 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Silent Failures in Multi-Agentic AI Trajectories
Nov 06, 2025Multi-Agentic AI systems, powered by large language models (LLMs), are inherently non-deterministic and prone to silent failures such as drift, cycles, and missing details in outputs, which are difficult to detect. We introduce the task of anomaly detection in agentic trajectories to identify these failures and present a dataset curation pipeline that captures user behavior, agent non-determinism, and LLM variation. Using this pipeline, we curate and label two benchmark datasets comprising \textbf{4,275 and 894} trajectories from Multi-Agentic AI systems. Benchmarking anomaly detection methods on these datasets, we show that supervised (XGBoost) and semi-supervised (SVDD) approaches perform comparably, achieving accuracies up to 98% and 96%, respectively. This work provides the first systematic study of anomaly detection in Multi-Agentic AI systems, offering datasets, benchmarks, and insights to guide future research.
ITBench: Evaluating AI Agents across Diverse Real-World IT Automation Tasks
Feb 07, 2025



Realizing the vision of using AI agents to automate critical IT tasks depends on the ability to measure and understand effectiveness of proposed solutions. We introduce ITBench, a framework that offers a systematic methodology for benchmarking AI agents to address real-world IT automation tasks. Our initial release targets three key areas: Site Reliability Engineering (SRE), Compliance and Security Operations (CISO), and Financial Operations (FinOps). The design enables AI researchers to understand the challenges and opportunities of AI agents for IT automation with push-button workflows and interpretable metrics. ITBench includes an initial set of 94 real-world scenarios, which can be easily extended by community contributions. Our results show that agents powered by state-of-the-art models resolve only 13.8% of SRE scenarios, 25.2% of CISO scenarios, and 0% of FinOps scenarios. We expect ITBench to be a key enabler of AI-driven IT automation that is correct, safe, and fast.
Robust Planning with Compound LLM Architectures: An LLM-Modulo Approach
Nov 20, 2024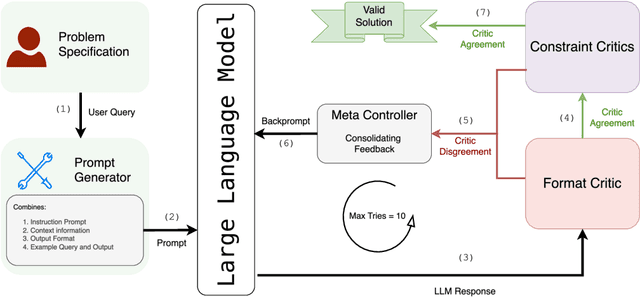


Previous work has attempted to boost Large Language Model (LLM) performance on planning and scheduling tasks through a variety of prompt engineering techniques. While these methods can work within the distributions tested, they are neither robust nor predictable. This limitation can be addressed through compound LLM architectures where LLMs work in conjunction with other components to ensure reliability. In this paper, we present a technical evaluation of a compound LLM architecture--the LLM-Modulo framework. In this framework, an LLM is paired with a complete set of sound verifiers that validate its output, re-prompting it if it fails. This approach ensures that the system can never output any fallacious output, and therefore that every output generated is guaranteed correct--something previous techniques have not been able to claim. Our results, evaluated across four scheduling domains, demonstrate significant performance gains with the LLM-Modulo framework using various models. Additionally, we explore modifications to the base configuration of the framework and assess their impact on overall system performance.
Robust Planning with LLM-Modulo Framework: Case Study in Travel Planning
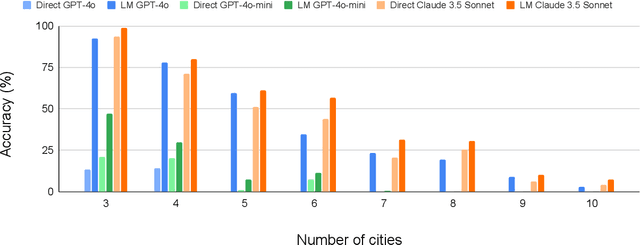
May 31, 2024As the applicability of Large Language Models (LLMs) extends beyond traditional text processing tasks, there is a burgeoning interest in their potential to excel in planning and reasoning assignments, realms traditionally reserved for System 2 cognitive competencies. Despite their perceived versatility, the research community is still unraveling effective strategies to harness these models in such complex domains. The recent discourse introduced by the paper on LLM Modulo marks a significant stride, proposing a conceptual framework that enhances the integration of LLMs into diverse planning and reasoning activities. This workshop paper delves into the practical application of this framework within the domain of travel planning, presenting a specific instance of its implementation. We are using the Travel Planning benchmark by the OSU NLP group, a benchmark for evaluating the performance of LLMs in producing valid itineraries based on user queries presented in natural language. While popular methods of enhancing the reasoning abilities of LLMs such as Chain of Thought, ReAct, and Reflexion achieve a meager 0%, 0.6%, and 0% with GPT3.5-Turbo respectively, our operationalization of the LLM-Modulo framework for TravelPlanning domain provides a remarkable improvement, enhancing baseline performances by 4.6x for GPT4-Turbo and even more for older models like GPT3.5-Turbo from 0% to 5%. Furthermore, we highlight the other useful roles of LLMs in the planning pipeline, as suggested in LLM-Modulo, which can be reliably operationalized such as extraction of useful critics and reformulator for critics.
On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models
May 22, 2024



The reasoning abilities of Large Language Models (LLMs) remain a topic of debate. Some methods such as ReAct-based prompting, have gained popularity for claiming to enhance sequential decision-making abilities of agentic LLMs. However, it is unclear what is the source of improvement in LLM reasoning with ReAct based prompting. In this paper we examine these claims of ReAct based prompting in improving agentic LLMs for sequential decision-making. By introducing systematic variations to the input prompt we perform a sensitivity analysis along the claims of ReAct and find that the performance is minimally influenced by the "interleaving reasoning trace with action execution" or the content of the generated reasoning traces in ReAct, contrary to original claims and common usage. Instead, the performance of LLMs is driven by the similarity between input example tasks and queries, implicitly forcing the prompt designer to provide instance-specific examples which significantly increases the cognitive burden on the human. Our investigation shows that the perceived reasoning abilities of LLMs stem from the exemplar-query similarity and approximate retrieval rather than any inherent reasoning abilities.
Hindsight PRIORs for Reward Learning from Human Preferences
Apr 12, 2024Preference based Reinforcement Learning (PbRL) removes the need to hand specify a reward function by learning a reward from preference feedback over policy behaviors. Current approaches to PbRL do not address the credit assignment problem inherent in determining which parts of a behavior most contributed to a preference, which result in data intensive approaches and subpar reward functions. We address such limitations by introducing a credit assignment strategy (Hindsight PRIOR) that uses a world model to approximate state importance within a trajectory and then guides rewards to be proportional to state importance through an auxiliary predicted return redistribution objective. Incorporating state importance into reward learning improves the speed of policy learning, overall policy performance, and reward recovery on both locomotion and manipulation tasks. For example, Hindsight PRIOR recovers on average significantly (p<0.05) more reward on MetaWorld (20%) and DMC (15%). The performance gains and our ablations demonstrate the benefits even a simple credit assignment strategy can have on reward learning and that state importance in forward dynamics prediction is a strong proxy for a state's contribution to a preference decision. Code repository can be found at https://github.com/apple/ml-rlhf-hindsight-prior.
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Feb 06, 2024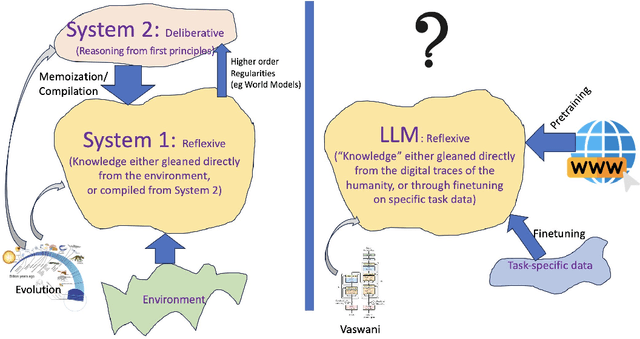
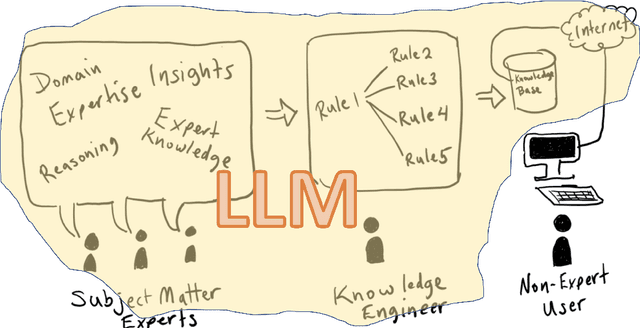
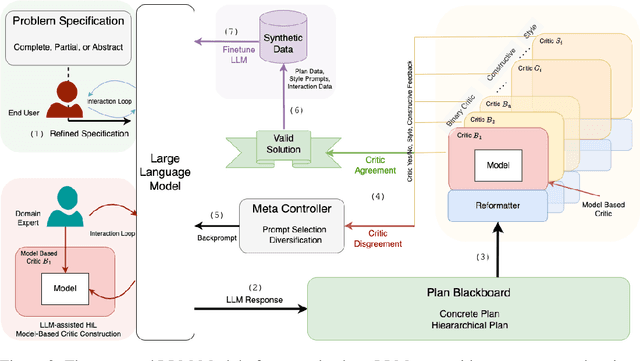
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {\bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
Theory of Mind abilities of Large Language Models in Human-Robot Interaction : An Illusion?
Jan 17, 2024Large Language Models have shown exceptional generative abilities in various natural language and generation tasks. However, possible anthropomorphization and leniency towards failure cases have propelled discussions on emergent abilities of Large Language Models especially on Theory of Mind (ToM) abilities in Large Language Models. While several false-belief tests exists to verify the ability to infer and maintain mental models of another entity, we study a special application of ToM abilities that has higher stakes and possibly irreversible consequences : Human Robot Interaction. In this work, we explore the task of Perceived Behavior Recognition, where a robot employs a Large Language Model (LLM) to assess the robot's generated behavior in a manner similar to human observer. We focus on four behavior types, namely - explicable, legible, predictable, and obfuscatory behavior which have been extensively used to synthesize interpretable robot behaviors. The LLMs goal is, therefore to be a human proxy to the agent, and to answer how a certain agent behavior would be perceived by the human in the loop, for example "Given a robot's behavior X, would the human observer find it explicable?". We conduct a human subject study to verify that the users are able to correctly answer such a question in the curated situations (robot setting and plan) across five domains. A first analysis of the belief test yields extremely positive results inflating ones expectations of LLMs possessing ToM abilities. We then propose and perform a suite of perturbation tests which breaks this illusion, i.e. Inconsistent Belief, Uninformative Context and Conviction Test. We conclude that, the high score of LLMs on vanilla prompts showcases its potential use in HRI settings, however to possess ToM demands invariance to trivial or irrelevant perturbations in the context which LLMs lack.
Benchmarking Multi-Agent Preference-based Reinforcement Learning for Human-AI Teaming
Dec 21, 2023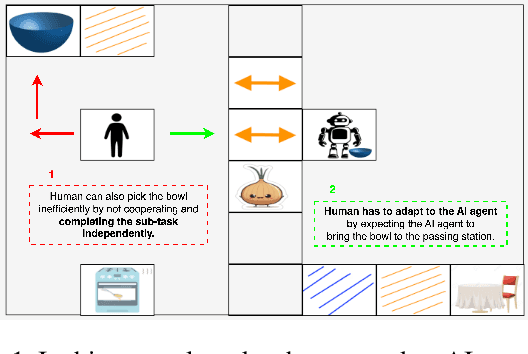



Preference-based Reinforcement Learning (PbRL) is an active area of research, and has made significant strides in single-agent actor and in observer human-in-the-loop scenarios. However, its application within the co-operative multi-agent RL frameworks, where humans actively participate and express preferences for agent behavior, remains largely uncharted. We consider a two-agent (Human-AI) cooperative setup where both the agents are rewarded according to human's reward function for the team. However, the agent does not have access to it, and instead, utilizes preference-based queries to elicit its objectives and human's preferences for the robot in the human-robot team. We introduce the notion of Human-Flexibility, i.e. whether the human partner is amenable to multiple team strategies, with a special case being Specified Orchestration where the human has a single team policy in mind (most constrained case). We propose a suite of domains to study PbRL for Human-AI cooperative setup which explicitly require forced cooperation. Adapting state-of-the-art single-agent PbRL algorithms to our two-agent setting, we conduct a comprehensive benchmarking study across our domain suite. Our findings highlight the challenges associated with high degree of Human-Flexibility and the limited access to the human's envisioned policy in PbRL for Human-AI cooperation. Notably, we observe that PbRL algorithms exhibit effective performance exclusively in the case of Specified Orchestration which can be seen as an upper bound PbRL performance for future research.
Methods and Mechanisms for Interactive Novelty Handling in Adversarial Environments
Mar 06, 2023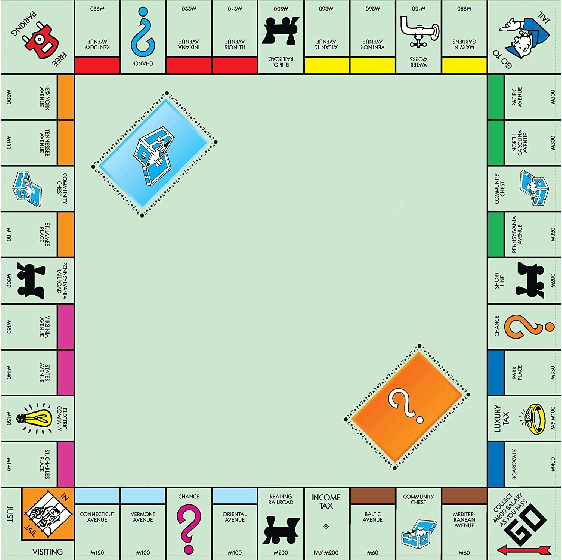
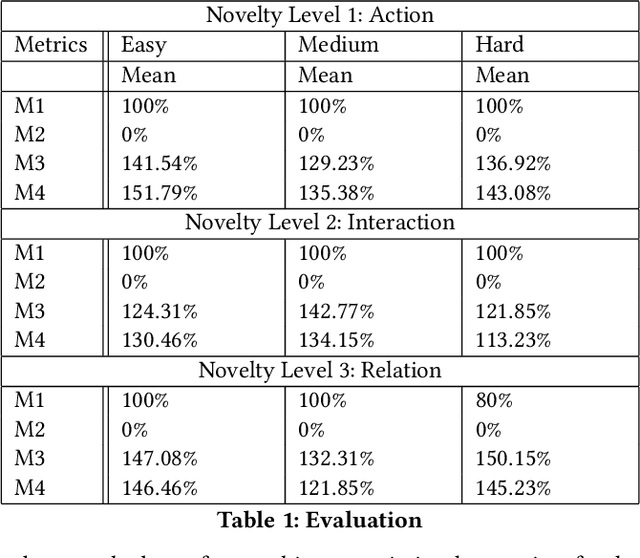
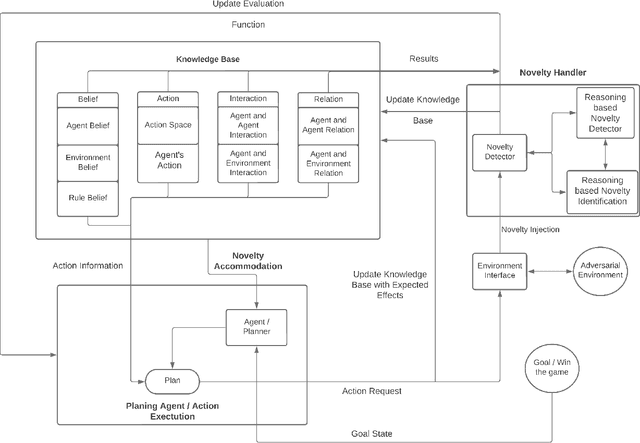
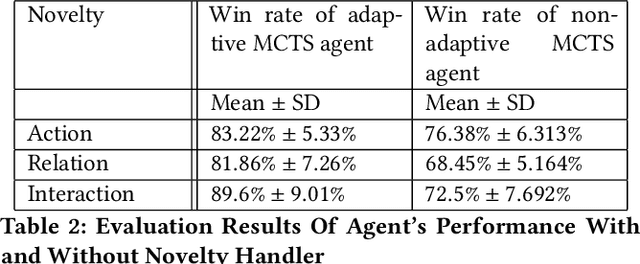
Learning to detect, characterize and accommodate novelties is a challenge that agents operating in open-world domains need to address to be able to guarantee satisfactory task performance. Certain novelties (e.g., changes in environment dynamics) can interfere with the performance or prevent agents from accomplishing task goals altogether. In this paper, we introduce general methods and architectural mechanisms for detecting and characterizing different types of novelties, and for building an appropriate adaptive model to accommodate them utilizing logical representations and reasoning methods. We demonstrate the effectiveness of the proposed methods in evaluations performed by a third party in the adversarial multi-agent board game Monopoly. The results show high novelty detection and accommodation rates across a variety of novelty types, including changes to the rules of the game, as well as changes to the agent's action capabilities.