 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning in Strawberry Fields: Evaluating and Improving the Planning and Scheduling Capabilities of LRM o1
Paper and Code
Oct 03, 2024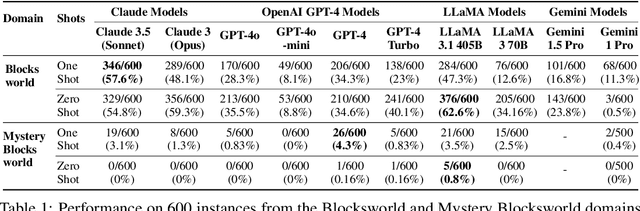
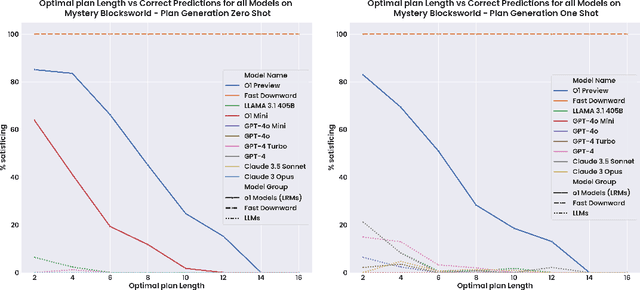
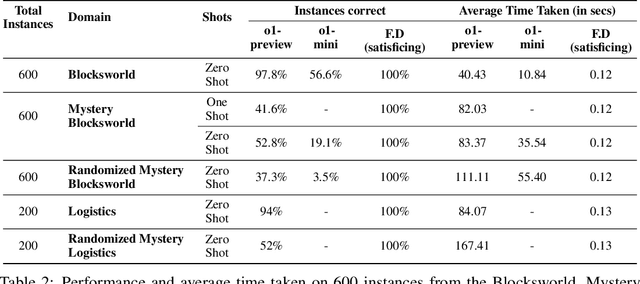
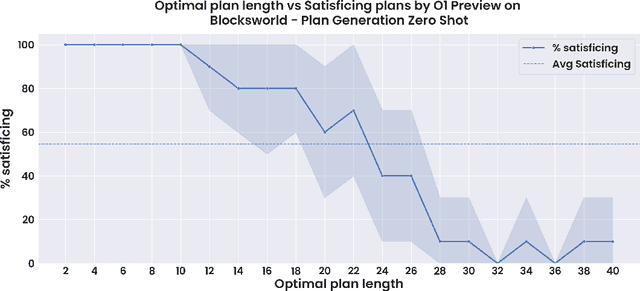
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities, but -- despite the slew of new private and open source LLMs since GPT3 -- progress has remained slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs -- making it a new kind of model: a Large Reasoning Model (LRM). In this paper, we evaluate the planning capabilities of two LRMs (o1-preview and o1-mini) on both planning and scheduling benchmarks. We see that while o1 does seem to offer significant improvements over autoregressive LLMs, this comes at a steep inference cost, while still failing to provide any guarantees over what it generates. We also show that combining o1 models with external verifiers -- in a so-called LRM-Modulo system -- guarantees the correctness of the combined system's output while further improving performance.