 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Realistic Counterfactuals for Retinal Fundus and OCT Images using Diffusion Models
Dec 04, 2023Counterfactual reasoning is often used in clinical settings to explain decisions or weigh alternatives. Therefore, for imaging based specialties such as ophthalmology, it would be beneficial to be able to create counterfactual images, illustrating answers to questions like "If the subject had had diabetic retinopathy, how would the fundus image have looked?". Here, we demonstrate that using a diffusion model in combination with an adversarially robust classifier trained on retinal disease classification tasks enables the generation of highly realistic counterfactuals of retinal fundus images and optical coherence tomography (OCT) B-scans. The key to the realism of counterfactuals is that these classifiers encode salient features indicative for each disease class and can steer the diffusion model to depict disease signs or remove disease-related lesions in a realistic way. In a user study, domain experts also found the counterfactuals generated using our method significantly more realistic than counterfactuals generated from a previous method, and even indistinguishable from real images.
Maximal adversarial perturbations for obfuscation: Hiding certain attributes while preserving rest
Sep 27, 2019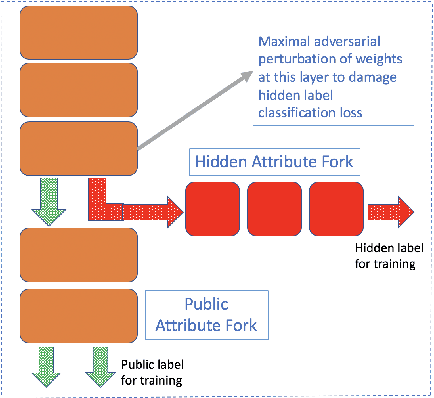
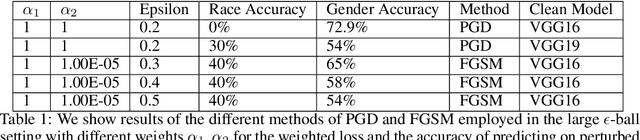
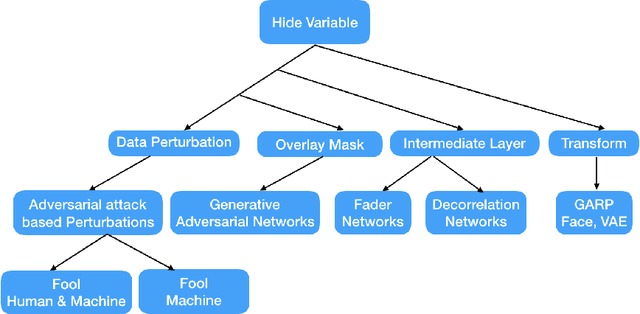

In this paper we investigate the usage of adversarial perturbations for the purpose of privacy from human perception and model (machine) based detection. We employ adversarial perturbations for obfuscating certain variables in raw data while preserving the rest. Current adversarial perturbation methods are used for data poisoning with minimal perturbations of the raw data such that the machine learning model's performance is adversely impacted while the human vision cannot perceive the difference in the poisoned dataset due to minimal nature of perturbations. We instead apply relatively maximal perturbations of raw data to conditionally damage model's classification of one attribute while preserving the model performance over another attribute. In addition, the maximal nature of perturbation helps adversely impact human perception in classifying hidden attribute apart from impacting model performance. We validate our result qualitatively by showing the obfuscated dataset and quantitatively by showing the inability of models trained on clean data to predict the hidden attribute from the perturbed dataset while being able to predict the rest of attributes.