 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformative Thinking? The Brittle Correlation Between CoT Length and Problem Complexity
Sep 09, 2025Intermediate token generation (ITG), where a model produces output before the solution, has been proposed as a method to improve the performance of language models on reasoning tasks. While these reasoning traces or Chain of Thoughts (CoTs) are correlated with performance gains, the mechanisms underlying them remain unclear. A prevailing assumption in the community has been to anthropomorphize these tokens as "thinking", treating longer traces as evidence of higher problem-adaptive computation. In this work, we critically examine whether intermediate token sequence length reflects or correlates with problem difficulty. To do so, we train transformer models from scratch on derivational traces of the A* search algorithm, where the number of operations required to solve a maze problem provides a precise and verifiable measure of problem complexity. We first evaluate the models on trivial free-space problems, finding that even for the simplest tasks, they often produce excessively long reasoning traces and sometimes fail to generate a solution. We then systematically evaluate the model on out-of-distribution problems and find that the intermediate token length and ground truth A* trace length only loosely correlate. We notice that the few cases where correlation appears are those where the problems are closer to the training distribution, suggesting that the effect arises from approximate recall rather than genuine problem-adaptive computation. This suggests that the inherent computational complexity of the problem instance is not a significant factor, but rather its distributional distance from the training data. These results challenge the assumption that intermediate trace generation is adaptive to problem difficulty and caution against interpreting longer sequences in systems like R1 as automatically indicative of "thinking effort".
Mind The Gap: Deep Learning Doesn't Learn Deeply
May 24, 2025This paper aims to understand how neural networks learn algorithmic reasoning by addressing two questions: How faithful are learned algorithms when they are effective, and why do neural networks fail to learn effective algorithms otherwise? To answer these questions, we use neural compilation, a technique that directly encodes a source algorithm into neural network parameters, enabling the network to compute the algorithm exactly. This enables comparison between compiled and conventionally learned parameters, intermediate vectors, and behaviors. This investigation is crucial for developing neural networks that robustly learn complexalgorithms from data. Our analysis focuses on graph neural networks (GNNs), which are naturally aligned with algorithmic reasoning tasks, specifically our choices of BFS, DFS, and Bellman-Ford, which cover the spectrum of effective, faithful, and ineffective learned algorithms. Commonly, learning algorithmic reasoning is framed as induction over synthetic data, where a parameterized model is trained on inputs, traces, and outputs produced by an underlying ground truth algorithm. In contrast, we introduce a neural compilation method for GNNs, which sets network parameters analytically, bypassing training. Focusing on GNNs leverages their alignment with algorithmic reasoning, extensive algorithmic induction literature, and the novel application of neural compilation to GNNs. Overall, this paper aims to characterize expressability-trainability gaps - a fundamental shortcoming in learning algorithmic reasoning. We hypothesize that inductive learning is most effective for parallel algorithms contained within the computational class \texttt{NC}.
Interpretable Traces, Unexpected Outcomes: Investigating the Disconnect in Trace-Based Knowledge Distillation
May 20, 2025Question Answering (QA) poses a challenging and critical problem, particularly in today's age of interactive dialogue systems such as ChatGPT, Perplexity, Microsoft Copilot, etc. where users demand both accuracy and transparency in the model's outputs. Since smaller language models (SLMs) are computationally more efficient but often under-perform compared to larger models, Knowledge Distillation (KD) methods allow for finetuning these smaller models to improve their final performance. Lately, the intermediate tokens or the so called `reasoning' traces produced by Chain-of-Thought (CoT) or by reasoning models such as DeepSeek R1 are used as a training signal for KD. However, these reasoning traces are often verbose and difficult to interpret or evaluate. In this work, we aim to address the challenge of evaluating the faithfulness of these reasoning traces and their correlation with the final performance. To this end, we employ a KD method leveraging rule-based problem decomposition. This approach allows us to break down complex queries into structured sub-problems, generating interpretable traces whose correctness can be readily evaluated, even at inference time. Specifically, we demonstrate this approach on Open Book QA, decomposing the problem into a Classification step and an Information Retrieval step, thereby simplifying trace evaluation. Our SFT experiments with correct and incorrect traces on the CoTemp QA, Microsoft Machine Reading Comprehension QA, and Facebook bAbI QA datasets reveal the striking finding that correct traces do not necessarily imply that the model outputs the correct final solution. Similarly, we find a low correlation between correct final solutions and intermediate trace correctness. These results challenge the implicit assumption behind utilizing reasoning traces for improving SLMs' final performance via KD.
RL in Name Only? Analyzing the Structural Assumptions in RL post-training for LLMs
May 19, 2025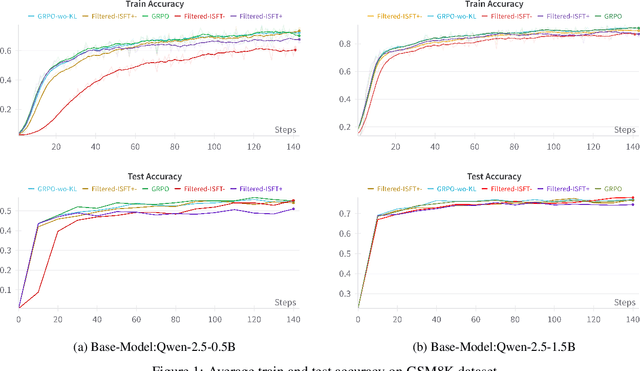
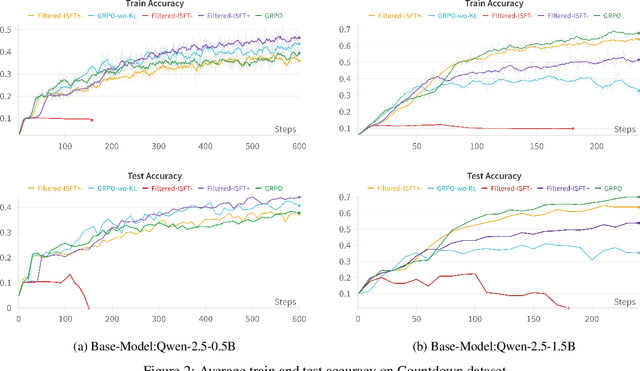

Reinforcement learning-based post-training of large language models (LLMs) has recently gained attention, particularly following the release of DeepSeek R1, which applied GRPO for fine-tuning. Amid the growing hype around improved reasoning abilities attributed to RL post-training, we critically examine the formulation and assumptions underlying these methods. We start by highlighting the popular structural assumptions made in modeling LLM training as a Markov Decision Process (MDP), and show how they lead to a degenerate MDP that doesn't quite need the RL/GRPO apparatus. The two critical structural assumptions include (1) making the MDP states be just a concatenation of the actions-with states becoming the context window and the actions becoming the tokens in LLMs and (2) splitting the reward of a state-action trajectory uniformly across the trajectory. Through a comprehensive analysis, we demonstrate that these simplifying assumptions make the approach effectively equivalent to an outcome-driven supervised learning. Our experiments on benchmarks including GSM8K and Countdown using Qwen-2.5 base models show that iterative supervised fine-tuning, incorporating both positive and negative samples, achieves performance comparable to GRPO-based training. We will also argue that the structural assumptions indirectly incentivize the RL to generate longer sequences of intermediate tokens-which in turn feeds into the narrative of "RL generating longer thinking traces." While RL may well be a very useful technique for improving the reasoning abilities of LLMs, our analysis shows that the simplistic structural assumptions made in modeling the underlying MDP render the popular LLM RL frameworks and their interpretations questionable.
Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens
May 19, 2025
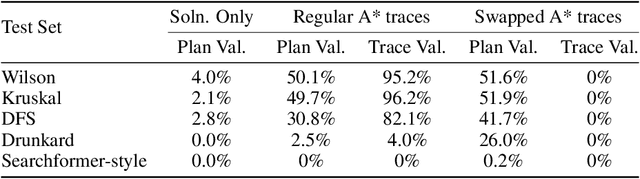
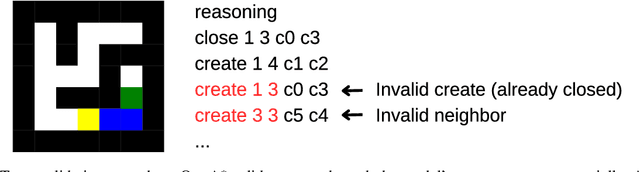
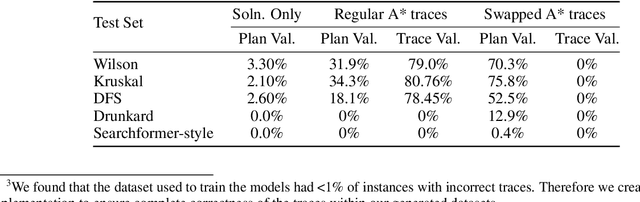
Recent impressive results from large reasoning models have been interpreted as a triumph of Chain of Thought (CoT), and especially of the process of training on CoTs sampled from base LLMs in order to help find new reasoning patterns. In this paper, we critically examine that interpretation by investigating how the semantics of intermediate tokens-often anthropomorphized as "thoughts" or reasoning traces and which are claimed to display behaviors like backtracking, self-verification etc.-actually influence model performance. We train transformer models on formally verifiable reasoning traces and solutions, constraining both intermediate steps and final outputs to align with those of a formal solver (in our case, A* search). By constructing a formal interpreter of the semantics of our problems and intended algorithm, we systematically evaluate not only solution accuracy but also the correctness of intermediate traces, thus allowing us to evaluate whether the latter causally influences the former. We notice that, despite significant improvements on the solution-only baseline, models trained on entirely correct traces still produce invalid reasoning traces when arriving at correct solutions. To further show that trace accuracy is only loosely connected to solution accuracy, we then train models on noisy, corrupted traces which have no relation to the specific problem each is paired with, and find that not only does performance remain largely consistent with models trained on correct data, but in some cases can improve upon it and generalize more robustly on out-of-distribution tasks. These results challenge the assumption that intermediate tokens or "Chains of Thought" induce predictable reasoning behaviors and caution against anthropomorphizing such outputs or over-interpreting them (despite their mostly correct forms) as evidence of human-like or algorithmic behaviors in language models.
(How) Do reasoning models reason?
Apr 14, 2025We will provide a broad unifying perspective on the recent breed of Large Reasoning Models (LRMs) such as OpenAI o1 and DeepSeek R1, including their promise, sources of power, misconceptions and limitations.
Who is Helping Whom? Analyzing Inter-dependencies to Evaluate Cooperation in Human-AI Teaming
Feb 10, 2025



The long-standing research challenges of Human-AI Teaming(HAT) and Zero-shot Cooperation(ZSC) have been tackled by applying multi-agent reinforcement learning(MARL) to train an agent by optimizing the environment reward function and evaluating their performance through task performance metrics such as task reward. However, such evaluation focuses only on task completion, while being agnostic to `how' the two agents work with each other. Specifically, we are interested in understanding the cooperation arising within the team when trained agents are paired with humans. To formally address this problem, we propose the concept of interdependence to measure how much agents rely on each other's actions to achieve the shared goal, as a key metric for evaluating cooperation in human-agent teams. Towards this, we ground this concept through a symbolic formalism and define evaluation metrics that allow us to assess the degree of reliance between the agents' actions. We pair state-of-the-art agents trained through MARL for HAT, with learned human models for the the popular Overcooked domain, and evaluate the team performance for these human-agent teams. Our results demonstrate that trained agents are not able to induce cooperative behavior, reporting very low levels of interdependence across all the teams. We also report that teaming performance of a team is not necessarily correlated with the task reward.
Robust Planning with Compound LLM Architectures: An LLM-Modulo Approach
Nov 20, 2024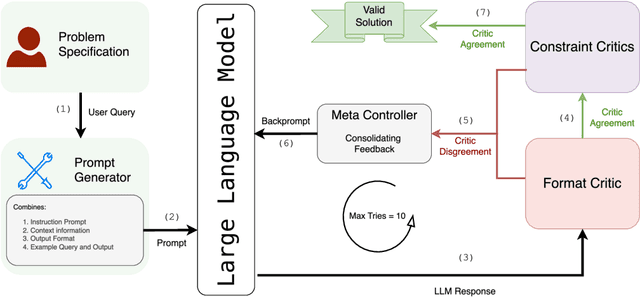


Previous work has attempted to boost Large Language Model (LLM) performance on planning and scheduling tasks through a variety of prompt engineering techniques. While these methods can work within the distributions tested, they are neither robust nor predictable. This limitation can be addressed through compound LLM architectures where LLMs work in conjunction with other components to ensure reliability. In this paper, we present a technical evaluation of a compound LLM architecture--the LLM-Modulo framework. In this framework, an LLM is paired with a complete set of sound verifiers that validate its output, re-prompting it if it fails. This approach ensures that the system can never output any fallacious output, and therefore that every output generated is guaranteed correct--something previous techniques have not been able to claim. Our results, evaluated across four scheduling domains, demonstrate significant performance gains with the LLM-Modulo framework using various models. Additionally, we explore modifications to the base configuration of the framework and assess their impact on overall system performance.
Planning in Strawberry Fields: Evaluating and Improving the Planning and Scheduling Capabilities of LRM o1
Oct 03, 2024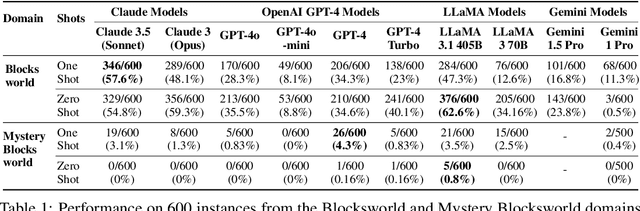
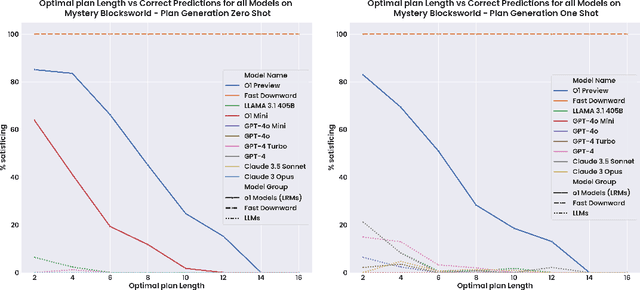
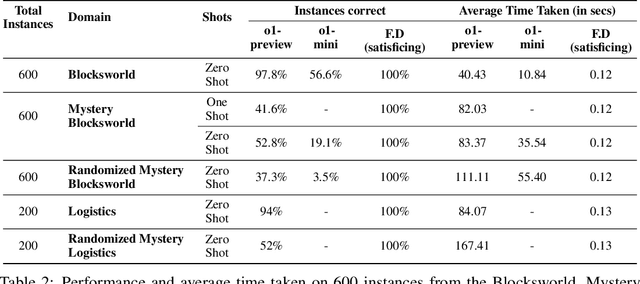
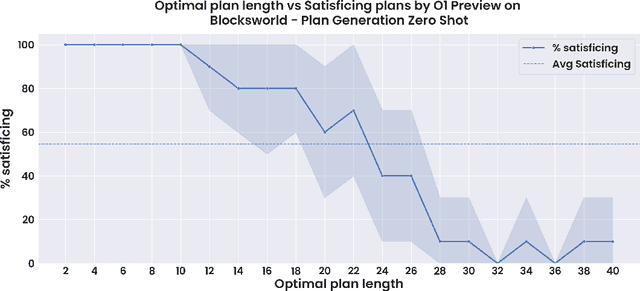
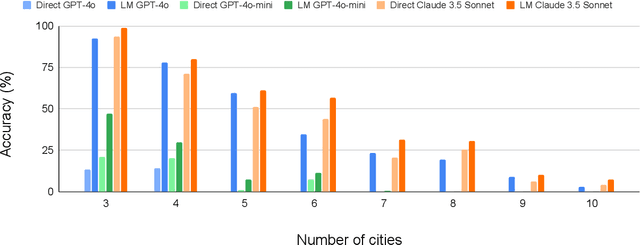
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities, but -- despite the slew of new private and open source LLMs since GPT3 -- progress has remained slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs -- making it a new kind of model: a Large Reasoning Model (LRM). In this paper, we evaluate the planning capabilities of two LRMs (o1-preview and o1-mini) on both planning and scheduling benchmarks. We see that while o1 does seem to offer significant improvements over autoregressive LLMs, this comes at a steep inference cost, while still failing to provide any guarantees over what it generates. We also show that combining o1 models with external verifiers -- in a so-called LRM-Modulo system -- guarantees the correctness of the combined system's output while further improving performance.
Algorithmic Language Models with Neurally Compiled Libraries
Jul 06, 2024Important tasks such as reasoning and planning are fundamentally algorithmic, meaning that solving them robustly requires acquiring true reasoning or planning algorithms, rather than shortcuts. Large Language Models lack true algorithmic ability primarily because of the limitations of neural network optimization algorithms, their optimization data and optimization objective, but also due to architectural inexpressivity. To solve this, our paper proposes augmenting LLMs with a library of fundamental operations and sophisticated differentiable programs, so that common algorithms do not need to be learned from scratch. We add memory, registers, basic operations, and adaptive recurrence to a transformer architecture built on LLaMA3. Then, we define a method for directly compiling algorithms into a differentiable starting library, which is used natively and propagates gradients for optimization. In this preliminary study, we explore the feasability of augmenting LLaMA3 with a differentiable computer, for instance by fine-tuning small transformers on simple algorithmic tasks with variable computational depth.