 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Cinemetrics : Structured Taxonomy and Evaluation for Professional Video Generation
Sep 30, 2025Recent advances in video generation have enabled high-fidelity video synthesis from user provided prompts. However, existing models and benchmarks fail to capture the complexity and requirements of professional video generation. Towards that goal, we introduce Stable Cinemetrics, a structured evaluation framework that formalizes filmmaking controls into four disentangled, hierarchical taxonomies: Setup, Event, Lighting, and Camera. Together, these taxonomies define 76 fine-grained control nodes grounded in industry practices. Using these taxonomies, we construct a benchmark of prompts aligned with professional use cases and develop an automated pipeline for prompt categorization and question generation, enabling independent evaluation of each control dimension. We conduct a large-scale human study spanning 10+ models and 20K videos, annotated by a pool of 80+ film professionals. Our analysis, both coarse and fine-grained reveal that even the strongest current models exhibit significant gaps, particularly in Events and Camera-related controls. To enable scalable evaluation, we train an automatic evaluator, a vision-language model aligned with expert annotations that outperforms existing zero-shot baselines. SCINE is the first approach to situate professional video generation within the landscape of video generative models, introducing taxonomies centered around cinematic controls and supporting them with structured evaluation pipelines and detailed analyses to guide future research.
Contrastive Language-Action Pre-training for Temporal Localization
Apr 26, 2022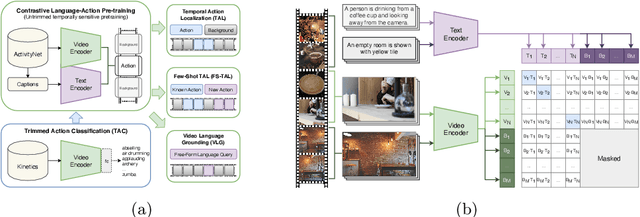
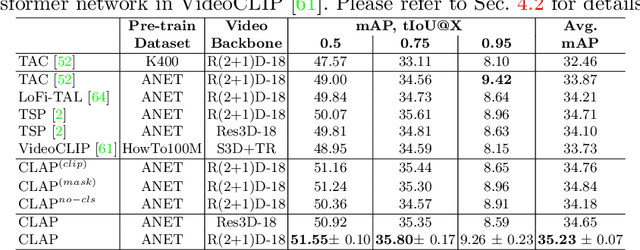
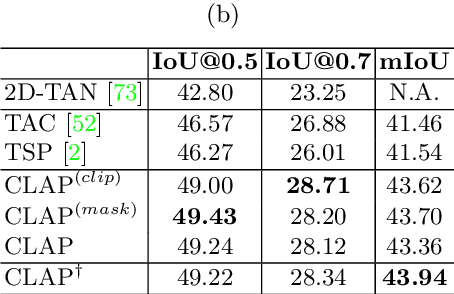
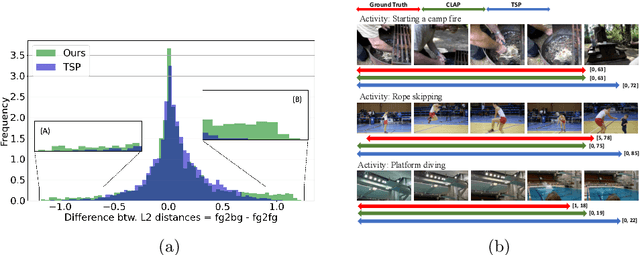
Long-form video understanding requires designing approaches that are able to temporally localize activities or language. End-to-end training for such tasks is limited by the compute device memory constraints and lack of temporal annotations at large-scale. These limitations can be addressed by pre-training on large datasets of temporally trimmed videos supervised by class annotations. Once the video encoder is pre-trained, it is common practice to freeze it during fine-tuning. Therefore, the video encoder does not learn temporal boundaries and unseen classes, causing a domain gap with respect to the downstream tasks. Moreover, using temporally trimmed videos prevents to capture the relations between different action categories and the background context in a video clip which results in limited generalization capacity. To address these limitations, we propose a novel post-pre-training approach without freezing the video encoder which leverages language. We introduce a masked contrastive learning loss to capture visio-linguistic relations between activities, background video clips and language in the form of captions. Our experiments show that the proposed approach improves the state-of-the-art on temporal action localization, few-shot temporal action localization, and video language grounding tasks.
Analysis and Optimization of Loss Functions for Multiclass, Top-k, and Multilabel Classification
Dec 12, 2016
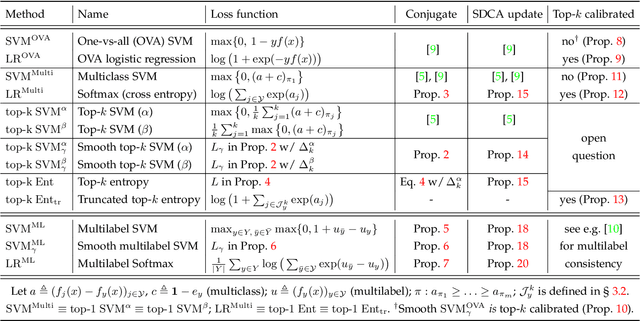
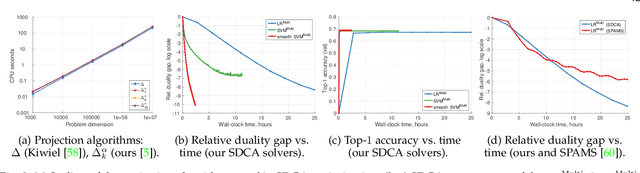

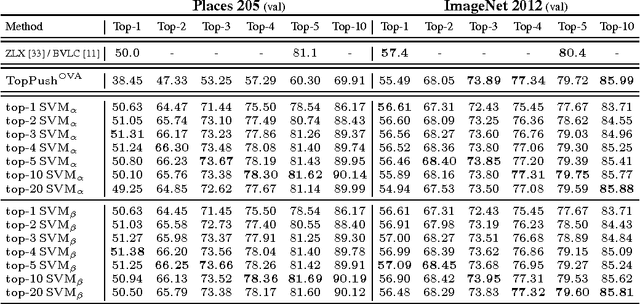
Top-k error is currently a popular performance measure on large scale image classification benchmarks such as ImageNet and Places. Despite its wide acceptance, our understanding of this metric is limited as most of the previous research is focused on its special case, the top-1 error. In this work, we explore two directions that shed more light on the top-k error. First, we provide an in-depth analysis of established and recently proposed single-label multiclass methods along with a detailed account of efficient optimization algorithms for them. Our results indicate that the softmax loss and the smooth multiclass SVM are surprisingly competitive in top-k error uniformly across all k, which can be explained by our analysis of multiclass top-k calibration. Further improvements for a specific k are possible with a number of proposed top-k loss functions. Second, we use the top-k methods to explore the transition from multiclass to multilabel learning. In particular, we find that it is possible to obtain effective multilabel classifiers on Pascal VOC using a single label per image for training, while the gap between multiclass and multilabel methods on MS COCO is more significant. Finally, our contribution of efficient algorithms for training with the considered top-k and multilabel loss functions is of independent interest.
Loss Functions for Top-k Error: Analysis and Insights
Apr 13, 2016

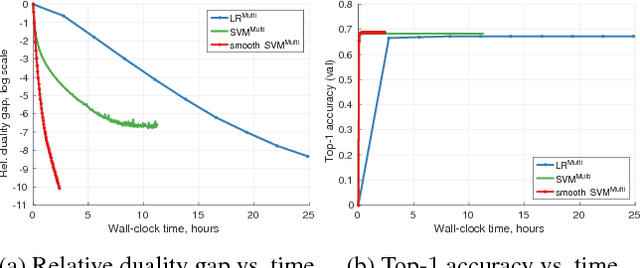

In order to push the performance on realistic computer vision tasks, the number of classes in modern benchmark datasets has significantly increased in recent years. This increase in the number of classes comes along with increased ambiguity between the class labels, raising the question if top-1 error is the right performance measure. In this paper, we provide an extensive comparison and evaluation of established multiclass methods comparing their top-k performance both from a practical as well as from a theoretical perspective. Moreover, we introduce novel top-k loss functions as modifications of the softmax and the multiclass SVM losses and provide efficient optimization schemes for them. In the experiments, we compare on various datasets all of the proposed and established methods for top-k error optimization. An interesting insight of this paper is that the softmax loss yields competitive top-k performance for all k simultaneously. For a specific top-k error, our new top-k losses lead typically to further improvements while being faster to train than the softmax.
Top-k Multiclass SVM
Nov 20, 2015


Class ambiguity is typical in image classification problems with a large number of classes. When classes are difficult to discriminate, it makes sense to allow k guesses and evaluate classifiers based on the top-k error instead of the standard zero-one loss. We propose top-k multiclass SVM as a direct method to optimize for top-k performance. Our generalization of the well-known multiclass SVM is based on a tight convex upper bound of the top-k error. We propose a fast optimization scheme based on an efficient projection onto the top-k simplex, which is of its own interest. Experiments on five datasets show consistent improvements in top-k accuracy compared to various baselines.
Efficient Output Kernel Learning for Multiple Tasks
Nov 18, 2015
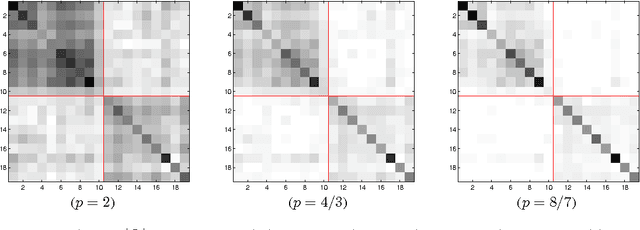

The paradigm of multi-task learning is that one can achieve better generalization by learning tasks jointly and thus exploiting the similarity between the tasks rather than learning them independently of each other. While previously the relationship between tasks had to be user-defined in the form of an output kernel, recent approaches jointly learn the tasks and the output kernel. As the output kernel is a positive semidefinite matrix, the resulting optimization problems are not scalable in the number of tasks as an eigendecomposition is required in each step. \mbox{Using} the theory of positive semidefinite kernels we show in this paper that for a certain class of regularizers on the output kernel, the constraint of being positive semidefinite can be dropped as it is automatically satisfied for the relaxed problem. This leads to an unconstrained dual problem which can be solved efficiently. Experiments on several multi-task and multi-class data sets illustrate the efficacy of our approach in terms of computational efficiency as well as generalization performance.
Learning Using Privileged Information: SVM+ and Weighted SVM
Mar 02, 2014



Prior knowledge can be used to improve predictive performance of learning algorithms or reduce the amount of data required for training. The same goal is pursued within the learning using privileged information paradigm which was recently introduced by Vapnik et al. and is aimed at utilizing additional information available only at training time -- a framework implemented by SVM+. We relate the privileged information to importance weighting and show that the prior knowledge expressible with privileged features can also be encoded by weights associated with every training example. We show that a weighted SVM can always replicate an SVM+ solution, while the converse is not true and we construct a counterexample highlighting the limitations of SVM+. Finally, we touch on the problem of choosing weights for weighted SVMs when privileged features are not available.
* 18 pages, 8 figures; integrated reviewer comments, improved typesetting