 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMES: Approximate Multi-modal Enterprise Search via Late Interaction Retrieval
Mar 13, 2026We present AMES (Approximate Multimodal Enterprise Search), a unified multimodal late interaction retrieval architecture which is backend agnostic. AMES demonstrates that fine-grained multimodal late interaction retrieval can be deployed within a production grade enterprise search engine without architectural redesign. Text tokens, image patches, and video frames are embedded into a shared representation space using multi-vector encoders, enabling cross-modal retrieval without modality specific retrieval logic. AMES employs a two-stage pipeline: parallel token level ANN search with per document Top-M MaxSim approximation, followed by accelerator optimized Exact MaxSim re-ranking. Experiments on the ViDoRe V3 benchmark show that AMES achieves competitive ranking performance within a scalable, production ready Solr based system.
VAST: Vascular Flow Analysis and Segmentation for Intracranial 4D Flow MRI
Jan 19, 2026Four-dimensional (4D) Flow MRI can noninvasively measure cerebrovascular hemodynamics but remains underused clinically because current workflows rely on manual vessel segmentation and yield velocity fields sensitive to noise, artifacts, and phase aliasing. We present VAST (Vascular Flow Analysis and Segmentation), an automated, unsupervised pipeline for intracranial 4D Flow MRI that couples vessel segmentation with physics-informed velocity reconstruction. VAST derives vessel masks directly from complex 4D Flow data by iteratively fusing magnitude- and phase-based background statistics. It then reconstructs velocities via continuity-constrained phase unwrapping, outlier correction, and low-rank denoising to reduce noise and aliasing while promoting mass-consistent flow fields, with processing completing in minutes per case on a standard CPU. We validate VAST on synthetic data from an internal carotid artery aneurysm model across SNR = 2-20 and severe phase wrapping (up to five-fold), on in vitro Poiseuille flow, and on an in vivo internal carotid aneurysm dataset. In synthetic benchmarks, VAST maintains near quarter-voxel surface accuracy and reduces velocity root-mean-square error by up to fourfold under the most degraded conditions. In vitro, it segments the channel within approximately half a voxel of expert annotations and reduces velocity error by 39% (unwrapped) and 77% (aliased). In vivo, VAST closely matches expert time-of-flight masks and lowers divergence residuals by about 30%, indicating a more self-consistent intracranial flow field. By automating processing and enforcing basic flow physics, VAST helps move intracranial 4D Flow MRI toward routine quantitative use in cerebrovascular assessment.
Upgrade or Switch: Do We Need a New Registry Architecture for the Internet of AI Agents?
Jun 13, 2025The emerging Internet of AI Agents challenges existing web infrastructure designed for human-scale, reactive interactions. Unlike traditional web resources, autonomous AI agents initiate actions, maintain persistent state, spawn sub-agents, and negotiate directly with peers: demanding millisecond-level discovery, instant credential revocation, and cryptographic behavioral proofs that exceed current DNS/PKI capabilities. This paper analyzes whether to upgrade existing infrastructure or implement purpose-built registry architectures for autonomous agents. We identify critical failure points: DNS propagation (24-48 hours vs. required milliseconds), certificate revocation unable to scale to trillions of entities, and IPv4/IPv6 addressing inadequate for agent-scale routing. We evaluate three approaches: (1) Upgrade paths, (2) Switch options, (3) Hybrid registries. Drawing parallels to dialup-to-broadband transitions, we find that agent requirements constitute qualitative, and not incremental, changes. While upgrades offer compatibility and faster deployment, clean-slate solutions provide better performance but require longer for adoption. Our analysis suggests hybrid approaches will emerge, with centralized registries for critical agents and federated meshes for specialized use cases.
Uncovering Semantics and Topics Utilized by Threat Actors to Deliver Malicious Attachments and URLs
Jul 11, 2024



Recent threat reports highlight that email remains the top vector for delivering malware to endpoints. Despite these statistics, detecting malicious email attachments and URLs often neglects semantic cues linguistic features and contextual clues. Our study employs BERTopic unsupervised topic modeling to identify common semantics and themes embedded in email to deliver malicious attachments and call-to-action URLs. We preprocess emails by extracting and sanitizing content and employ multilingual embedding models like BGE-M3 for dense representations, which clustering algorithms(HDBSCAN and OPTICS) use to group emails by semantic similarity. Phi3-Mini-4K-Instruct facilitates semantic and hLDA aid in thematic analysis to understand threat actor patterns. Our research will evaluate and compare different clustering algorithms on topic quantity, coherence, and diversity metrics, concluding with insights into the semantics and topics commonly used by threat actors to deliver malicious attachments and URLs, a significant contribution to the field of threat detection.
Dealing Doubt: Unveiling Threat Models in Gradient Inversion Attacks under Federated Learning, A Survey and Taxonomy
May 16, 2024
Federated Learning (FL) has emerged as a leading paradigm for decentralized, privacy preserving machine learning training. However, recent research on gradient inversion attacks (GIAs) have shown that gradient updates in FL can leak information on private training samples. While existing surveys on GIAs have focused on the honest-but-curious server threat model, there is a dearth of research categorizing attacks under the realistic and far more privacy-infringing cases of malicious servers and clients. In this paper, we present a survey and novel taxonomy of GIAs that emphasize FL threat models, particularly that of malicious servers and clients. We first formally define GIAs and contrast conventional attacks with the malicious attacker. We then summarize existing honest-but-curious attack strategies, corresponding defenses, and evaluation metrics. Critically, we dive into attacks with malicious servers and clients to highlight how they break existing FL defenses, focusing specifically on reconstruction methods, target model architectures, target data, and evaluation metrics. Lastly, we discuss open problems and future research directions.
DecentNeRFs: Decentralized Neural Radiance Fields from Crowdsourced Images
Mar 28, 2024Neural radiance fields (NeRFs) show potential for transforming images captured worldwide into immersive 3D visual experiences. However, most of this captured visual data remains siloed in our camera rolls as these images contain personal details. Even if made public, the problem of learning 3D representations of billions of scenes captured daily in a centralized manner is computationally intractable. Our approach, DecentNeRF, is the first attempt at decentralized, crowd-sourced NeRFs that require $\sim 10^4\times$ less server computing for a scene than a centralized approach. Instead of sending the raw data, our approach requires users to send a 3D representation, distributing the high computation cost of training centralized NeRFs between the users. It learns photorealistic scene representations by decomposing users' 3D views into personal and global NeRFs and a novel optimally weighted aggregation of only the latter. We validate the advantage of our approach to learn NeRFs with photorealism and minimal server computation cost on structured synthetic and real-world photo tourism datasets. We further analyze how secure aggregation of global NeRFs in DecentNeRF minimizes the undesired reconstruction of personal content by the server.
Generalizable and Stable Finetuning of Pretrained Language Models on Low-Resource Texts
Mar 19, 2024Pretrained Language Models (PLMs) have advanced Natural Language Processing (NLP) tasks significantly, but finetuning PLMs on low-resource datasets poses significant challenges such as instability and overfitting. Previous methods tackle these issues by finetuning a strategically chosen subnetwork on a downstream task, while keeping the remaining weights fixed to the pretrained weights. However, they rely on a suboptimal criteria for sub-network selection, leading to suboptimal solutions. To address these limitations, we propose a regularization method based on attention-guided weight mixup for finetuning PLMs. Our approach represents each network weight as a mixup of task-specific weight and pretrained weight, controlled by a learnable attention parameter, providing finer control over sub-network selection. Furthermore, we employ a bi-level optimization (BLO) based framework on two separate splits of the training dataset, improving generalization and combating overfitting. We validate the efficacy of our proposed method through extensive experiments, demonstrating its superiority over previous methods, particularly in the context of finetuning PLMs on low-resource datasets.
CoDream: Exchanging dreams instead of models for federated aggregation with heterogeneous models
Feb 27, 2024Federated Learning (FL) enables collaborative optimization of machine learning models across decentralized data by aggregating model parameters. Our approach extends this concept by aggregating "knowledge" derived from models, instead of model parameters. We present a novel framework called CoDream, where clients collaboratively optimize randomly initialized data using federated optimization in the input data space, similar to how randomly initialized model parameters are optimized in FL. Our key insight is that jointly optimizing this data can effectively capture the properties of the global data distribution. Sharing knowledge in data space offers numerous benefits: (1) model-agnostic collaborative learning, i.e., different clients can have different model architectures; (2) communication that is independent of the model size, eliminating scalability concerns with model parameters; (3) compatibility with secure aggregation, thus preserving the privacy benefits of federated learning; (4) allowing of adaptive optimization of knowledge shared for personalized learning. We empirically validate CoDream on standard FL tasks, demonstrating competitive performance despite not sharing model parameters. Our code: https://mitmedialab.github.io/codream.github.io/
EIGEN: Expert-Informed Joint Learning Aggregation for High-Fidelity Information Extraction from Document Images
Nov 23, 2023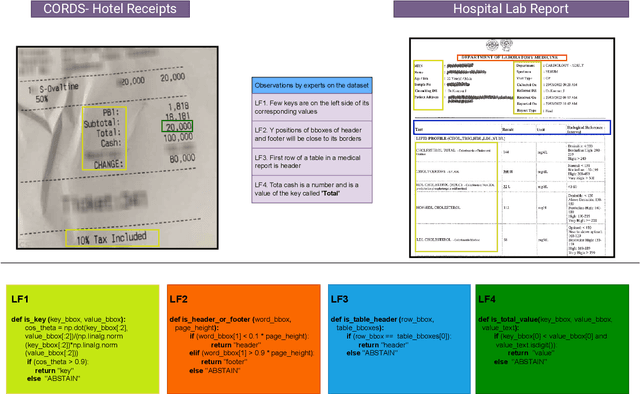



Information Extraction (IE) from document images is challenging due to the high variability of layout formats. Deep models such as LayoutLM and BROS have been proposed to address this problem and have shown promising results. However, they still require a large amount of field-level annotations for training these models. Other approaches using rule-based methods have also been proposed based on the understanding of the layout and semantics of a form such as geometric position, or type of the fields, etc. In this work, we propose a novel approach, EIGEN (Expert-Informed Joint Learning aGgrEatioN), which combines rule-based methods with deep learning models using data programming approaches to circumvent the requirement of annotation of large amounts of training data. Specifically, EIGEN consolidates weak labels induced from multiple heuristics through generative models and use them along with a small number of annotated labels to jointly train a deep model. In our framework, we propose the use of labeling functions that include incorporating contextual information thus capturing the visual and language context of a word for accurate categorization. We empirically show that our EIGEN framework can significantly improve the performance of state-of-the-art deep models with the availability of very few labeled data instances. The source code is available at https://github.com/ayushayush591/EIGEN-High-Fidelity-Extraction-Document-Images.
Scalable Collaborative Learning via Representation Sharing
Dec 13, 2022Privacy-preserving machine learning has become a key conundrum for multi-party artificial intelligence. Federated learning (FL) and Split Learning (SL) are two frameworks that enable collaborative learning while keeping the data private (on device). In FL, each data holder trains a model locally and releases it to a central server for aggregation. In SL, the clients must release individual cut-layer activations (smashed data) to the server and wait for its response (during both inference and back propagation). While relevant in several settings, both of these schemes have a high communication cost, rely on server-level computation algorithms and do not allow for tunable levels of collaboration. In this work, we present a novel approach for privacy-preserving machine learning, where the clients collaborate via online knowledge distillation using a contrastive loss (contrastive w.r.t. the labels). The goal is to ensure that the participants learn similar features on similar classes without sharing their input data. To do so, each client releases averaged last hidden layer activations of similar labels to a central server that only acts as a relay (i.e., is not involved in the training or aggregation of the models). Then, the clients download these last layer activations (feature representations) of the ensemble of users and distill their knowledge in their personal model using a contrastive objective. For cross-device applications (i.e., small local datasets and limited computational capacity), this approach increases the utility of the models compared to independent learning and other federated knowledge distillation (FD) schemes, is communication efficient and is scalable with the number of clients. We prove theoretically that our framework is well-posed, and we benchmark its performance against standard FD and FL on various datasets using different model architectures.