 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Feb 06, 2024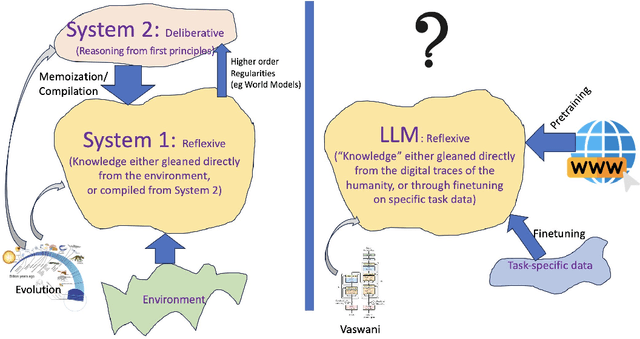
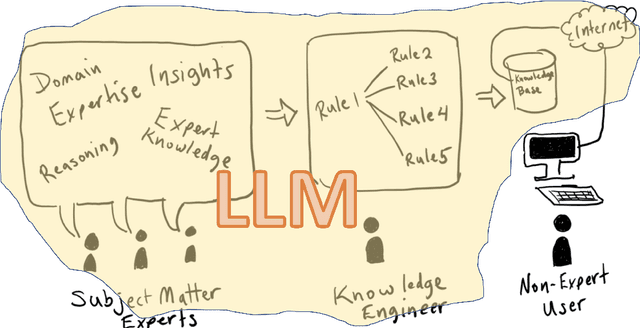
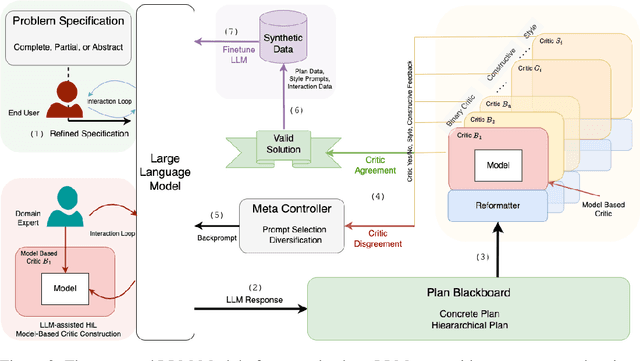
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {\bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
Benchmarking Multi-Agent Preference-based Reinforcement Learning for Human-AI Teaming
Dec 21, 2023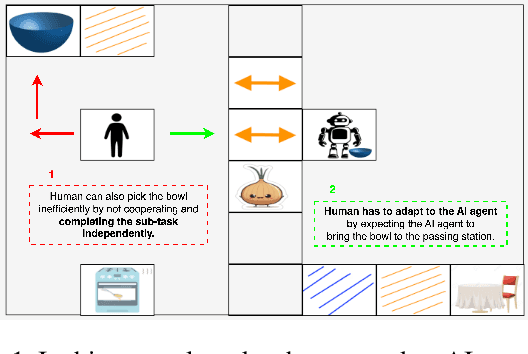



Preference-based Reinforcement Learning (PbRL) is an active area of research, and has made significant strides in single-agent actor and in observer human-in-the-loop scenarios. However, its application within the co-operative multi-agent RL frameworks, where humans actively participate and express preferences for agent behavior, remains largely uncharted. We consider a two-agent (Human-AI) cooperative setup where both the agents are rewarded according to human's reward function for the team. However, the agent does not have access to it, and instead, utilizes preference-based queries to elicit its objectives and human's preferences for the robot in the human-robot team. We introduce the notion of Human-Flexibility, i.e. whether the human partner is amenable to multiple team strategies, with a special case being Specified Orchestration where the human has a single team policy in mind (most constrained case). We propose a suite of domains to study PbRL for Human-AI cooperative setup which explicitly require forced cooperation. Adapting state-of-the-art single-agent PbRL algorithms to our two-agent setting, we conduct a comprehensive benchmarking study across our domain suite. Our findings highlight the challenges associated with high degree of Human-Flexibility and the limited access to the human's envisioned policy in PbRL for Human-AI cooperation. Notably, we observe that PbRL algorithms exhibit effective performance exclusively in the case of Specified Orchestration which can be seen as an upper bound PbRL performance for future research.