 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMA-Nesterov: Stabilizing Nesterov's Lookahead for Accelerated Deep Learning Optimization
May 25, 2026Lookahead-based acceleration methods, such as Nesterov's momentum, are widely used in optimization, but they often become unreliable in deep learning training mainly due to stochastic gradient noise and non-convex loss landscapes. In particular, standard lookahead relies on short-horizon update signals (e.g., differences between consecutive iterates), which are inherently noisy and can lead to unstable extrapolation directions. This work revisits Nesterov's acceleration from a trajectory perspective and argues that effective acceleration in deep learning should harness the low-frequency trends of optimization trajectories rather than extrapolating noisy one-step updates. Leveraging this insight, we propose EMA-Nesterov, a simple modification that replaces the standard Nesterov's lookahead direction with an exponential moving average (EMA) of parameter updates. This yields a stabilized lookahead direction that captures and harnesses the evolving trend of the training trajectory through a low-pass filter, while remaining adaptive to progressive changes via the geometric weighting structure of EMA. We show that EMA-Nesterov retains a theoretical accelerated convergence rate in convex problems that is analogous to Nesterov's accelerated gradient method. Furthermore, we provide empirical evidence on language model pre-training to verify that EMA-Nesterov is broadly applicable across a range of fine-tuned base optimizers, including Adam, SOAP, Muon, as well as complex optimizers that achieve state-of-the-art performance on optimization benchmarks (NanoGPT). Compared to prior lookahead methods, EMA-Nesterov achieves better performance by avoiding the instability of short-horizon lookahead and the non-adaptivity of long-horizon lookahead.
A Realistic Threat Model for Large Language Model Jailbreaks
Oct 21, 2024A plethora of jailbreaking attacks have been proposed to obtain harmful responses from safety-tuned LLMs. In their original settings, these methods all largely succeed in coercing the target output, but their attacks vary substantially in fluency and computational effort. In this work, we propose a unified threat model for the principled comparison of these methods. Our threat model combines constraints in perplexity, measuring how far a jailbreak deviates from natural text, and computational budget, in total FLOPs. For the former, we build an N-gram model on 1T tokens, which, in contrast to model-based perplexity, allows for an LLM-agnostic and inherently interpretable evaluation. We adapt popular attacks to this new, realistic threat model, with which we, for the first time, benchmark these attacks on equal footing. After a rigorous comparison, we not only find attack success rates against safety-tuned modern models to be lower than previously presented but also find that attacks based on discrete optimization significantly outperform recent LLM-based attacks. Being inherently interpretable, our threat model allows for a comprehensive analysis and comparison of jailbreak attacks. We find that effective attacks exploit and abuse infrequent N-grams, either selecting N-grams absent from real-world text or rare ones, e.g. specific to code datasets.
How much can we forget about Data Contamination?
Oct 04, 2024
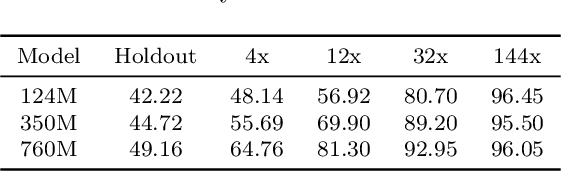
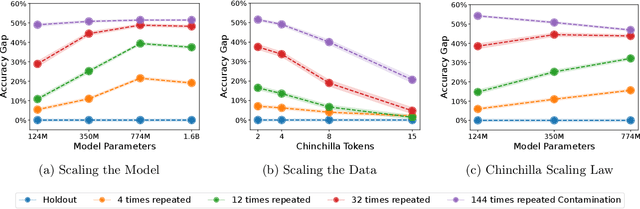
The leakage of benchmark data into the training data has emerged as a significant challenge for evaluating the capabilities of large language models (LLMs). In this work, we use experimental evidence and theoretical estimates to challenge the common assumption that small-scale contamination renders benchmark evaluations invalid. First, we experimentally quantify the magnitude of benchmark overfitting based on scaling along three dimensions: The number of model parameters (up to 1.6B), the number of times an example is seen (up to 144), and the number of training tokens (up to 40B). We find that if model and data follow the Chinchilla scaling laws, minor contamination indeed leads to overfitting. At the same time, even 144 times of contamination can be forgotten if the training data is scaled beyond five times Chinchilla, a regime characteristic of many modern LLMs. We then derive a simple theory of example forgetting via cumulative weight decay. It allows us to bound the number of gradient steps required to forget past data for any training run where we know the hyperparameters of AdamW. This indicates that many LLMs, including Llama 3, have forgotten the data seen at the beginning of training. Experimentally, we demonstrate that forgetting occurs faster than what is predicted by our bounds. Taken together, our results suggest that moderate amounts of contamination can be forgotten at the end of realistically scaled training runs.
Identification of Fine-grained Systematic Errors via Controlled Scene Generation
Apr 10, 2024


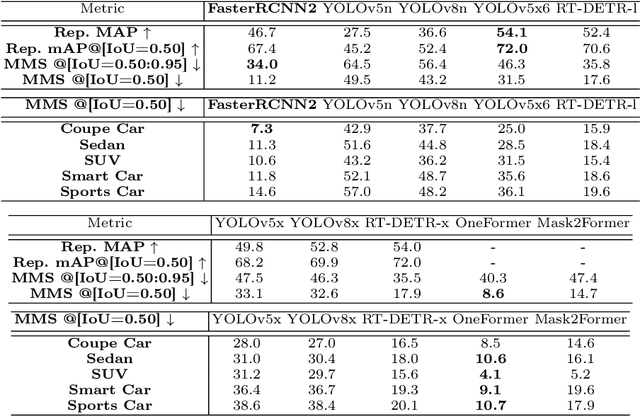
Many safety-critical applications, especially in autonomous driving, require reliable object detectors. They can be very effectively assisted by a method to search for and identify potential failures and systematic errors before these detectors are deployed. Systematic errors are characterized by combinations of attributes such as object location, scale, orientation, and color, as well as the composition of their respective backgrounds. To identify them, one must rely on something other than real images from a test set because they do not account for very rare but possible combinations of attributes. To overcome this limitation, we propose a pipeline for generating realistic synthetic scenes with fine-grained control, allowing the creation of complex scenes with multiple objects. Our approach, BEV2EGO, allows for a realistic generation of the complete scene with road-contingent control that maps 2D bird's-eye view (BEV) scene configurations to a first-person view (EGO). In addition, we propose a benchmark for controlled scene generation to select the most appropriate generative outpainting model for BEV2EGO. We further use it to perform a systematic analysis of multiple state-of-the-art object detection models and discover differences between them.
Generating Realistic Counterfactuals for Retinal Fundus and OCT Images using Diffusion Models
Dec 04, 2023Counterfactual reasoning is often used in clinical settings to explain decisions or weigh alternatives. Therefore, for imaging based specialties such as ophthalmology, it would be beneficial to be able to create counterfactual images, illustrating answers to questions like "If the subject had had diabetic retinopathy, how would the fundus image have looked?". Here, we demonstrate that using a diffusion model in combination with an adversarially robust classifier trained on retinal disease classification tasks enables the generation of highly realistic counterfactuals of retinal fundus images and optical coherence tomography (OCT) B-scans. The key to the realism of counterfactuals is that these classifiers encode salient features indicative for each disease class and can steer the diffusion model to depict disease signs or remove disease-related lesions in a realistic way. In a user study, domain experts also found the counterfactuals generated using our method significantly more realistic than counterfactuals generated from a previous method, and even indistinguishable from real images.
Identifying Systematic Errors in Object Detectors with the SCROD Pipeline
Sep 23, 2023



The identification and removal of systematic errors in object detectors can be a prerequisite for their deployment in safety-critical applications like automated driving and robotics. Such systematic errors can for instance occur under very specific object poses (location, scale, orientation), object colors/textures, and backgrounds. Real images alone are unlikely to cover all relevant combinations. We overcome this limitation by generating synthetic images with fine-granular control. While generating synthetic images with physical simulators and hand-designed 3D assets allows fine-grained control over generated images, this approach is resource-intensive and has limited scalability. In contrast, using generative models is more scalable but less reliable in terms of fine-grained control. In this paper, we propose a novel framework that combines the strengths of both approaches. Our meticulously designed pipeline along with custom models enables us to generate street scenes with fine-grained control in a fully automated and scalable manner. Moreover, our framework introduces an evaluation setting that can serve as a benchmark for similar pipelines. This evaluation setting will contribute to advancing the field and promoting standardized testing procedures.
Identification of Systematic Errors of Image Classifiers on Rare Subgroups
Mar 09, 2023



Despite excellent average-case performance of many image classifiers, their performance can substantially deteriorate on semantically coherent subgroups of the data that were under-represented in the training data. These systematic errors can impact both fairness for demographic minority groups as well as robustness and safety under domain shift. A major challenge is to identify such subgroups with subpar performance when the subgroups are not annotated and their occurrence is very rare. We leverage recent advances in text-to-image models and search in the space of textual descriptions of subgroups ("prompts") for subgroups where the target model has low performance on the prompt-conditioned synthesized data. To tackle the exponentially growing number of subgroups, we employ combinatorial testing. We denote this procedure as PromptAttack as it can be interpreted as an adversarial attack in a prompt space. We study subgroup coverage and identifiability with PromptAttack in a controlled setting and find that it identifies systematic errors with high accuracy. Thereupon, we apply PromptAttack to ImageNet classifiers and identify novel systematic errors on rare subgroups.
Spurious Features Everywhere -- Large-Scale Detection of Harmful Spurious Features in ImageNet
Dec 09, 2022Benchmark performance of deep learning classifiers alone is not a reliable predictor for the performance of a deployed model. In particular, if the image classifier has picked up spurious features in the training data, its predictions can fail in unexpected ways. In this paper, we develop a framework that allows us to systematically identify spurious features in large datasets like ImageNet. It is based on our neural PCA components and their visualization. Previous work on spurious features of image classifiers often operates in toy settings or requires costly pixel-wise annotations. In contrast, we validate our results by checking that presence of the harmful spurious feature of a class is sufficient to trigger the prediction of that class. We introduce a novel dataset "Spurious ImageNet" and check how much existing classifiers rely on spurious features.
Sparse Visual Counterfactual Explanations in Image Space
May 16, 2022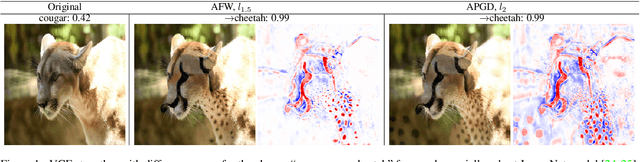
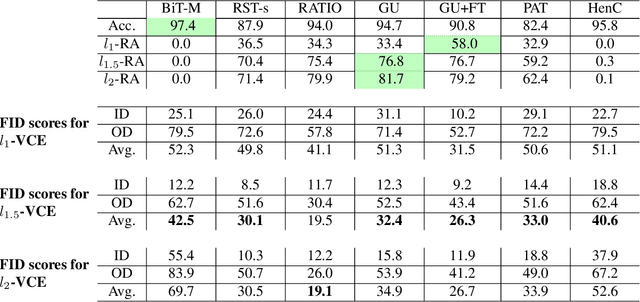


Visual counterfactual explanations (VCEs) in image space are an important tool to understand decisions of image classifiers as they show under which changes of the image the decision of the classifier would change. Their generation in image space is challenging and requires robust models due to the problem of adversarial examples. Existing techniques to generate VCEs in image space suffer from spurious changes in the background. Our novel perturbation model for VCEs together with its efficient optimization via our novel Auto-Frank-Wolfe scheme yields sparse VCEs which are significantly more object-centric. Moreover, we show that VCEs can be used to detect undesired behavior of ImageNet classifiers due to spurious features in the ImageNet dataset and discuss how estimates of the data-generating distribution can be used for VCEs.