 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
A Scalable MIP-based Method for Learning Optimal Multivariate Decision Trees
Nov 06, 2020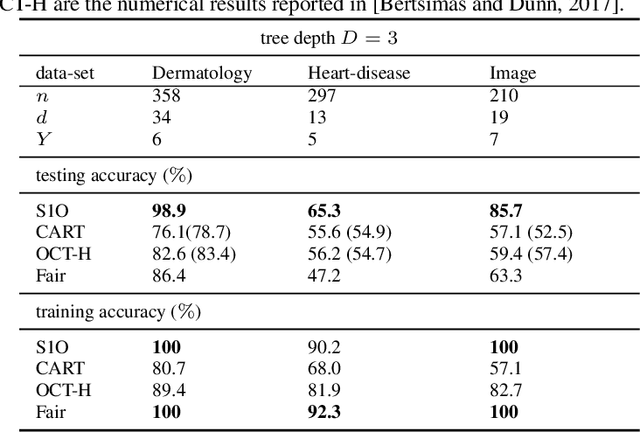
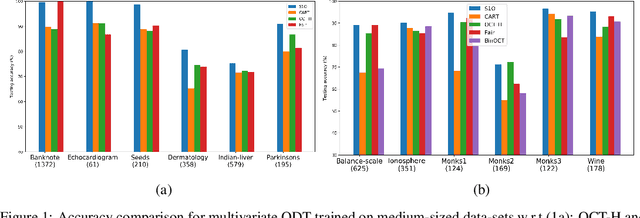
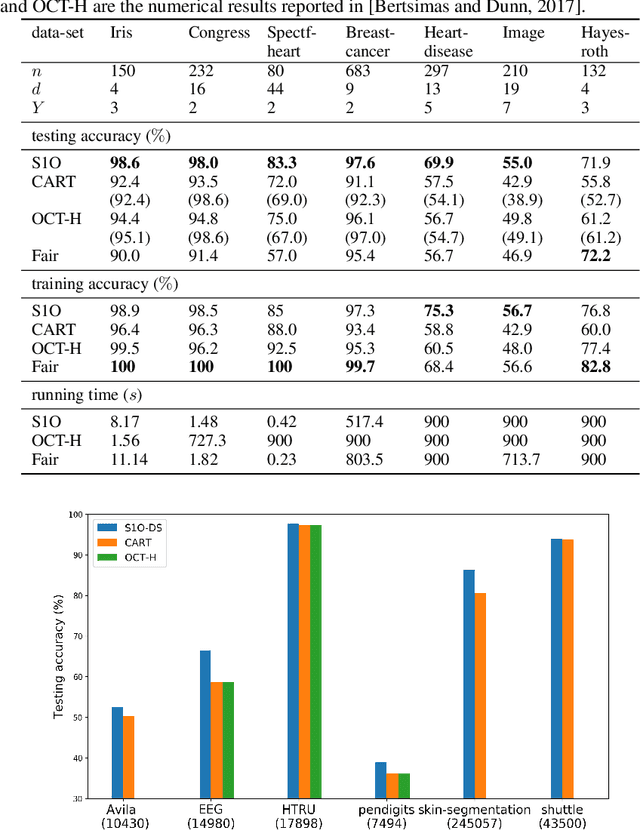
Several recent publications report advances in training optimal decision trees (ODT) using mixed-integer programs (MIP), due to algorithmic advances in integer programming and a growing interest in addressing the inherent suboptimality of heuristic approaches such as CART. In this paper, we propose a novel MIP formulation, based on a 1-norm support vector machine model, to train a multivariate ODT for classification problems. We provide cutting plane techniques that tighten the linear relaxation of the MIP formulation, in order to improve run times to reach optimality. Using 36 data-sets from the University of California Irvine Machine Learning Repository, we demonstrate that our formulation outperforms its counterparts in the literature by an average of about 10% in terms of mean out-of-sample testing accuracy across the data-sets. We provide a scalable framework to train multivariate ODT on large data-sets by introducing a novel linear programming (LP) based data selection method to choose a subset of the data for training. Our method is able to routinely handle large data-sets with more than 7,000 sample points and outperform heuristics methods and other MIP based techniques. We present results on data-sets containing up to 245,000 samples. Existing MIP-based methods do not scale well on training data-sets beyond 5,500 samples.