 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN-3: Technical Report
May 13, 2026Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
A Family of LLMs Liberated from Static Vocabularies
Mar 16, 2026Tokenization is a central component of natural language processing in current large language models (LLMs), enabling models to convert raw text into processable units. Although learned tokenizers are widely adopted, they exhibit notable limitations, including their large, fixed vocabulary sizes and poor adaptability to new domains or languages. We present a family of models with up to 70 billion parameters based on the hierarchical autoregressive transformer (HAT) architecture. In HAT, an encoder transformer aggregates bytes into word embeddings and then feeds them to the backbone, a classical autoregressive transformer. The outputs of the backbone are then cross-attended by the decoder and converted back into bytes. We show that we can reuse available pre-trained models by converting the Llama 3.1 8B and 70B models into the HAT architecture: Llama-3.1-8B-TFree-HAT and Llama-3.1-70B-TFree-HAT are byte-level models whose encoder and decoder are trained from scratch, but where we adapt the pre-trained Llama backbone, i.e., the transformer blocks with the embedding matrix and head removed, to handle word embeddings instead of the original tokens. We also provide a 7B HAT model, Llama-TFree-HAT-Pretrained, trained entirely from scratch on nearly 4 trillion words. The HAT architecture improves text compression by reducing the number of required sequence positions and enhances robustness to intra-word variations, e.g., spelling differences. Through pre-training, as well as subsequent supervised fine-tuning and direct preference optimization in English and German, we show strong proficiency in both languages, improving on the original Llama 3.1 in most benchmarks. We release our models (including 200 pre-training checkpoints) on Hugging Face.
SOMBRERO: Measuring and Steering Boundary Placement in End-to-End Hierarchical Sequence Models
Jan 30, 2026Hierarchical sequence models replace fixed tokenization with learned segmentations that compress long byte sequences for efficient autoregressive modeling. While recent end-to-end methods can learn meaningful boundaries from the language-modeling objective alone, it remains difficult to quantitatively assess and systematically steer where compute is spent. We introduce a router-agnostic metric of boundary quality, boundary enrichment B, which measures how strongly chunk starts concentrate on positions with high next-byte surprisal. Guided by this metric, we propose Sombrero, which steers boundary placement toward predictive difficulty via a confidence-alignment boundary loss and stabilizes boundary learning by applying confidence-weighted smoothing at the input level rather than on realized chunks. On 1B scale, across UTF-8 corpora covering English and German text as well as code and mathematical content, Sombrero improves the accuracy-efficiency trade-off and yields boundaries that more consistently align compute with hard-to-predict positions.
Depth-Recurrent Attention Mixtures: Giving Latent Reasoning the Attention it Deserves
Jan 29, 2026Depth-recurrence facilitates latent reasoning by sharing parameters across depths. However, prior work lacks combined FLOP-, parameter-, and memory-matched baselines, underutilizes depth-recurrence due to partially fixed layer stacks, and ignores the bottleneck of constant hidden-sizes that restricts many-step latent reasoning. To address this, we introduce a modular framework of depth-recurrent attention mixtures (Dreamer), combining sequence attention, depth attention, and sparse expert attention. It alleviates the hidden-size bottleneck through attention along depth, decouples scaling dimensions, and allows depth-recurrent models to scale efficiently and effectively. Across language reasoning benchmarks, our models require 2 to 8x fewer training tokens for the same accuracy as FLOP-, parameter-, and memory-matched SOTA, and outperform ca. 2x larger SOTA models with the same training tokens. We further present insights into knowledge usage across depths, e.g., showing 2 to 11x larger expert selection diversity than SOTA MoEs.
Object-Focused Data Selection for Dense Prediction Tasks
Dec 13, 2024



Dense prediction tasks such as object detection and segmentation require high-quality labels at pixel level, which are costly to obtain. Recent advances in foundation models have enabled the generation of autolabels, which we find to be competitive but not yet sufficient to fully replace human annotations, especially for more complex datasets. Thus, we consider the challenge of selecting a representative subset of images for labeling from a large pool of unlabeled images under a constrained annotation budget. This task is further complicated by imbalanced class distributions, as rare classes are often underrepresented in selected subsets. We propose object-focused data selection (OFDS) which leverages object-level representations to ensure that the selected image subsets semantically cover the target classes, including rare ones. We validate OFDS on PASCAL VOC and Cityscapes for object detection and semantic segmentation tasks. Our experiments demonstrate that prior methods which employ image-level representations fail to consistently outperform random selection. In contrast, OFDS consistently achieves state-of-the-art performance with substantial improvements over all baselines in scenarios with imbalanced class distributions. Moreover, we demonstrate that pre-training with autolabels on the full datasets before fine-tuning on human-labeled subsets selected by OFDS further enhances the final performance.
Retinex-Diffusion: On Controlling Illumination Conditions in Diffusion Models via Retinex Theory
Jul 29, 2024This paper introduces a novel approach to illumination manipulation in diffusion models, addressing the gap in conditional image generation with a focus on lighting conditions. We conceptualize the diffusion model as a black-box image render and strategically decompose its energy function in alignment with the image formation model. Our method effectively separates and controls illumination-related properties during the generative process. It generates images with realistic illumination effects, including cast shadow, soft shadow, and inter-reflections. Remarkably, it achieves this without the necessity for learning intrinsic decomposition, finding directions in latent space, or undergoing additional training with new datasets.
Label-free Neural Semantic Image Synthesis
Jul 01, 2024



Recent work has shown great progress in integrating spatial conditioning to control large, pre-trained text-to-image diffusion models. Despite these advances, existing methods describe the spatial image content using hand-crafted conditioning inputs, which are either semantically ambiguous (e.g., edges) or require expensive manual annotations (e.g., semantic segmentation). To address these limitations, we propose a new label-free way of conditioning diffusion models to enable fine-grained spatial control. We introduce the concept of neural semantic image synthesis, which uses neural layouts extracted from pre-trained foundation models as conditioning. Neural layouts are advantageous as they provide rich descriptions of the desired image, containing both semantics and detailed geometry of the scene. We experimentally show that images synthesized via neural semantic image synthesis achieve similar or superior pixel-level alignment of semantic classes compared to those created using expensive semantic label maps. At the same time, they capture better semantics, instance separation, and object orientation than other label-free conditioning options, such as edges or depth. Moreover, we show that images generated by neural layout conditioning can effectively augment real data for training various perception tasks.
Zero-Shot Distillation for Image Encoders: How to Make Effective Use of Synthetic Data
Apr 25, 2024



Multi-modal foundation models such as CLIP have showcased impressive zero-shot capabilities. However, their applicability in resource-constrained environments is limited due to their large number of parameters and high inference time. While existing approaches have scaled down the entire CLIP architecture, we focus on training smaller variants of the image encoder, which suffices for efficient zero-shot classification. The use of synthetic data has shown promise in distilling representations from larger teachers, resulting in strong few-shot and linear probe performance. However, we find that this approach surprisingly fails in true zero-shot settings when using contrastive losses. We identify the exploitation of spurious features as being responsible for poor generalization between synthetic and real data. However, by using the image feature-based L2 distillation loss, we mitigate these problems and train students that achieve zero-shot performance which on four domain-specific datasets is on-par with a ViT-B/32 teacher model trained on DataCompXL, while featuring up to 92% fewer parameters.
Identification of Fine-grained Systematic Errors via Controlled Scene Generation
Apr 10, 2024


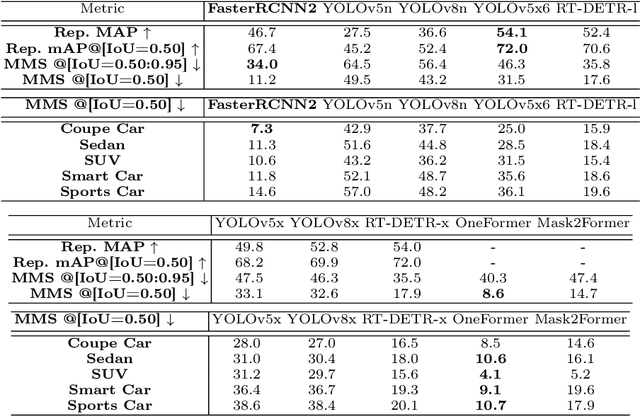
Many safety-critical applications, especially in autonomous driving, require reliable object detectors. They can be very effectively assisted by a method to search for and identify potential failures and systematic errors before these detectors are deployed. Systematic errors are characterized by combinations of attributes such as object location, scale, orientation, and color, as well as the composition of their respective backgrounds. To identify them, one must rely on something other than real images from a test set because they do not account for very rare but possible combinations of attributes. To overcome this limitation, we propose a pipeline for generating realistic synthetic scenes with fine-grained control, allowing the creation of complex scenes with multiple objects. Our approach, BEV2EGO, allows for a realistic generation of the complete scene with road-contingent control that maps 2D bird's-eye view (BEV) scene configurations to a first-person view (EGO). In addition, we propose a benchmark for controlled scene generation to select the most appropriate generative outpainting model for BEV2EGO. We further use it to perform a systematic analysis of multiple state-of-the-art object detection models and discover differences between them.
AutoCLIP: Auto-tuning Zero-Shot Classifiers for Vision-Language Models
Sep 29, 2023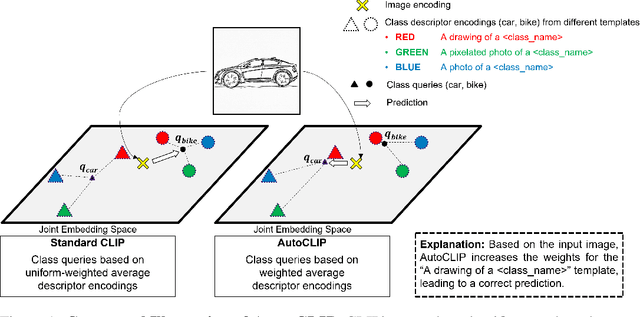
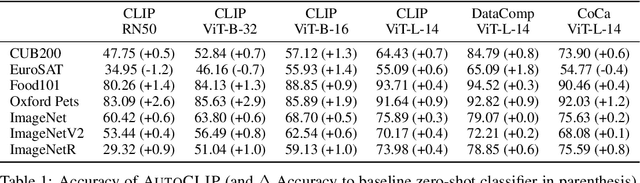
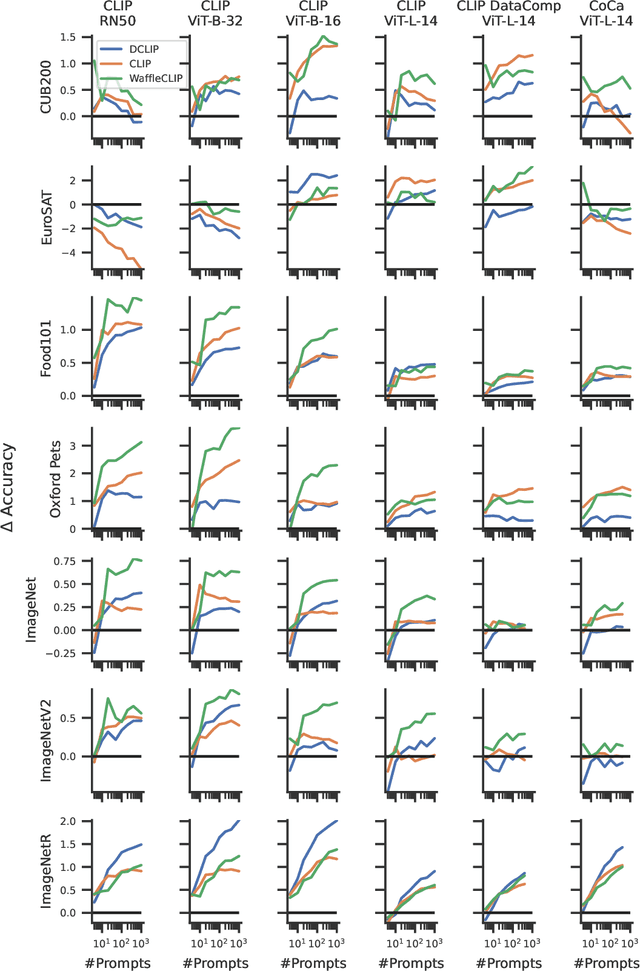
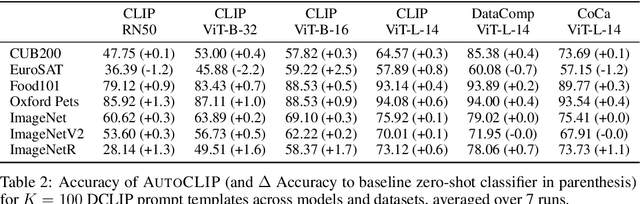
Classifiers built upon vision-language models such as CLIP have shown remarkable zero-shot performance across a broad range of image classification tasks. Prior work has studied different ways of automatically creating descriptor sets for every class based on prompt templates, ranging from manually engineered templates over templates obtained from a large language model to templates built from random words and characters. Up until now, deriving zero-shot classifiers from the respective encoded class descriptors has remained nearly unchanged, i.e., classify to the class that maximizes cosine similarity between its averaged encoded class descriptors and the image encoding. However, weighing all class descriptors equally can be suboptimal when certain descriptors match visual clues on a given image better than others. In this work, we propose AutoCLIP, a method for auto-tuning zero-shot classifiers. AutoCLIP tunes per-image weights to each prompt template at inference time, based on statistics of class descriptor-image similarities. AutoCLIP is fully unsupervised, has very low computational overhead, and can be easily implemented in few lines of code. We show that AutoCLIP outperforms baselines across a broad range of vision-language models, datasets, and prompt templates consistently and by up to 3 percent point accuracy.