 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformative Thinking? The Brittle Correlation Between CoT Length and Problem Complexity
Sep 09, 2025Intermediate token generation (ITG), where a model produces output before the solution, has been proposed as a method to improve the performance of language models on reasoning tasks. While these reasoning traces or Chain of Thoughts (CoTs) are correlated with performance gains, the mechanisms underlying them remain unclear. A prevailing assumption in the community has been to anthropomorphize these tokens as "thinking", treating longer traces as evidence of higher problem-adaptive computation. In this work, we critically examine whether intermediate token sequence length reflects or correlates with problem difficulty. To do so, we train transformer models from scratch on derivational traces of the A* search algorithm, where the number of operations required to solve a maze problem provides a precise and verifiable measure of problem complexity. We first evaluate the models on trivial free-space problems, finding that even for the simplest tasks, they often produce excessively long reasoning traces and sometimes fail to generate a solution. We then systematically evaluate the model on out-of-distribution problems and find that the intermediate token length and ground truth A* trace length only loosely correlate. We notice that the few cases where correlation appears are those where the problems are closer to the training distribution, suggesting that the effect arises from approximate recall rather than genuine problem-adaptive computation. This suggests that the inherent computational complexity of the problem instance is not a significant factor, but rather its distributional distance from the training data. These results challenge the assumption that intermediate trace generation is adaptive to problem difficulty and caution against interpreting longer sequences in systems like R1 as automatically indicative of "thinking effort".
RL in Name Only? Analyzing the Structural Assumptions in RL post-training for LLMs
May 19, 2025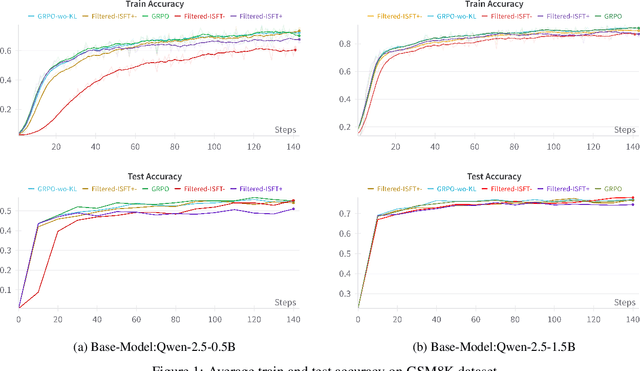
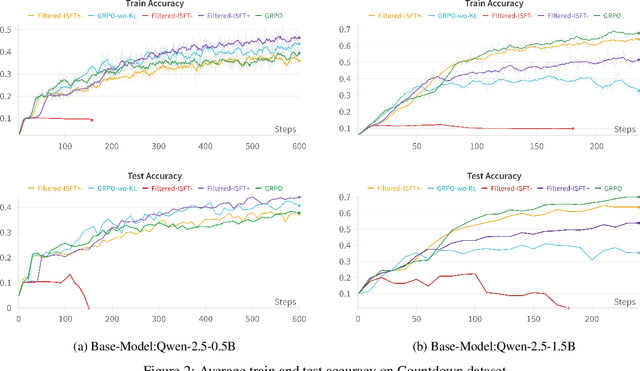

Reinforcement learning-based post-training of large language models (LLMs) has recently gained attention, particularly following the release of DeepSeek R1, which applied GRPO for fine-tuning. Amid the growing hype around improved reasoning abilities attributed to RL post-training, we critically examine the formulation and assumptions underlying these methods. We start by highlighting the popular structural assumptions made in modeling LLM training as a Markov Decision Process (MDP), and show how they lead to a degenerate MDP that doesn't quite need the RL/GRPO apparatus. The two critical structural assumptions include (1) making the MDP states be just a concatenation of the actions-with states becoming the context window and the actions becoming the tokens in LLMs and (2) splitting the reward of a state-action trajectory uniformly across the trajectory. Through a comprehensive analysis, we demonstrate that these simplifying assumptions make the approach effectively equivalent to an outcome-driven supervised learning. Our experiments on benchmarks including GSM8K and Countdown using Qwen-2.5 base models show that iterative supervised fine-tuning, incorporating both positive and negative samples, achieves performance comparable to GRPO-based training. We will also argue that the structural assumptions indirectly incentivize the RL to generate longer sequences of intermediate tokens-which in turn feeds into the narrative of "RL generating longer thinking traces." While RL may well be a very useful technique for improving the reasoning abilities of LLMs, our analysis shows that the simplistic structural assumptions made in modeling the underlying MDP render the popular LLM RL frameworks and their interpretations questionable.
Beyond Semantics: The Unreasonable Effectiveness of Reasonless Intermediate Tokens
May 19, 2025
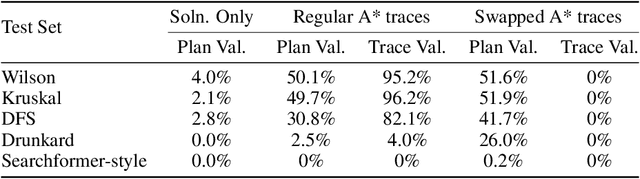
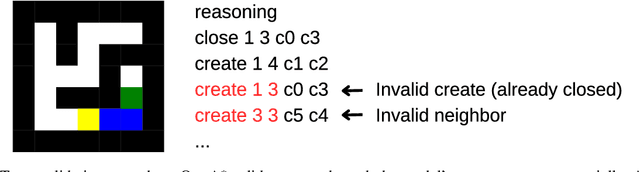
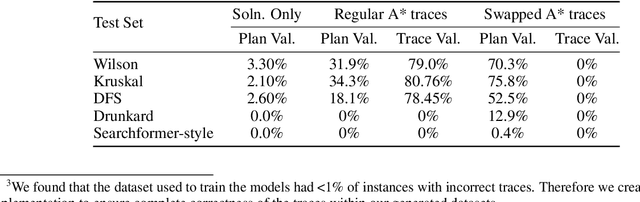
Recent impressive results from large reasoning models have been interpreted as a triumph of Chain of Thought (CoT), and especially of the process of training on CoTs sampled from base LLMs in order to help find new reasoning patterns. In this paper, we critically examine that interpretation by investigating how the semantics of intermediate tokens-often anthropomorphized as "thoughts" or reasoning traces and which are claimed to display behaviors like backtracking, self-verification etc.-actually influence model performance. We train transformer models on formally verifiable reasoning traces and solutions, constraining both intermediate steps and final outputs to align with those of a formal solver (in our case, A* search). By constructing a formal interpreter of the semantics of our problems and intended algorithm, we systematically evaluate not only solution accuracy but also the correctness of intermediate traces, thus allowing us to evaluate whether the latter causally influences the former. We notice that, despite significant improvements on the solution-only baseline, models trained on entirely correct traces still produce invalid reasoning traces when arriving at correct solutions. To further show that trace accuracy is only loosely connected to solution accuracy, we then train models on noisy, corrupted traces which have no relation to the specific problem each is paired with, and find that not only does performance remain largely consistent with models trained on correct data, but in some cases can improve upon it and generalize more robustly on out-of-distribution tasks. These results challenge the assumption that intermediate tokens or "Chains of Thought" induce predictable reasoning behaviors and caution against anthropomorphizing such outputs or over-interpreting them (despite their mostly correct forms) as evidence of human-like or algorithmic behaviors in language models.
(How) Do reasoning models reason?
Apr 14, 2025We will provide a broad unifying perspective on the recent breed of Large Reasoning Models (LRMs) such as OpenAI o1 and DeepSeek R1, including their promise, sources of power, misconceptions and limitations.
Planning in Strawberry Fields: Evaluating and Improving the Planning and Scheduling Capabilities of LRM o1
Oct 03, 2024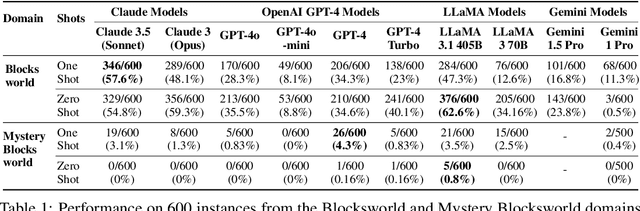
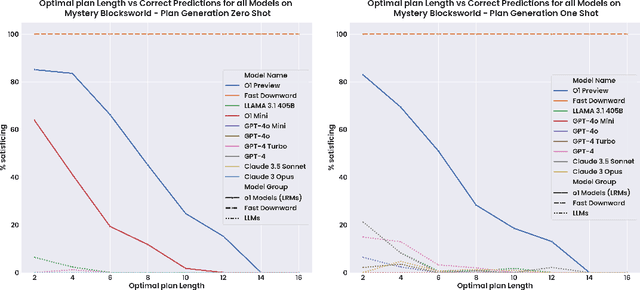
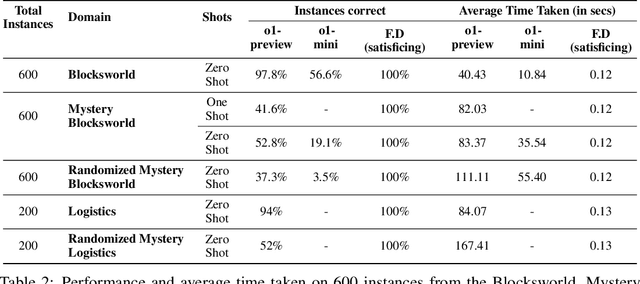
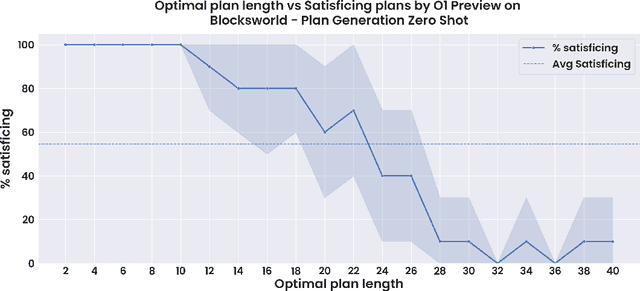
The ability to plan a course of action that achieves a desired state of affairs has long been considered a core competence of intelligent agents and has been an integral part of AI research since its inception. With the advent of large language models (LLMs), there has been considerable interest in the question of whether or not they possess such planning abilities, but -- despite the slew of new private and open source LLMs since GPT3 -- progress has remained slow. OpenAI claims that their recent o1 (Strawberry) model has been specifically constructed and trained to escape the normal limitations of autoregressive LLMs -- making it a new kind of model: a Large Reasoning Model (LRM). In this paper, we evaluate the planning capabilities of two LRMs (o1-preview and o1-mini) on both planning and scheduling benchmarks. We see that while o1 does seem to offer significant improvements over autoregressive LLMs, this comes at a steep inference cost, while still failing to provide any guarantees over what it generates. We also show that combining o1 models with external verifiers -- in a so-called LRM-Modulo system -- guarantees the correctness of the combined system's output while further improving performance.
Chain of Thoughtlessness: An Analysis of CoT in Planning
May 08, 2024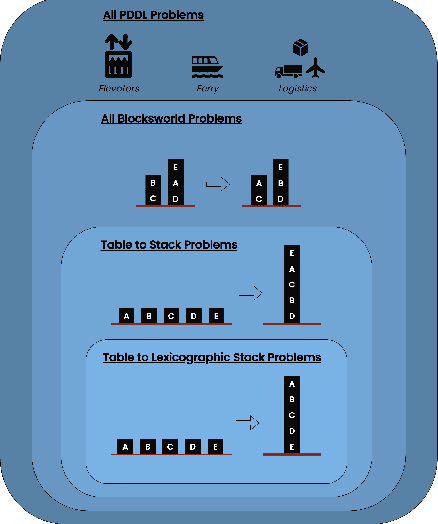
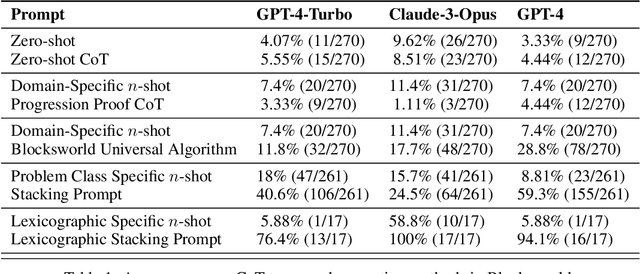
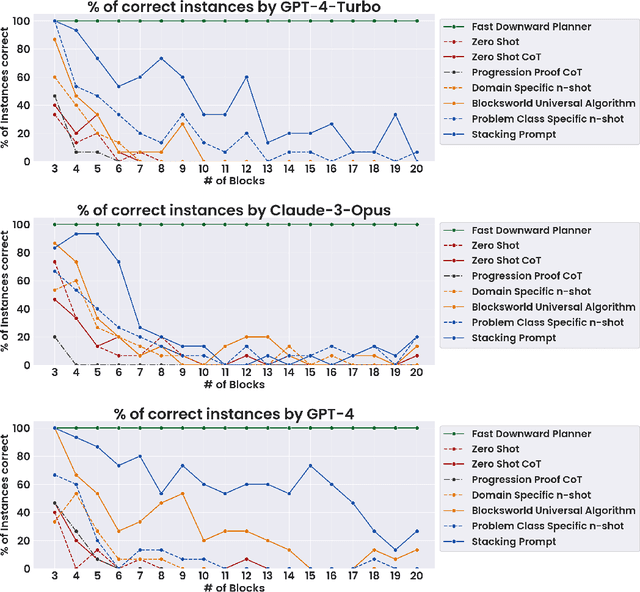
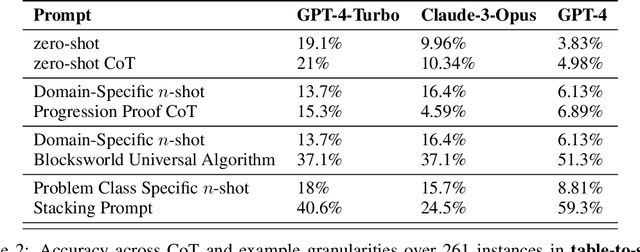
Large language model (LLM) performance on reasoning problems typically does not generalize out of distribution. Previous work has claimed that this can be mitigated by modifying prompts to include examples with chains of thought--demonstrations of solution procedures--with the intuition that it is possible to in-context teach an LLM an algorithm for solving the problem. This paper presents a case study of chain of thought on problems from Blocksworld, a classical planning domain, and examine the performance of two state-of-the-art LLMs across two axes: generality of examples given in prompt, and complexity of problems queried with each prompt. While our problems are very simple, we only find meaningful performance improvements from chain of thought prompts when those prompts are exceedingly specific to their problem class, and that those improvements quickly deteriorate as the size n of the query-specified stack grows past the size of stacks shown in the examples. Our results hint that, contrary to previous claims in the literature, CoT's performance improvements do not stem from the model learning general algorithmic procedures via demonstrations and depend on carefully engineering highly problem specific prompts. This spotlights drawbacks of chain of thought, especially because of the sharp tradeoff between possible performance gains and the amount of human labor necessary to generate examples with correct reasoning traces.
On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks
Feb 12, 2024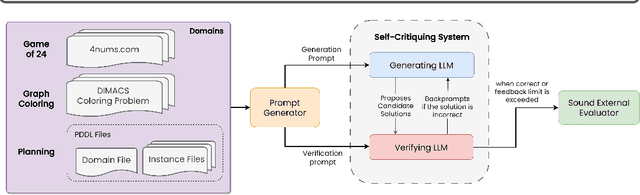



There has been considerable divergence of opinion on the reasoning abilities of Large Language Models (LLMs). While the initial optimism that reasoning might emerge automatically with scale has been tempered thanks to a slew of counterexamples--ranging from multiplication to simple planning--there persists a wide spread belief that LLMs can self-critique and improve their own solutions in an iterative fashion. This belief seemingly rests on the assumption that verification of correctness should be easier than generation--a rather classical argument from computational complexity--which should be irrelevant to LLMs to the extent that what they are doing is approximate retrieval. In this paper, we set out to systematically investigate the effectiveness of iterative prompting in the context of reasoning and planning. We present a principled empirical study of the performance of GPT-4 in three domains: Game of 24, Graph Coloring, and STRIPS planning. We experiment both with the model critiquing its own answers and with an external correct reasoner verifying proposed solutions. In each case, we analyze whether the content of criticisms actually affects bottom line performance, and whether we can ablate elements of the augmented system without losing performance. We observe significant performance collapse with self-critique, significant performance gains with sound external verification, but that the content of critique doesn't matter to the performance of the system. In fact, merely re-prompting with a sound verifier maintains most of the benefits of more involved setups.
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Feb 06, 2024
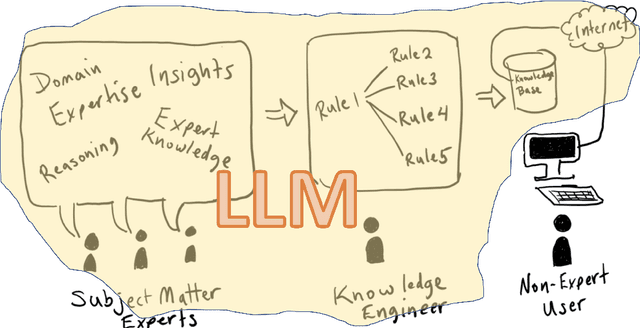
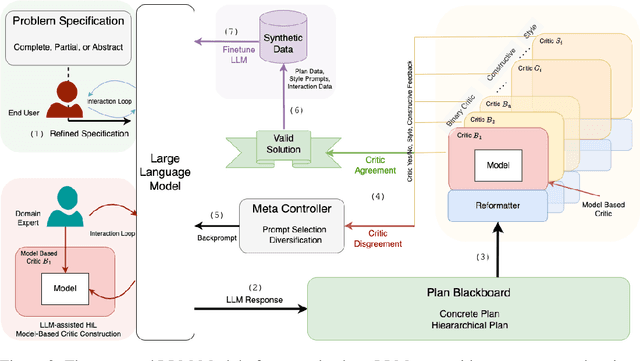
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {\bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems
Oct 19, 2023



There has been considerable divergence of opinion on the reasoning abilities of Large Language Models (LLMs). While the initial optimism that reasoning might emerge automatically with scale has been tempered thanks to a slew of counterexamples, a wide spread belief in their iterative self-critique capabilities persists. In this paper, we set out to systematically investigate the effectiveness of iterative prompting of LLMs in the context of Graph Coloring, a canonical NP-complete reasoning problem that is related to propositional satisfiability as well as practical problems like scheduling and allocation. We present a principled empirical study of the performance of GPT4 in solving graph coloring instances or verifying the correctness of candidate colorings. In iterative modes, we experiment with the model critiquing its own answers and an external correct reasoner verifying proposed solutions. In both cases, we analyze whether the content of the criticisms actually affects bottom line performance. The study seems to indicate that (i) LLMs are bad at solving graph coloring instances (ii) they are no better at verifying a solution--and thus are not effective in iterative modes with LLMs critiquing LLM-generated solutions (iii) the correctness and content of the criticisms--whether by LLMs or external solvers--seems largely irrelevant to the performance of iterative prompting. We show that the observed increase in effectiveness is largely due to the correct solution being fortuitously present in the top-k completions of the prompt (and being recognized as such by an external verifier). Our results thus call into question claims about the self-critiquing capabilities of state of the art LLMs.