 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxicity Assessment in Preclinical Histopathology via Class-Aware Mahalanobis Distance for Known and Novel Anomalies
Feb 02, 2026Drug-induced toxicity remains a leading cause of failure in preclinical development and early clinical trials. Detecting adverse effects at an early stage is critical to reduce attrition and accelerate the development of safe medicines. Histopathological evaluation remains the gold standard for toxicity assessment, but it relies heavily on expert pathologists, creating a bottleneck for large-scale screening. To address this challenge, we introduce an AI-based anomaly detection framework for histopathological whole-slide images (WSIs) in rodent livers from toxicology studies. The system identifies healthy tissue and known pathologies (anomalies) for which training data is available. In addition, it can detect rare pathologies without training data as out-of-distribution (OOD) findings. We generate a novel dataset of pixelwise annotations of healthy tissue and known pathologies and use this data to fine-tune a pre-trained Vision Transformer (DINOv2) via Low-Rank Adaptation (LoRA) in order to do tissue segmentation. Finally, we extract features for OOD detection using the Mahalanobis distance. To better account for class-dependent variability in histological data, we propose the use of class-specific thresholds. We optimize the thresholds using the mean of the false negative and false positive rates, resulting in only 0.16\% of pathological tissue classified as healthy and 0.35\% of healthy tissue classified as pathological. Applied to mouse liver WSIs with known toxicological findings, the framework accurately detects anomalies, including rare OOD morphologies. This work demonstrates the potential of AI-driven histopathology to support preclinical workflows, reduce late-stage failures, and improve efficiency in drug development.
Understanding Benefits and Pitfalls of Current Methods for the Segmentation of Undersampled MRI Data
Aug 26, 2025MR imaging is a valuable diagnostic tool allowing to non-invasively visualize patient anatomy and pathology with high soft-tissue contrast. However, MRI acquisition is typically time-consuming, leading to patient discomfort and increased costs to the healthcare system. Recent years have seen substantial research effort into the development of methods that allow for accelerated MRI acquisition while still obtaining a reconstruction that appears similar to the fully-sampled MR image. However, for many applications a perfectly reconstructed MR image may not be necessary, particularly, when the primary goal is a downstream task such as segmentation. This has led to growing interest in methods that aim to perform segmentation directly on accelerated MRI data. Despite recent advances, existing methods have largely been developed in isolation, without direct comparison to one another, often using separate or private datasets, and lacking unified evaluation standards. To date, no high-quality, comprehensive comparison of these methods exists, and the optimal strategy for segmenting accelerated MR data remains unknown. This paper provides the first unified benchmark for the segmentation of undersampled MRI data comparing 7 approaches. A particular focus is placed on comparing \textit{one-stage approaches}, that combine reconstruction and segmentation into a unified model, with \textit{two-stage approaches}, that utilize established MRI reconstruction methods followed by a segmentation network. We test these methods on two MRI datasets that include multi-coil k-space data as well as a human-annotated segmentation ground-truth. We find that simple two-stage methods that consider data-consistency lead to the best segmentation scores, surpassing complex specialized methods that are developed specifically for this task.
Advancing Compositional Awareness in CLIP with Efficient Fine-Tuning
May 30, 2025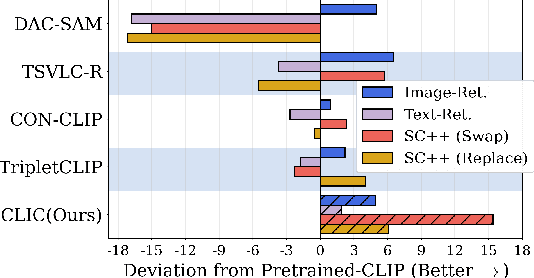
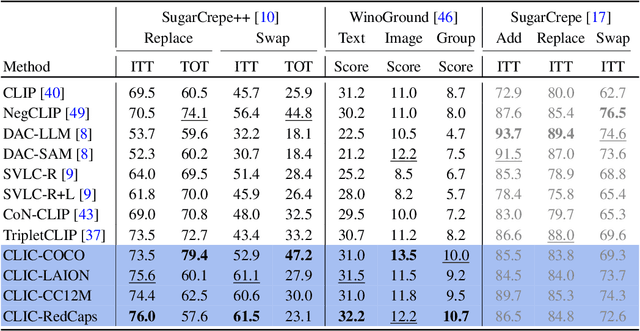

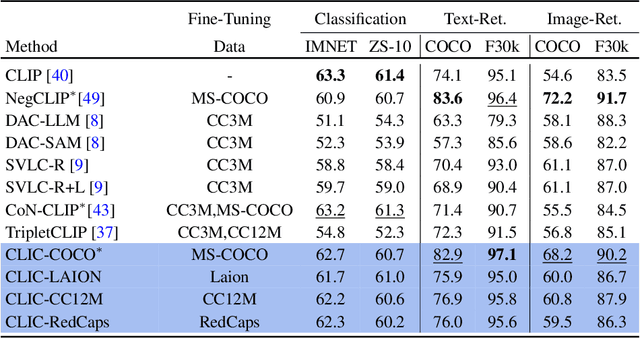
Vision-language models like CLIP have demonstrated remarkable zero-shot capabilities in classification and retrieval. However, these models often struggle with compositional reasoning - the ability to understand the relationships between concepts. A recent benchmark, SugarCrepe++, reveals that previous works on improving compositionality have mainly improved lexical sensitivity but neglected semantic understanding. In addition, downstream retrieval performance often deteriorates, although one would expect that improving compositionality should enhance retrieval. In this work, we introduce CLIC (Compositionally-aware Learning in CLIP), a fine-tuning method based on a novel training technique combining multiple images and their associated captions. CLIC improves compositionality across architectures as well as differently pre-trained CLIP models, both in terms of lexical and semantic understanding, and achieves consistent gains in retrieval performance. This even applies to the recent CLIPS, which achieves SOTA retrieval performance. Nevertheless, the short fine-tuning with CLIC leads to an improvement in retrieval and to the best compositional CLIP model on SugarCrepe++. All our models and code are available at https://clic-compositional-clip.github.io
Mahalanobis++: Improving OOD Detection via Feature Normalization
May 23, 2025Detecting out-of-distribution (OOD) examples is an important task for deploying reliable machine learning models in safety-critial applications. While post-hoc methods based on the Mahalanobis distance applied to pre-logit features are among the most effective for ImageNet-scale OOD detection, their performance varies significantly across models. We connect this inconsistency to strong variations in feature norms, indicating severe violations of the Gaussian assumption underlying the Mahalanobis distance estimation. We show that simple $\ell_2$-normalization of the features mitigates this problem effectively, aligning better with the premise of normally distributed data with shared covariance matrix. Extensive experiments on 44 models across diverse architectures and pretraining schemes show that $\ell_2$-normalization improves the conventional Mahalanobis distance-based approaches significantly and consistently, and outperforms other recently proposed OOD detection methods.
RePOPE: Impact of Annotation Errors on the POPE Benchmark
Apr 22, 2025



Since data annotation is costly, benchmark datasets often incorporate labels from established image datasets. In this work, we assess the impact of label errors in MSCOCO on the frequently used object hallucination benchmark POPE. We re-annotate the benchmark images and identify an imbalance in annotation errors across different subsets. Evaluating multiple models on the revised labels, which we denote as RePOPE, we observe notable shifts in model rankings, highlighting the impact of label quality. Code and data are available at https://github.com/YanNeu/RePOPE .
DASH: Detection and Assessment of Systematic Hallucinations of VLMs
Mar 30, 2025



Vision-language models (VLMs) are prone to object hallucinations, where they erroneously indicate the presenceof certain objects in an image. Existing benchmarks quantify hallucinations using relatively small, labeled datasets. However, this approach is i) insufficient to assess hallucinations that arise in open-world settings, where VLMs are widely used, and ii) inadequate for detecting systematic errors in VLMs. We propose DASH (Detection and Assessment of Systematic Hallucinations), an automatic, large-scale pipeline designed to identify systematic hallucinations of VLMs on real-world images in an open-world setting. A key component is DASH-OPT for image-based retrieval, where we optimize over the ''natural image manifold'' to generate images that mislead the VLM. The output of DASH consists of clusters of real and semantically similar images for which the VLM hallucinates an object. We apply DASH to PaliGemma and two LLaVA-NeXT models across 380 object classes and, in total, find more than 19k clusters with 950k images. We study the transfer of the identified systematic hallucinations to other VLMs and show that fine-tuning PaliGemma with the model-specific images obtained with DASH mitigates object hallucinations. Code and data are available at https://YanNeu.github.io/DASH.
Adversarially Robust CLIP Models Can Induce Better (Robust) Perceptual Metrics
Feb 17, 2025



Measuring perceptual similarity is a key tool in computer vision. In recent years perceptual metrics based on features extracted from neural networks with large and diverse training sets, e.g. CLIP, have become popular. At the same time, the metrics extracted from features of neural networks are not adversarially robust. In this paper we show that adversarially robust CLIP models, called R-CLIP$_\textrm{F}$, obtained by unsupervised adversarial fine-tuning induce a better and adversarially robust perceptual metric that outperforms existing metrics in a zero-shot setting, and further matches the performance of state-of-the-art metrics while being robust after fine-tuning. Moreover, our perceptual metric achieves strong performance on related tasks such as robust image-to-image retrieval, which becomes especially relevant when applied to "Not Safe for Work" (NSFW) content detection and dataset filtering. While standard perceptual metrics can be easily attacked by a small perturbation completely degrading NSFW detection, our robust perceptual metric maintains high accuracy under an attack while having similar performance for unperturbed images. Finally, perceptual metrics induced by robust CLIP models have higher interpretability: feature inversion can show which images are considered similar, while text inversion can find what images are associated to a given prompt. This also allows us to visualize the very rich visual concepts learned by a CLIP model, including memorized persons, paintings and complex queries.
Object-Focused Data Selection for Dense Prediction Tasks
Dec 13, 2024



Dense prediction tasks such as object detection and segmentation require high-quality labels at pixel level, which are costly to obtain. Recent advances in foundation models have enabled the generation of autolabels, which we find to be competitive but not yet sufficient to fully replace human annotations, especially for more complex datasets. Thus, we consider the challenge of selecting a representative subset of images for labeling from a large pool of unlabeled images under a constrained annotation budget. This task is further complicated by imbalanced class distributions, as rare classes are often underrepresented in selected subsets. We propose object-focused data selection (OFDS) which leverages object-level representations to ensure that the selected image subsets semantically cover the target classes, including rare ones. We validate OFDS on PASCAL VOC and Cityscapes for object detection and semantic segmentation tasks. Our experiments demonstrate that prior methods which employ image-level representations fail to consistently outperform random selection. In contrast, OFDS consistently achieves state-of-the-art performance with substantial improvements over all baselines in scenarios with imbalanced class distributions. Moreover, we demonstrate that pre-training with autolabels on the full datasets before fine-tuning on human-labeled subsets selected by OFDS further enhances the final performance.
Perturb and Recover: Fine-tuning for Effective Backdoor Removal from CLIP
Dec 01, 2024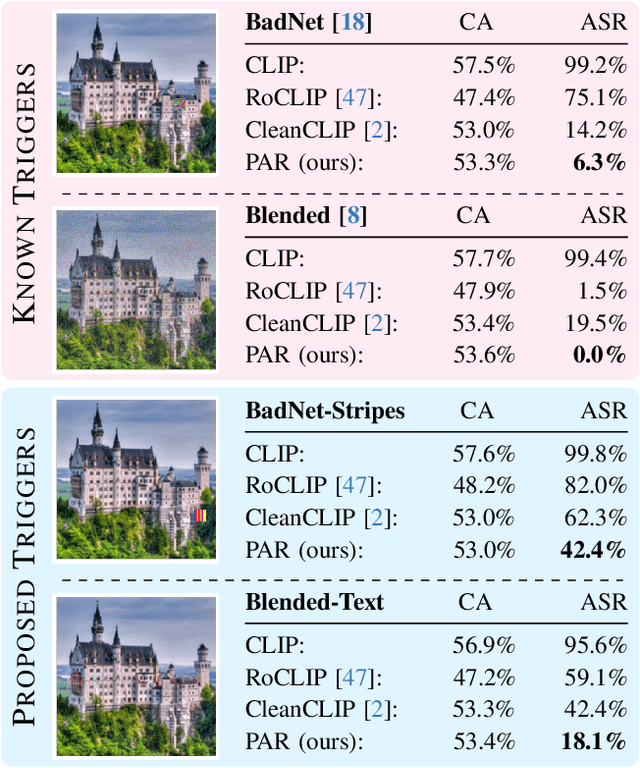
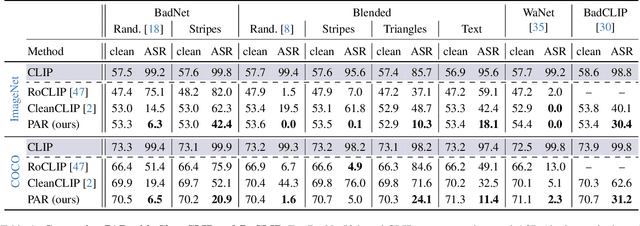

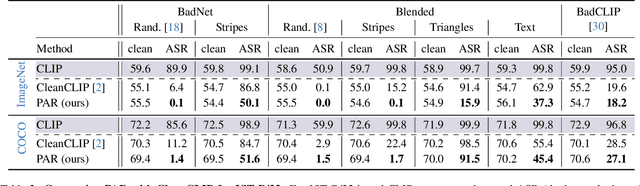
Vision-Language models like CLIP have been shown to be highly effective at linking visual perception and natural language understanding, enabling sophisticated image-text capabilities, including strong retrieval and zero-shot classification performance. Their widespread use, as well as the fact that CLIP models are trained on image-text pairs from the web, make them both a worthwhile and relatively easy target for backdoor attacks. As training foundational models, such as CLIP, from scratch is very expensive, this paper focuses on cleaning potentially poisoned models via fine-tuning. We first show that existing cleaning techniques are not effective against simple structured triggers used in Blended or BadNet backdoor attacks, exposing a critical vulnerability for potential real-world deployment of these models. Then, we introduce PAR, Perturb and Recover, a surprisingly simple yet effective mechanism to remove backdoors from CLIP models. Through extensive experiments across different encoders and types of backdoor attacks, we show that PAR achieves high backdoor removal rate while preserving good standard performance. Finally, we illustrate that our approach is effective even only with synthetic text-image pairs, i.e. without access to real training data. The code and models are available at \href{https://github.com/nmndeep/PerturbAndRecover}{https://github.com/nmndeep/PerturbAndRecover}.
A Realistic Threat Model for Large Language Model Jailbreaks
Oct 21, 2024A plethora of jailbreaking attacks have been proposed to obtain harmful responses from safety-tuned LLMs. In their original settings, these methods all largely succeed in coercing the target output, but their attacks vary substantially in fluency and computational effort. In this work, we propose a unified threat model for the principled comparison of these methods. Our threat model combines constraints in perplexity, measuring how far a jailbreak deviates from natural text, and computational budget, in total FLOPs. For the former, we build an N-gram model on 1T tokens, which, in contrast to model-based perplexity, allows for an LLM-agnostic and inherently interpretable evaluation. We adapt popular attacks to this new, realistic threat model, with which we, for the first time, benchmark these attacks on equal footing. After a rigorous comparison, we not only find attack success rates against safety-tuned modern models to be lower than previously presented but also find that attacks based on discrete optimization significantly outperform recent LLM-based attacks. Being inherently interpretable, our threat model allows for a comprehensive analysis and comparison of jailbreak attacks. We find that effective attacks exploit and abuse infrequent N-grams, either selecting N-grams absent from real-world text or rare ones, e.g. specific to code datasets.