 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Traces, Unexpected Outcomes: Investigating the Disconnect in Trace-Based Knowledge Distillation
May 20, 2025Question Answering (QA) poses a challenging and critical problem, particularly in today's age of interactive dialogue systems such as ChatGPT, Perplexity, Microsoft Copilot, etc. where users demand both accuracy and transparency in the model's outputs. Since smaller language models (SLMs) are computationally more efficient but often under-perform compared to larger models, Knowledge Distillation (KD) methods allow for finetuning these smaller models to improve their final performance. Lately, the intermediate tokens or the so called `reasoning' traces produced by Chain-of-Thought (CoT) or by reasoning models such as DeepSeek R1 are used as a training signal for KD. However, these reasoning traces are often verbose and difficult to interpret or evaluate. In this work, we aim to address the challenge of evaluating the faithfulness of these reasoning traces and their correlation with the final performance. To this end, we employ a KD method leveraging rule-based problem decomposition. This approach allows us to break down complex queries into structured sub-problems, generating interpretable traces whose correctness can be readily evaluated, even at inference time. Specifically, we demonstrate this approach on Open Book QA, decomposing the problem into a Classification step and an Information Retrieval step, thereby simplifying trace evaluation. Our SFT experiments with correct and incorrect traces on the CoTemp QA, Microsoft Machine Reading Comprehension QA, and Facebook bAbI QA datasets reveal the striking finding that correct traces do not necessarily imply that the model outputs the correct final solution. Similarly, we find a low correlation between correct final solutions and intermediate trace correctness. These results challenge the implicit assumption behind utilizing reasoning traces for improving SLMs' final performance via KD.
Who is Helping Whom? Analyzing Inter-dependencies to Evaluate Cooperation in Human-AI Teaming
Feb 10, 2025



The long-standing research challenges of Human-AI Teaming(HAT) and Zero-shot Cooperation(ZSC) have been tackled by applying multi-agent reinforcement learning(MARL) to train an agent by optimizing the environment reward function and evaluating their performance through task performance metrics such as task reward. However, such evaluation focuses only on task completion, while being agnostic to `how' the two agents work with each other. Specifically, we are interested in understanding the cooperation arising within the team when trained agents are paired with humans. To formally address this problem, we propose the concept of interdependence to measure how much agents rely on each other's actions to achieve the shared goal, as a key metric for evaluating cooperation in human-agent teams. Towards this, we ground this concept through a symbolic formalism and define evaluation metrics that allow us to assess the degree of reliance between the agents' actions. We pair state-of-the-art agents trained through MARL for HAT, with learned human models for the the popular Overcooked domain, and evaluate the team performance for these human-agent teams. Our results demonstrate that trained agents are not able to induce cooperative behavior, reporting very low levels of interdependence across all the teams. We also report that teaming performance of a team is not necessarily correlated with the task reward.
Robust Planning with LLM-Modulo Framework: Case Study in Travel Planning
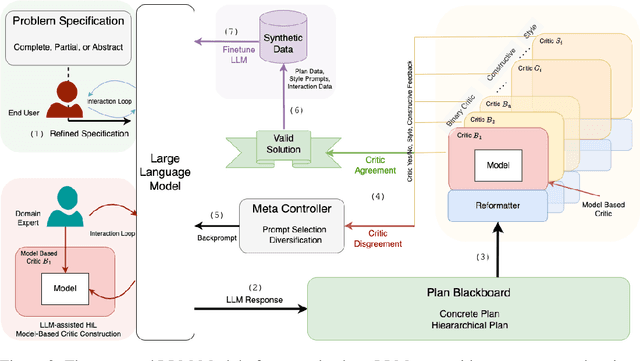
May 31, 2024As the applicability of Large Language Models (LLMs) extends beyond traditional text processing tasks, there is a burgeoning interest in their potential to excel in planning and reasoning assignments, realms traditionally reserved for System 2 cognitive competencies. Despite their perceived versatility, the research community is still unraveling effective strategies to harness these models in such complex domains. The recent discourse introduced by the paper on LLM Modulo marks a significant stride, proposing a conceptual framework that enhances the integration of LLMs into diverse planning and reasoning activities. This workshop paper delves into the practical application of this framework within the domain of travel planning, presenting a specific instance of its implementation. We are using the Travel Planning benchmark by the OSU NLP group, a benchmark for evaluating the performance of LLMs in producing valid itineraries based on user queries presented in natural language. While popular methods of enhancing the reasoning abilities of LLMs such as Chain of Thought, ReAct, and Reflexion achieve a meager 0%, 0.6%, and 0% with GPT3.5-Turbo respectively, our operationalization of the LLM-Modulo framework for TravelPlanning domain provides a remarkable improvement, enhancing baseline performances by 4.6x for GPT4-Turbo and even more for older models like GPT3.5-Turbo from 0% to 5%. Furthermore, we highlight the other useful roles of LLMs in the planning pipeline, as suggested in LLM-Modulo, which can be reliably operationalized such as extraction of useful critics and reformulator for critics.
Efficient Reinforcement Learning via Large Language Model-based Search
May 24, 2024



Reinforcement Learning (RL) suffers from sample inefficiency in sparse reward domains, and the problem is pronounced if there are stochastic transitions. To improve the sample efficiency, reward shaping is a well-studied approach to introduce intrinsic rewards that can help the RL agent converge to an optimal policy faster. However, designing a useful reward shaping function specific to each problem is challenging, even for domain experts. They would either have to rely on task-specific domain knowledge or provide an expert demonstration independently for each task. Given, that Large Language Models (LLMs) have rapidly gained prominence across a magnitude of natural language tasks, we aim to answer the following question: Can we leverage LLMs to construct a reward shaping function that can boost the sample efficiency of an RL agent? In this work, we aim to leverage off-the-shelf LLMs to generate a guide policy by solving a simpler deterministic abstraction of the original problem that can then be used to construct the reward shaping function for the downstream RL agent. Given the ineffectiveness of directly prompting LLMs, we propose MEDIC: a framework that augments LLMs with a Model-based feEDback critIC, which verifies LLM-generated outputs, to generate a possibly sub-optimal but valid plan for the abstract problem. Our experiments across domains from the BabyAI environment suite show 1) the effectiveness of augmenting LLMs with MEDIC, 2) a significant improvement in the sample complexity of PPO and A2C-based RL agents when guided by our LLM-generated plan, and finally, 3) pave the direction for further explorations of how these models can be used to augment existing RL pipelines.
On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models
May 22, 2024



The reasoning abilities of Large Language Models (LLMs) remain a topic of debate. Some methods such as ReAct-based prompting, have gained popularity for claiming to enhance sequential decision-making abilities of agentic LLMs. However, it is unclear what is the source of improvement in LLM reasoning with ReAct based prompting. In this paper we examine these claims of ReAct based prompting in improving agentic LLMs for sequential decision-making. By introducing systematic variations to the input prompt we perform a sensitivity analysis along the claims of ReAct and find that the performance is minimally influenced by the "interleaving reasoning trace with action execution" or the content of the generated reasoning traces in ReAct, contrary to original claims and common usage. Instead, the performance of LLMs is driven by the similarity between input example tasks and queries, implicitly forcing the prompt designer to provide instance-specific examples which significantly increases the cognitive burden on the human. Our investigation shows that the perceived reasoning abilities of LLMs stem from the exemplar-query similarity and approximate retrieval rather than any inherent reasoning abilities.
LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Feb 06, 2024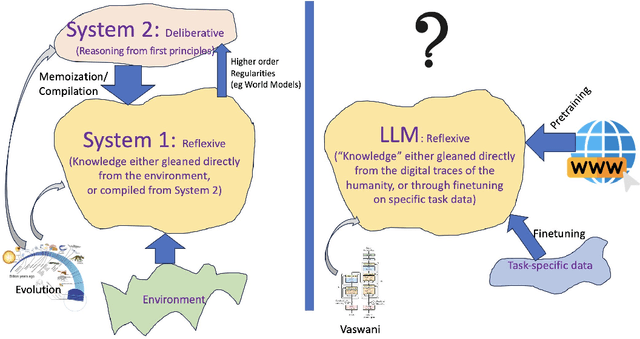
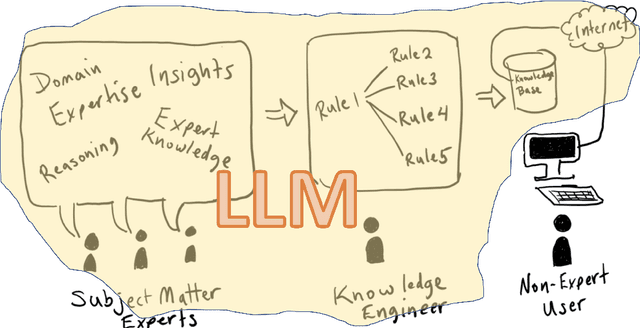
There is considerable confusion about the role of Large Language Models (LLMs) in planning and reasoning tasks. On one side are over-optimistic claims that LLMs can indeed do these tasks with just the right prompting or self-verification strategies. On the other side are perhaps over-pessimistic claims that all that LLMs are good for in planning/reasoning tasks are as mere translators of the problem specification from one syntactic format to another, and ship the problem off to external symbolic solvers. In this position paper, we take the view that both these extremes are misguided. We argue that auto-regressive LLMs cannot, by themselves, do planning or self-verification (which is after all a form of reasoning), and shed some light on the reasons for misunderstandings in the literature. We will also argue that LLMs should be viewed as universal approximate knowledge sources that have much more meaningful roles to play in planning/reasoning tasks beyond simple front-end/back-end format translators. We present a vision of {\bf LLM-Modulo Frameworks} that combine the strengths of LLMs with external model-based verifiers in a tighter bi-directional interaction regime. We will show how the models driving the external verifiers themselves can be acquired with the help of LLMs. We will also argue that rather than simply pipelining LLMs and symbolic components, this LLM-Modulo Framework provides a better neuro-symbolic approach that offers tighter integration between LLMs and symbolic components, and allows extending the scope of model-based planning/reasoning regimes towards more flexible knowledge, problem and preference specifications.
Theory of Mind abilities of Large Language Models in Human-Robot Interaction : An Illusion?
Jan 17, 2024Large Language Models have shown exceptional generative abilities in various natural language and generation tasks. However, possible anthropomorphization and leniency towards failure cases have propelled discussions on emergent abilities of Large Language Models especially on Theory of Mind (ToM) abilities in Large Language Models. While several false-belief tests exists to verify the ability to infer and maintain mental models of another entity, we study a special application of ToM abilities that has higher stakes and possibly irreversible consequences : Human Robot Interaction. In this work, we explore the task of Perceived Behavior Recognition, where a robot employs a Large Language Model (LLM) to assess the robot's generated behavior in a manner similar to human observer. We focus on four behavior types, namely - explicable, legible, predictable, and obfuscatory behavior which have been extensively used to synthesize interpretable robot behaviors. The LLMs goal is, therefore to be a human proxy to the agent, and to answer how a certain agent behavior would be perceived by the human in the loop, for example "Given a robot's behavior X, would the human observer find it explicable?". We conduct a human subject study to verify that the users are able to correctly answer such a question in the curated situations (robot setting and plan) across five domains. A first analysis of the belief test yields extremely positive results inflating ones expectations of LLMs possessing ToM abilities. We then propose and perform a suite of perturbation tests which breaks this illusion, i.e. Inconsistent Belief, Uninformative Context and Conviction Test. We conclude that, the high score of LLMs on vanilla prompts showcases its potential use in HRI settings, however to possess ToM demands invariance to trivial or irrelevant perturbations in the context which LLMs lack.
Benchmarking Multi-Agent Preference-based Reinforcement Learning for Human-AI Teaming
Dec 21, 2023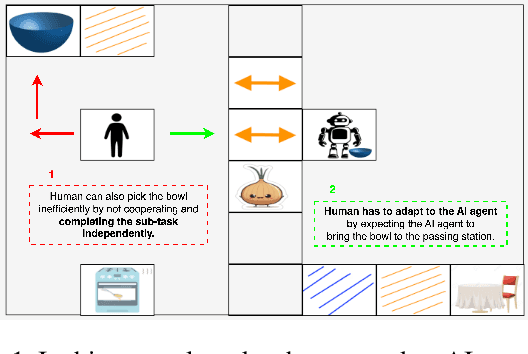



Preference-based Reinforcement Learning (PbRL) is an active area of research, and has made significant strides in single-agent actor and in observer human-in-the-loop scenarios. However, its application within the co-operative multi-agent RL frameworks, where humans actively participate and express preferences for agent behavior, remains largely uncharted. We consider a two-agent (Human-AI) cooperative setup where both the agents are rewarded according to human's reward function for the team. However, the agent does not have access to it, and instead, utilizes preference-based queries to elicit its objectives and human's preferences for the robot in the human-robot team. We introduce the notion of Human-Flexibility, i.e. whether the human partner is amenable to multiple team strategies, with a special case being Specified Orchestration where the human has a single team policy in mind (most constrained case). We propose a suite of domains to study PbRL for Human-AI cooperative setup which explicitly require forced cooperation. Adapting state-of-the-art single-agent PbRL algorithms to our two-agent setting, we conduct a comprehensive benchmarking study across our domain suite. Our findings highlight the challenges associated with high degree of Human-Flexibility and the limited access to the human's envisioned policy in PbRL for Human-AI cooperation. Notably, we observe that PbRL algorithms exhibit effective performance exclusively in the case of Specified Orchestration which can be seen as an upper bound PbRL performance for future research.
Exploiting Unlabeled Data for Feedback Efficient Human Preference based Reinforcement Learning
Feb 17, 2023

Preference Based Reinforcement Learning has shown much promise for utilizing human binary feedback on queried trajectory pairs to recover the underlying reward model of the Human in the Loop (HiL). While works have attempted to better utilize the queries made to the human, in this work we make two observations about the unlabeled trajectories collected by the agent and propose two corresponding loss functions that ensure participation of unlabeled trajectories in the reward learning process, and structure the embedding space of the reward model such that it reflects the structure of state space with respect to action distances. We validate the proposed method on one locomotion domain and one robotic manipulation task and compare with the state-of-the-art baseline PEBBLE. We further present an ablation of the proposed loss components across both the domains and find that not only each of the loss components perform better than the baseline, but the synergic combination of the two has much better reward recovery and human feedback sample efficiency.
Reinforcement Learning Methods for Wordle: A POMDP/Adaptive Control Approach
Nov 29, 2022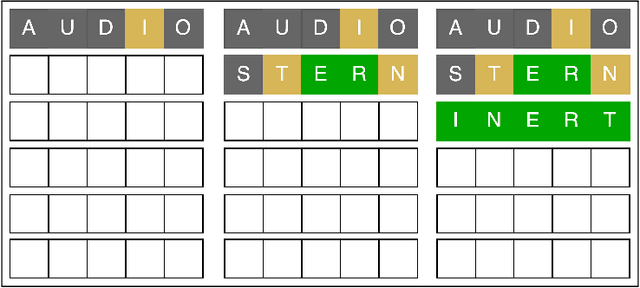

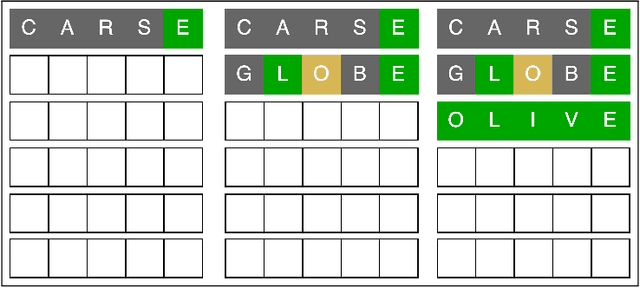

In this paper we address the solution of the popular Wordle puzzle, using new reinforcement learning methods, which apply more generally to adaptive control of dynamic systems and to classes of Partially Observable Markov Decision Process (POMDP) problems. These methods are based on approximation in value space and the rollout approach, admit a straightforward implementation, and provide improved performance over various heuristic approaches. For the Wordle puzzle, they yield on-line solution strategies that are very close to optimal at relatively modest computational cost. Our methods are viable for more complex versions of Wordle and related search problems, for which an optimal strategy would be impossible to compute. They are also applicable to a wide range of adaptive sequential decision problems that involve an unknown or frequently changing environment whose parameters are estimated on-line.