 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents
Apr 21, 2026Personalized agents that interact with users over long periods must maintain persistent memory across sessions and update it as circumstances change. However, existing benchmarks predominantly frame long-term memory evaluation as fact retrieval from past conversations, providing limited insight into agents' ability to consolidate memory over time or handle frequent knowledge updates. We introduce Memora, a long-term memory benchmark spanning weeks to months long user conversations. The benchmark evaluates three memory-grounded tasks: remembering, reasoning, and recommending. To ensure data quality, we employ automated memory-grounding checks and human evaluation. We further introduce Forgetting-Aware Memory Accuracy (FAMA), a metric that penalizes reliance on obsolete or invalidated memory when evaluating long-term memory. Evaluations of four LLMs and six memory agents reveal frequent reuse of invalid memories and failures to reconcile evolving memories. Memory agents offer marginal improvements, exposing shortcomings in long-term memory for personalized agents.
ViTaB-A: Evaluating Multimodal Large Language Models on Visual Table Attribution
Feb 17, 2026Multimodal Large Language Models (mLLMs) are often used to answer questions in structured data such as tables in Markdown, JSON, and images. While these models can often give correct answers, users also need to know where those answers come from. In this work, we study structured data attribution/citation, which is the ability of the models to point to the specific rows and columns that support an answer. We evaluate several mLLMs across different table formats and prompting strategies. Our results show a clear gap between question answering and evidence attribution. Although question answering accuracy remains moderate, attribution accuracy is much lower, near random for JSON inputs, across all models. We also find that models are more reliable at citing rows than columns, and struggle more with textual formats than images. Finally, we observe notable differences across model families. Overall, our findings show that current mLLMs are unreliable at providing fine-grained, trustworthy attribution for structured data, which limits their usage in applications requiring transparency and traceability.
Lost in Speech: Benchmarking, Evaluation, and Parsing of Spoken Code-Switching Beyond Standard UD Assumptions
Feb 06, 2026Spoken code-switching (CSW) challenges syntactic parsing in ways not observed in written text. Disfluencies, repetition, ellipsis, and discourse-driven structure routinely violate standard Universal Dependencies (UD) assumptions, causing parsers and large language models (LLMs) to fail despite strong performance on written data. These failures are compounded by rigid evaluation metrics that conflate genuine structural errors with acceptable variation. In this work, we present a systems-oriented approach to spoken CSW parsing. We introduce a linguistically grounded taxonomy of spoken CSW phenomena and SpokeBench, an expert-annotated gold benchmark designed to test spoken-language structure beyond standard UD assumptions. We further propose FLEX-UD, an ambiguity-aware evaluation metric, which reveals that existing parsing techniques perform poorly on spoken CSW by penalizing linguistically plausible analyses as errors. We then propose DECAP, a decoupled agentic parsing framework that isolates spoken-phenomena handling from core syntactic analysis. Experiments show that DECAP produces more robust and interpretable parses without retraining and achieves up to 52.6% improvements over existing parsing techniques. FLEX-UD evaluations further reveal qualitative improvements that are masked by standard metrics.
The Perceptual Observatory Characterizing Robustness and Grounding in MLLMs
Dec 17, 2025Recent advances in multimodal large language models (MLLMs) have yielded increasingly powerful models, yet their perceptual capacities remain poorly characterized. In practice, most model families scale language component while reusing nearly identical vision encoders (e.g., Qwen2.5-VL 3B/7B/72B), which raises pivotal concerns about whether progress reflects genuine visual grounding or reliance on internet-scale textual world knowledge. Existing evaluation methods emphasize end-task accuracy, overlooking robustness, attribution fidelity, and reasoning under controlled perturbations. We present The Perceptual Observatory, a framework that characterizes MLLMs across verticals like: (i) simple vision tasks, such as face matching and text-in-vision comprehension capabilities; (ii) local-to-global understanding, encompassing image matching, grid pointing game, and attribute localization, which tests general visual grounding. Each vertical is instantiated with ground-truth datasets of faces and words, systematically perturbed through pixel-based augmentations and diffusion-based stylized illusions. The Perceptual Observatory moves beyond leaderboard accuracy to yield insights into how MLLMs preserve perceptual grounding and relational structure under perturbations, providing a principled foundation for analyzing strengths and weaknesses of current and future models.
Stable Cinemetrics : Structured Taxonomy and Evaluation for Professional Video Generation
Sep 30, 2025Recent advances in video generation have enabled high-fidelity video synthesis from user provided prompts. However, existing models and benchmarks fail to capture the complexity and requirements of professional video generation. Towards that goal, we introduce Stable Cinemetrics, a structured evaluation framework that formalizes filmmaking controls into four disentangled, hierarchical taxonomies: Setup, Event, Lighting, and Camera. Together, these taxonomies define 76 fine-grained control nodes grounded in industry practices. Using these taxonomies, we construct a benchmark of prompts aligned with professional use cases and develop an automated pipeline for prompt categorization and question generation, enabling independent evaluation of each control dimension. We conduct a large-scale human study spanning 10+ models and 20K videos, annotated by a pool of 80+ film professionals. Our analysis, both coarse and fine-grained reveal that even the strongest current models exhibit significant gaps, particularly in Events and Camera-related controls. To enable scalable evaluation, we train an automatic evaluator, a vision-language model aligned with expert annotations that outperforms existing zero-shot baselines. SCINE is the first approach to situate professional video generation within the landscape of video generative models, introducing taxonomies centered around cinematic controls and supporting them with structured evaluation pipelines and detailed analyses to guide future research.
AcT2I: Evaluating and Improving Action Depiction in Text-to-Image Models
Sep 19, 2025Text-to-Image (T2I) models have recently achieved remarkable success in generating images from textual descriptions. However, challenges still persist in accurately rendering complex scenes where actions and interactions form the primary semantic focus. Our key observation in this work is that T2I models frequently struggle to capture nuanced and often implicit attributes inherent in action depiction, leading to generating images that lack key contextual details. To enable systematic evaluation, we introduce AcT2I, a benchmark designed to evaluate the performance of T2I models in generating images from action-centric prompts. We experimentally validate that leading T2I models do not fare well on AcT2I. We further hypothesize that this shortcoming arises from the incomplete representation of the inherent attributes and contextual dependencies in the training corpora of existing T2I models. We build upon this by developing a training-free, knowledge distillation technique utilizing Large Language Models to address this limitation. Specifically, we enhance prompts by incorporating dense information across three dimensions, observing that injecting prompts with temporal details significantly improves image generation accuracy, with our best model achieving an increase of 72%. Our findings highlight the limitations of current T2I methods in generating images that require complex reasoning and demonstrate that integrating linguistic knowledge in a systematic way can notably advance the generation of nuanced and contextually accurate images.
How Can Input Reformulation Improve Tool Usage Accuracy in a Complex Dynamic Environment? A Study on $τ$-bench
Aug 28, 2025Recent advances in reasoning and planning capabilities of large language models (LLMs) have enabled their potential as autonomous agents capable of tool use in dynamic environments. However, in multi-turn conversational environments like $\tau$-bench, these agents often struggle with consistent reasoning, adherence to domain-specific policies, and extracting correct information over a long horizon of tool-calls and conversation. To capture and mitigate these failures, we conduct a comprehensive manual analysis of the common errors occurring in the conversation trajectories. We then experiment with reformulations of inputs to the tool-calling agent for improvement in agent decision making. Finally, we propose the Input-Reformulation Multi-Agent (IRMA) framework, which automatically reformulates user queries augmented with relevant domain rules and tool suggestions for the tool-calling agent to focus on. The results show that IRMA significantly outperforms ReAct, Function Calling, and Self-Reflection by 16.1%, 12.7%, and 19.1%, respectively, in overall pass^5 scores. These findings highlight the superior reliability and consistency of IRMA compared to other methods in dynamic environments.
ThinkTuning: Instilling Cognitive Reflections without Distillation
Aug 11, 2025
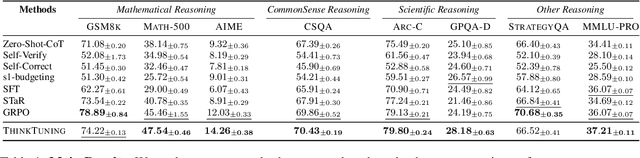
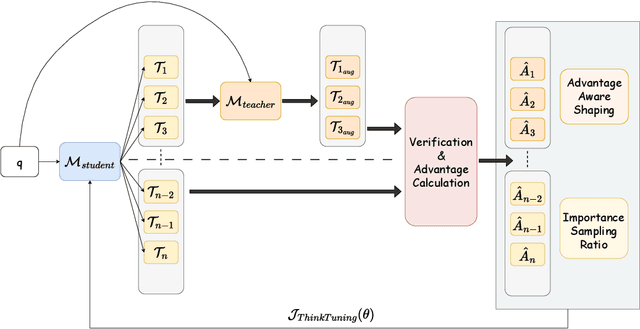
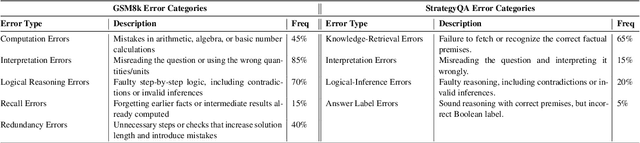
Recent advances in test-time scaling have led to the emergence of thinking LLMs that exhibit self-reflective behaviors and multi-step reasoning. While RL drives this self-improvement paradigm, a recent study (Gandhi et al., 2025) shows that RL alone does not truly instill these new reasoning abilities - it merely draws out behaviors already present in the base models. This raises a question: How can we train the models that don't exhibit such thinking behavior to develop it in the first place? To this end, we propose ThinkTuning, a GRPO-based interactive training approach where we augment the rollouts of a student model with the guidance from a teacher model. A simple idea from classroom practice inspires our method: a teacher poses a problem, lets the student try an answer, then gives corrective feedback -- enough to point the mind in the right direction and then show the solution. Each piece of feedback reshapes the student's thoughts, leading them to arrive at the correct solution. Similarly, we find that this type of implicit supervision through feedback from a teacher model of the same size improves the reasoning capabilities of the student model. In particular, on average, our method shows a 3.85% improvement over zero-shot baselines across benchmarks, and on MATH-500, AIME and GPQA-Diamond it shows 2.08%, 2.23% and 3.99% improvements over the vanilla-GRPO baseline. Source code is available at https://github.com/3rdAT/ThinkTuning.
PLAN-TUNING: Post-Training Language Models to Learn Step-by-Step Planning for Complex Problem Solving
Jul 10, 2025Recently, decomposing complex problems into simple subtasks--a crucial part of human-like natural planning--to solve the given problem has significantly boosted the performance of large language models (LLMs). However, leveraging such planning structures during post-training to boost the performance of smaller open-source LLMs remains underexplored. Motivated by this, we introduce PLAN-TUNING, a unified post-training framework that (i) distills synthetic task decompositions (termed "planning trajectories") from large-scale LLMs and (ii) fine-tunes smaller models via supervised and reinforcement-learning objectives designed to mimic these planning processes to improve complex reasoning. On GSM8k and the MATH benchmarks, plan-tuned models outperform strong baselines by an average $\sim7\%$. Furthermore, plan-tuned models show better generalization capabilities on out-of-domain datasets, with average $\sim10\%$ and $\sim12\%$ performance improvements on OlympiadBench and AIME 2024, respectively. Our detailed analysis demonstrates how planning trajectories improves complex reasoning capabilities, showing that PLAN-TUNING is an effective strategy for improving task-specific performance of smaller LLMs.
QA-LIGN: Aligning LLMs through Constitutionally Decomposed QA
Jun 09, 2025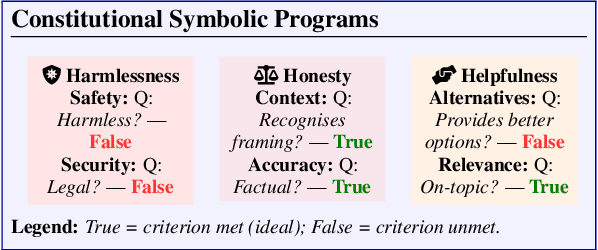
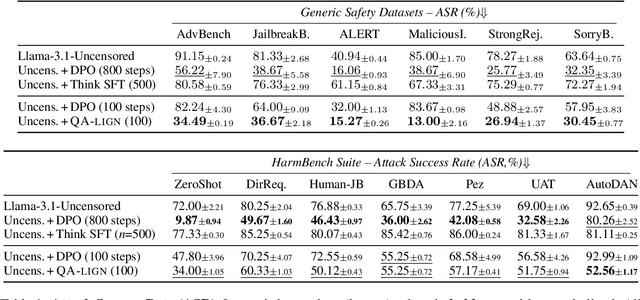
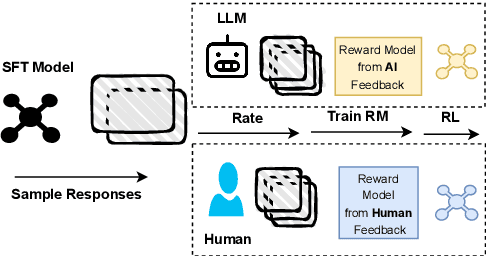

Alignment of large language models with explicit principles (such as helpfulness, honesty, and harmlessness) is crucial for ensuring safe and reliable AI systems. However, standard reward-based alignment methods typically collapse diverse feedback into a single scalar reward, entangling multiple objectives into one opaque training signal, which hinders interpretability. In this work, we introduce QA-LIGN, an automatic symbolic reward decomposition approach that preserves the structure of each constitutional principle within the reward mechanism. Instead of training a black-box reward model that outputs a monolithic score, QA-LIGN formulates principle-specific evaluation questions and derives separate reward components for each principle, making it a drop-in reward model replacement. Experiments aligning an uncensored large language model with a set of constitutional principles demonstrate that QA-LIGN offers greater transparency and adaptability in the alignment process. At the same time, our approach achieves performance on par with or better than a DPO baseline. Overall, these results represent a step toward more interpretable and controllable alignment of language models, achieved without sacrificing end-task performance.