 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentification of Systematic Errors of Image Classifiers on Rare Subgroups
Mar 09, 2023



Despite excellent average-case performance of many image classifiers, their performance can substantially deteriorate on semantically coherent subgroups of the data that were under-represented in the training data. These systematic errors can impact both fairness for demographic minority groups as well as robustness and safety under domain shift. A major challenge is to identify such subgroups with subpar performance when the subgroups are not annotated and their occurrence is very rare. We leverage recent advances in text-to-image models and search in the space of textual descriptions of subgroups ("prompts") for subgroups where the target model has low performance on the prompt-conditioned synthesized data. To tackle the exponentially growing number of subgroups, we employ combinatorial testing. We denote this procedure as PromptAttack as it can be interpreted as an adversarial attack in a prompt space. We study subgroup coverage and identifiability with PromptAttack in a controlled setting and find that it identifies systematic errors with high accuracy. Thereupon, we apply PromptAttack to ImageNet classifiers and identify novel systematic errors on rare subgroups.
Certified Defences Against Adversarial Patch Attacks on Semantic Segmentation
Sep 13, 2022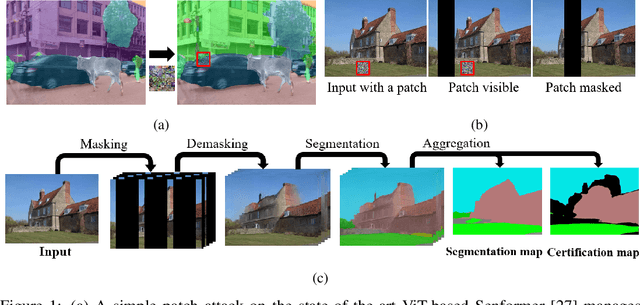
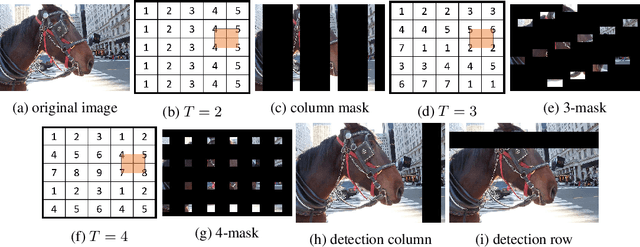
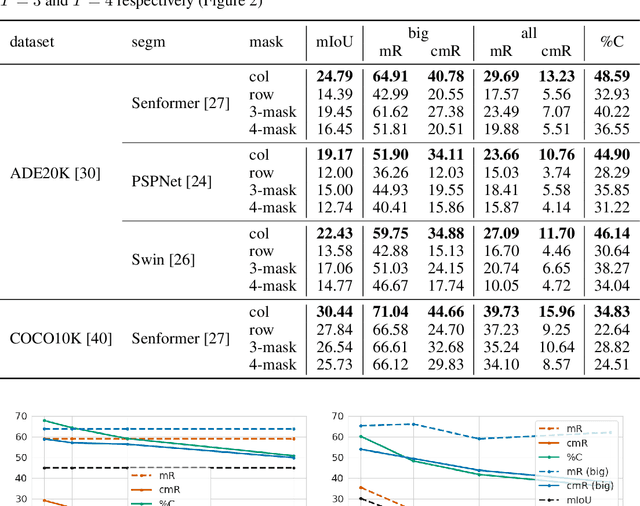

Adversarial patch attacks are an emerging security threat for real world deep learning applications. We present Demasked Smoothing, the first approach (up to our knowledge) to certify the robustness of semantic segmentation models against this threat model. Previous work on certifiably defending against patch attacks has mostly focused on image classification task and often required changes in the model architecture and additional training which is undesirable and computationally expensive. In Demasked Smoothing, any segmentation model can be applied without particular training, fine-tuning, or restriction of the architecture. Using different masking strategies, Demasked Smoothing can be applied both for certified detection and certified recovery. In extensive experiments we show that Demasked Smoothing can on average certify 64% of the pixel predictions for a 1% patch in the detection task and 48% against a 0.5% patch for the recovery task on the ADE20K dataset.