 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Planning with Compound LLM Architectures: An LLM-Modulo Approach
Paper and Code
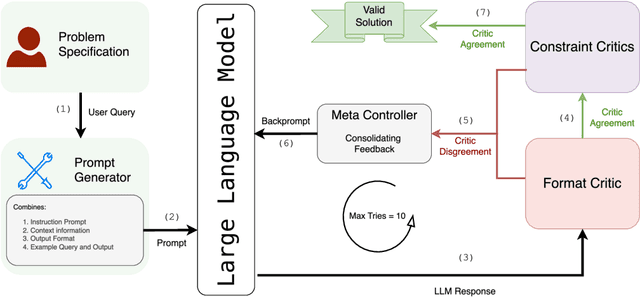

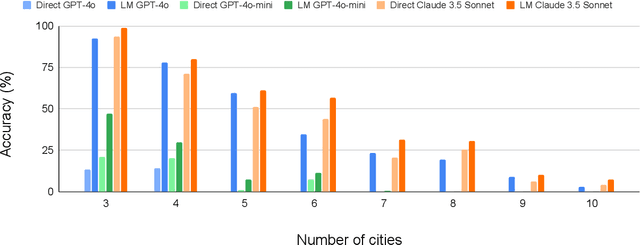

Previous work has attempted to boost Large Language Model (LLM) performance on planning and scheduling tasks through a variety of prompt engineering techniques. While these methods can work within the distributions tested, they are neither robust nor predictable. This limitation can be addressed through compound LLM architectures where LLMs work in conjunction with other components to ensure reliability. In this paper, we present a technical evaluation of a compound LLM architecture--the LLM-Modulo framework. In this framework, an LLM is paired with a complete set of sound verifiers that validate its output, re-prompting it if it fails. This approach ensures that the system can never output any fallacious output, and therefore that every output generated is guaranteed correct--something previous techniques have not been able to claim. Our results, evaluated across four scheduling domains, demonstrate significant performance gains with the LLM-Modulo framework using various models. Additionally, we explore modifications to the base configuration of the framework and assess their impact on overall system performance.