then investigate its fundamental properties to form a foundation theory for algorithmic development. Next, we apply our theory to develop several variants of stochastic gradient methods to solve both expectation and finite-sum composite optimization problems. Our first algorithm can be viewed as a variant of proximal stochastic gradient methods with a single-loop, but can achieve $\mathcal{O}(\sigma^3\varepsilon^{-1} + \sigma\varepsilon^{-3})$ complexity bound that is significantly better than the $\mathcal{O}(\sigma^2\varepsilon^{-4})$-complexity in state-of-the-art stochastic gradient methods, where $\sigma$ is the variance and $\varepsilon$ is a desired accuracy. Then, we consider two different variants of our method: adaptive step-size and double-loop schemes that have the same theoretical guarantees as in our first algorithm. We also study two mini-batch variants and develop two hybrid SARAH-SVRG algorithms to solve the finite-sum problems. In all cases, we achieve the best-known complexity bounds under standard assumptions. We test our methods on several numerical examples with real datasets and compare them with state-of-the-arts. Our numerical experiments show that the new methods are comparable and, in many cases, outperform their competitors.
Hybrid Stochastic Gradient Descent Algorithms for Stochastic Nonconvex Optimization
May 15, 2019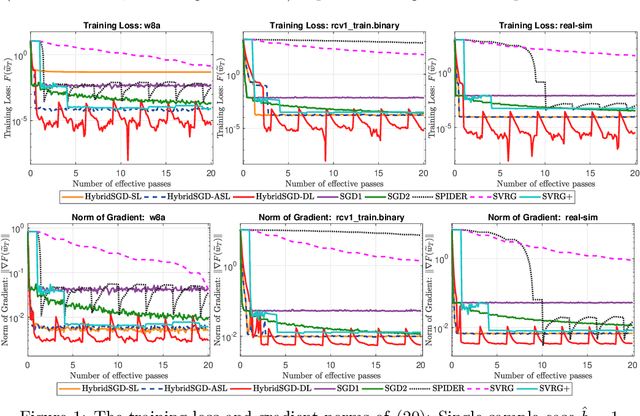


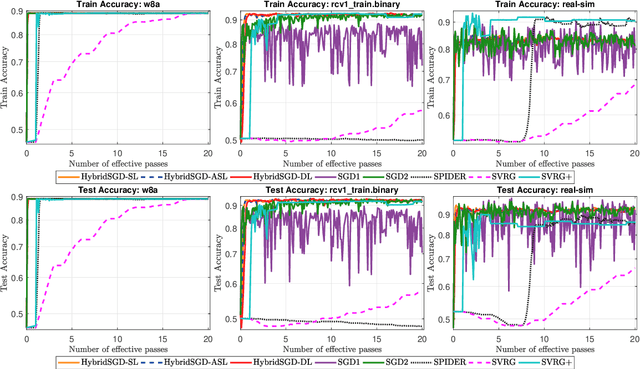
We introduce a hybrid stochastic estimator to design stochastic gradient algorithms for solving stochastic optimization problems. Such a hybrid estimator is a convex combination of two existing biased and unbiased estimators and leads to some useful property on its variance. We limit our consideration to a hybrid SARAH-SGD for nonconvex expectation problems. However, our idea can be extended to handle a broader class of estimators in both convex and nonconvex settings. We propose a new single-loop stochastic gradient descent algorithm that can achieve $O(\max\{\sigma^3\varepsilon^{-1},\sigma\varepsilon^{-3}\})$-complexity bound to obtain an $\varepsilon$-stationary point under smoothness and $\sigma^2$-bounded variance assumptions. This complexity is better than $O(\sigma^2\varepsilon^{-4})$ often obtained in state-of-the-art SGDs when $\sigma < O(\varepsilon^{-3})$. We also consider different extensions of our method, including constant and adaptive step-size with single-loop, double-loop, and mini-batch variants. We compare our algorithms with existing methods on several datasets using two nonconvex models.
ProxSARAH: An Efficient Algorithmic Framework for Stochastic Composite Nonconvex Optimization
Mar 29, 2019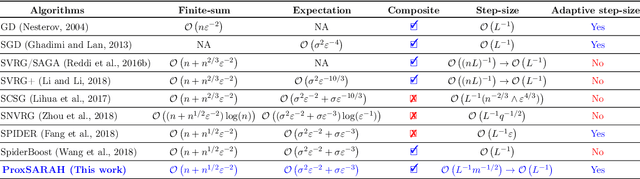

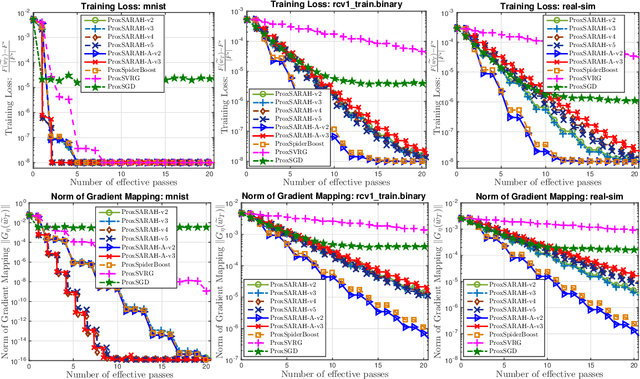

We propose a new stochastic first-order algorithmic framework to solve stochastic composite nonconvex optimization problems that covers both finite-sum and expectation settings. Our algorithms rely on the SARAH estimator introduced in (Nguyen et al, 2017) and consist of two steps: a proximal gradient and an averaging step making them different from existing nonconvex proximal-type algorithms. The algorithms only require an average smoothness assumption of the nonconvex objective term and additional bounded variance assumption if applied to expectation problems. They work with both constant and adaptive step-sizes, while allowing single sample and mini-batches. In all these cases, we prove that our algorithms can achieve the best-known complexity bounds. One key step of our methods is new constant and adaptive step-sizes that help to achieve desired complexity bounds while improving practical performance. Our constant step-size is much larger than existing methods including proximal SVRG schemes in the single sample case. We also specify the algorithm to the non-composite case that covers existing state-of-the-arts in terms of complexity bounds. Our update also allows one to trade-off between step-sizes and mini-batch sizes to improve performance. We test the proposed algorithms on two composite nonconvex problems and neural networks using several well-known datasets.