 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Multi-Agent Preference-based Reinforcement Learning for Human-AI Teaming
Paper and Code
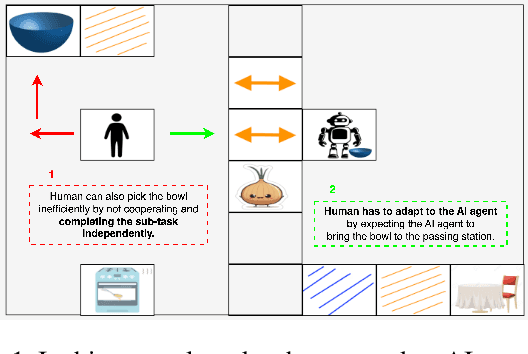



Preference-based Reinforcement Learning (PbRL) is an active area of research, and has made significant strides in single-agent actor and in observer human-in-the-loop scenarios. However, its application within the co-operative multi-agent RL frameworks, where humans actively participate and express preferences for agent behavior, remains largely uncharted. We consider a two-agent (Human-AI) cooperative setup where both the agents are rewarded according to human's reward function for the team. However, the agent does not have access to it, and instead, utilizes preference-based queries to elicit its objectives and human's preferences for the robot in the human-robot team. We introduce the notion of Human-Flexibility, i.e. whether the human partner is amenable to multiple team strategies, with a special case being Specified Orchestration where the human has a single team policy in mind (most constrained case). We propose a suite of domains to study PbRL for Human-AI cooperative setup which explicitly require forced cooperation. Adapting state-of-the-art single-agent PbRL algorithms to our two-agent setting, we conduct a comprehensive benchmarking study across our domain suite. Our findings highlight the challenges associated with high degree of Human-Flexibility and the limited access to the human's envisioned policy in PbRL for Human-AI cooperation. Notably, we observe that PbRL algorithms exhibit effective performance exclusively in the case of Specified Orchestration which can be seen as an upper bound PbRL performance for future research.